在hadoop1.0版本以前我们的Mapreduce是被当作资源调度和计算框架来使用的,成为了hadoop运行生态圈的瓶颈,所以在hadoop2.0版本以上引入了yarn的概念,使Mapreduce完全成为分布式计算框架,而Yarn成为了分布式资源调度。虽然mapreduce处理速度很慢,IO操作会很多,不过这是我们步入Spark的必经之路,也是了解大数据生态圈不可缺少的成分。
下面就是针对job提交,yarn所做出的反应。
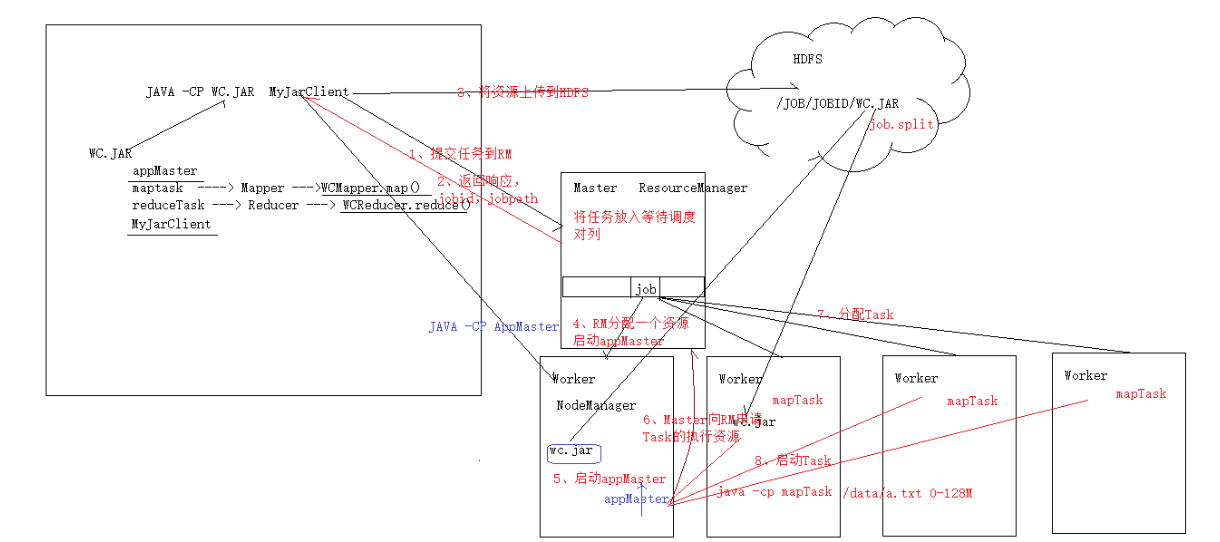
(我们的jar包中包括了许许多多的信息,其中重要的是:Mapper、Reducer、ApplicationMaster)
1.将job提交给ResourcemManager(后面用RM代替),RM会给他分配一个jobID
2.RM会给客户端返回一个JobID和路径的信息
3.客户端根据这个信息,将jar包存储在HDFS中
4.提交job给RM,RM中存在FIFO机制,如果前面有正在运行的Job,则放入FIFO进行等待,直到轮到此Job
5.申请开启AM(ApplicationMaster),RM会找到一个NM(NodeManager)给他continer,用来启动AM,ND开启AM(其实5和6之间存在一种AM向RM注册的行为,这里不做太多讲解,只需懂基本流程即可)
6. AM向RM申请Task的执行资源,用来运行Task
7.RM根据AM的信息和每个节点的资源利用情况进行Task的资源分配
8.AM去每个Task所在的节点上通知NM去开启此continer
(后续一点步骤:
9.task启动会跟AM进行注册,AM时刻监控Task的运行情况,知道收到Task运行完成为止)
以上便是Mapreduce的job提交流程。