问题描述
强迫症发作
对齐结果

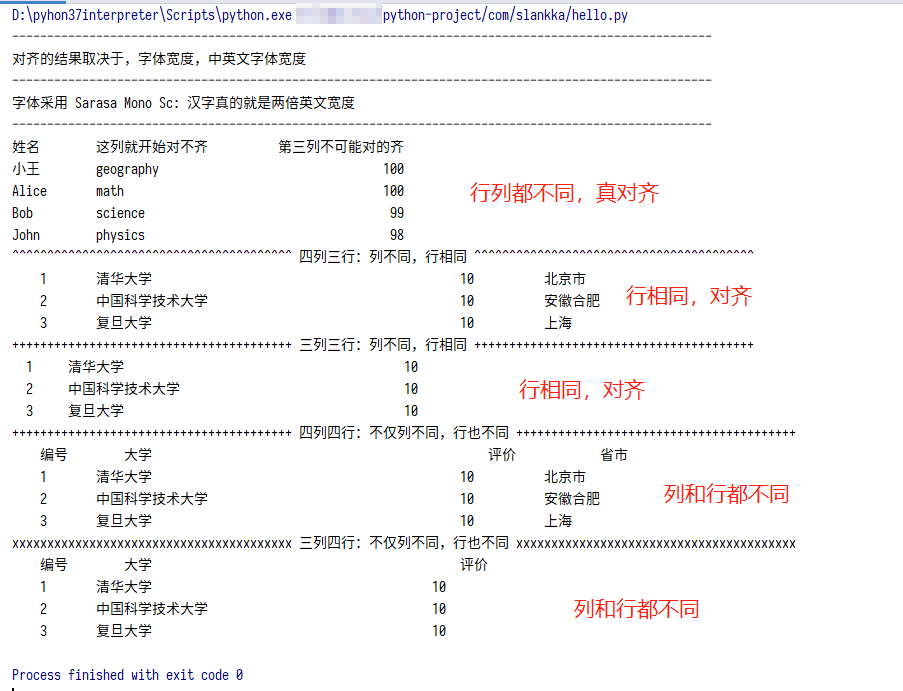
成绩单对齐
# 汉字占两英文宽,则每存在一个汉字少填充一个长度
def pad_len(string, length):
return length - len(string.encode('GBK')) + len(string)
...
print("{0:<{len1}} {1:<{len2}} {2:>{len3}}".format(*line, len1=pad_len(line[0], 8), len2=pad_len(line[1], 20), len3=pad_len(line[2], 20)))
大学列表对齐
看起来是对齐的,在中英文字体宽度不是2倍宽度的情况下,但是format具有不确定性:
ulist = []
ulist.append([1, "清华大学", "10", "北京市"])
ulist.append([2, "中国科学技术大学", "10", "安徽合肥"])
ulist.append([3, "复旦大学", "10", "上海"])
print('^' * 40, '四列三行:列不同,行相同', '^' * 40)
for ul in ulist:
print("{0:{4}^6} {1:{4}<20} {2:{4}^10} {3:{4}<10}".format(*ul, chr(12288)))
print('+' * 40, '三列三行:列不同,行相同', '+' * 40)
for ul in ulist:
print("{0:^6} {1:{4}<20} {2:^10}".format(*ul, chr(12288)))
ulist.insert(0, ['编号', '大学', '评价', '省市'])
print('+' * 40, '四列四行:不仅列不同,行也不同', '+' * 40)
for ul in ulist:
print("{0:{4}^6} {1:{4}<20} {2:{4}^10} {3:<10}".format(*ul, chr(12288)))
print('x' * 40, '三列四行:不仅列不同,行也不同', 'x' * 40)
for ul in ulist:
print("{0:{4}^6} {1:{4}<20} {2:^10}".format(*ul, chr(12288)))
注意,行数相同(且每一列的字符行都和上一行的字符编码长度一样,前提条件),三列的时候和四列的情况还不一样,四列多一个 chr(12288)的填充字符。中英文混排列,总共N个列,也就是 N-1个列都需要chr(12288)。
列数相同(非前提条件,仅排除干扰因素),三行和四行(四行的第一行和第二行的字符编码长度不一样),所需要的 chr(12288)的填充字符 也不一样,少一个就不能对齐。
结论
结论一:在中英文长度倍数不确定的等宽字体下,能否对齐是不确定的,具体表现在:需要尝试加填充字符,且个数随着行列变化。
结论二:在中英文长度倍数确定为2的等宽字体下,能否对齐是确定的,具体表现在:无需设置填充字符,且可以统一计算长度。
结论三:面向字体编程,等宽字体对齐还靠运气。
本文例子参考了 他的博客