利用ANTLR4实现一个简单的四则运算计算器
ANTLR4介绍
ANTLR能够自动地帮助你完成词法分析和语法分析的工作, 免去了手写去写词法分析器和语法分析器的麻烦
它是基于LL(k)的, 以递归下降的方式进行工作.ANTLR v4还支持多种目标语言。本文用java来写代码。
总结一下:ANTRL能自动完成语法分析和词法分析过程,并生产框架代码,让我们写相关过程的时候只需要往固定位置添加代码即可。大大简便了语法分析词法分析的过程。
ANTLR4安装配置
因为用IDEA,所以直接介绍在IDEA中怎么安装,在IDEA中安装ANTLR4相关插件即可。然后MAVEN引用下
```
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4</artifactId>
<version>4.5.2</version>
</dependency>
```
ANTLR4 语法描述文件
ANTLR4有专门的语法来构建整个过程
grammar Expr;
prog : stat+;
stat: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
MUL : '*' ; // assigns token name to '*' used above in grammar
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ;
INT : [0-9]+ ;
NEWLINE:'
'? '
' ;
WS : [ ]+ -> skip;
相关语法很简单, 整体来说一个原则,递归下降。 即定义一个表达式(如expr),可以循环调用直接也可以调用其他表达式,但是最终肯定会有一个最核心的表达式不能再继续往下调用了。
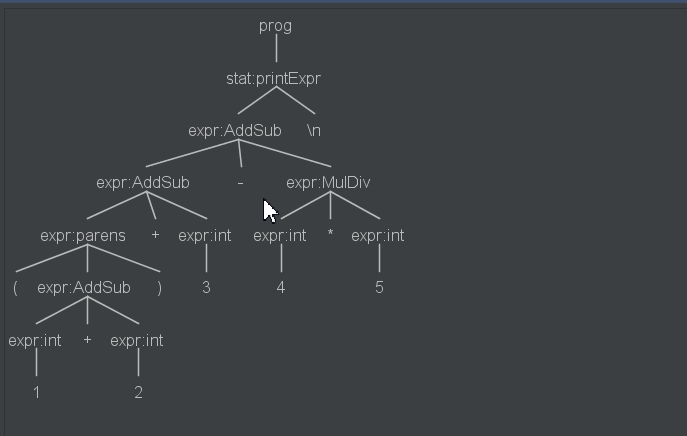
以上代码在真正执行的时候会生成一棵抽象语法树,选择“prog”然后->"Test Rule prog", 输入测试数据“(1 + 2)+3-4*5”,然后我们会就可以看到一棵语法树了。
相关生成的java代码
整个语法文件的目的是为了让antlr生产相关的java代码。 我们先设置下生成visitor, 然后,他会生成如下几个文件:
- ExprParser
- ExprLexer
- ExprBaseVistor
- ExprVisitor
ExprLexer 是词法分析器, ExprParser是语法分析器。 一个语言的解析过程一般过程是 词法分析-->语法分析。这是ANTLR4为我们生成的框架代码, 而我们唯一要做的是自己实现一个Vistor,一般从ExprBaseVistor继承即可。
ANTLR 会为ExprBaseVistor 从定义的symoble文件如“#printExpr, #assign” ,自动生成相应的还是,然后就实现这些还是就可以实现我们的功能了。 如:
@Override
public Integer visitAssign(ExprParser.AssignContext ctx) {
String id = ctx.ID().getText();
Integer value = visit(ctx.expr());
this.memory.put(id, value);
return value;
}
@Override
public Integer visitInt(ExprParser.IntContext ctx) {
return Integer.valueOf(ctx.INT().getText());
}
@Override
public Integer visitMulDiv(ExprParser.MulDivContext ctx) {
Integer left = visit(ctx.expr(0));
Integer right = visit(ctx.expr(1));
if (ctx.op.getType() == ExprParser.MUL){
return left * right;
}else{
return left / right;
}
}
解释下Context的应用, Context 可以通过 expr(i) 取上下文的子内容。
然后就可以用如下方式是使用了:
public static void main(String [] args) throws IOException {
ANTLRInputStream inputStream = new ANTLRInputStream("1 + 2 + 3 * 4+ 6 / 2");
ExprLexer lexer = new ExprLexer(inputStream);
CommonTokenStream tokenStream = new CommonTokenStream(lexer);
ExprParser parser = new ExprParser(tokenStream);
ParseTree parseTree = parser.prog();
EvalVisitor visitor = new EvalVisitor();
Integer rtn = visitor.visit(parseTree);
System.out.println("#result#"+rtn.toString());
}
运行一下,可以得到正确的结果了。
分析下整个过程
好神奇。 我们来分析下整个过程是如何实现的。
首先Antlr4会根据相关的语法文件生成ExprParser类,其内容是由 其语法内容决定的。如上的语法中有三个表达式:prog,stat,expr,所以就生成了三个函数:
public final ProgContext prog() throws RecognitionException {
ProgContext _localctx = new ProgContext(_ctx, getState());
enterRule(_localctx, 0, RULE_prog);
try {
enterOuterAlt(_localctx, 1);
{
setState(6);
stat();
}
}
catch (RecognitionException re) {
_localctx.exception = re;
_errHandler.reportError(this, re);
_errHandler.recover(this, re);
}
finally {
exitRule();
}
return _localctx;
}
public final StatContext stat() throws RecognitionException {
StatContext _localctx = new StatContext(_ctx, getState());
enterRule(_localctx, 2, RULE_stat);
...
stat过程是真正的语法分析过程, 他会把相应的token填上不同的StatContext.
整个语法解析的过程就是 prop -> stat ->expr。
在语法文件中有MUL,DIV 等几个关键字, Antlr会自动识别其是否有子项调用如果没有则这样定义:
public static final int
T__0=1, T__1=2, T__2=3, MUL=4, DIV=5, ADD=6, SUB=7, ID=8, INT=9, NEWLINE=10,
WS=11;
public static final int
RULE_prog = 0, RULE_stat = 1, RULE_expr = 2;
有了parser, 下一个疑问就是parser如何和我们写的visitor联系起来的。 这就要借助于一个非常重要的概念:Context.
因为语法文件中有8个symbol ,所以会对于生成不同的Context.
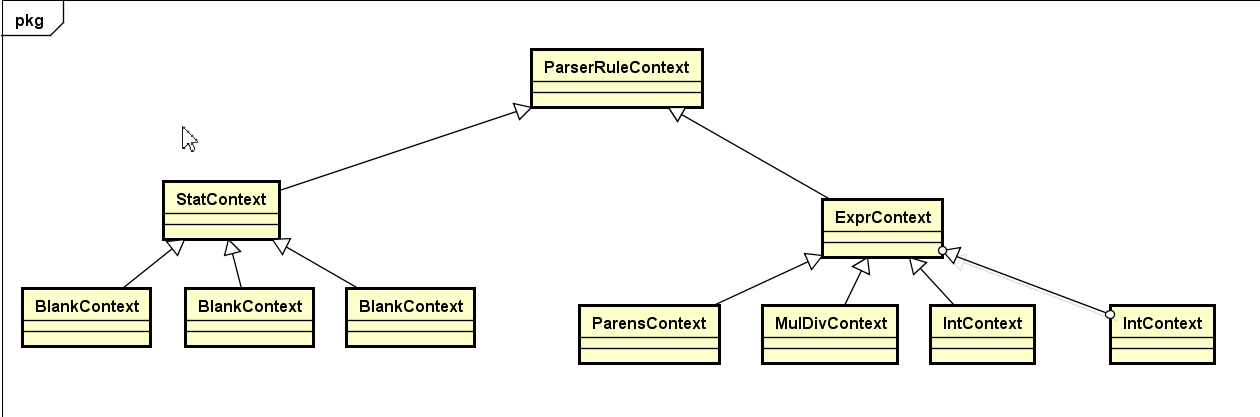
最终返回出去:
ParseTree parseTree = parser.prog();
EvalVisitor visitor = new EvalVisitor();
Integer rtn = visitor.visit(parseTree);
一个典型的Context是这样实现的:
public static class IntContext extends ExprContext {
public TerminalNode INT() { return getToken(ExprParser.INT, 0); }
public IntContext(ExprContext ctx) { copyFrom(ctx); }
@Override
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof ExprVisitor ) return ((ExprVisitor<? extends T>)visitor).visitInt(this);
else return visitor.visitChildren(this);
}
}
特别关注 accept 的实现。
看下 visitor的实现
public T visit(ParseTree tree) {
return tree.accept(this);
}
典型的visitor模式的实现。 以上这个流程是:
- 通过parser返回一个xxContext的树
- 在visitor中调用 xxContent的accept方法
- xxContext 调用visitor的具体实现方法: 如:visitMulDiv
- 在实现vistor方法时候,注意如果还有chilContent,继续往下。
总结
Antlr4 屏蔽了语法分析和词法分析的细节。大大简化了开发的工作量。 而且使用简单方便。对比 Boost.Spirit,简直一个是自动挡的汽车,一个是飞机。