Linux aio是Linux下的异步读写模型。Linux 异步 I/O 是 Linux 内核中提供的一个相当新的增强。它是 2.6 版本内核的一个标准特性。对于文件的读写,即使以O_NONBLOCK方式来打开一个文件,也会处于"阻塞"状态。因为文件时时刻刻处于可读状态。而从磁盘到内存所等待的时间是惊人的。为了充份发挥把数据从磁盘复制到内存的时间,引入了aio模型。AIO 背后的基本思想是允许进程发起很多 I/O 操作,而不用阻塞或等待任何操作完成。稍后或在接收到 I/O 操作完成的通知时,进程就可以检索 I/O 操作的结果。
I/O 模型
在深入介绍 AIO API 之前,让我们先来探索一下 Linux 上可以使用的不同 I/O 模型。这并不是一个详尽的介绍,但是我们将试图介绍最常用的一些模型来解释它们与异步 I/O 之间的区别。图 1 给出了同步和异步模型,以及阻塞和非阻塞的模型。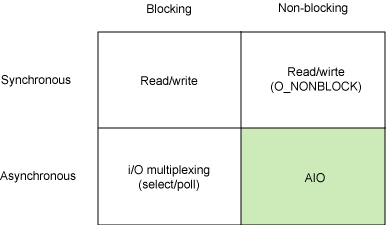
图 1. 基本 Linux I/O 模型的简单矩阵
每个 I/O 模型都有自己的使用模式,它们对于特定的应用程序都有自己的优点。本节将简要对其一一进行介绍。
同步阻塞 I/O
最常用的一个模型是同步阻塞 I/O 模型。在这个模型中,用户空间的应用程序执行一个系统调用,这会导致应用程序阻塞。这意味着应用程序会一直阻塞,直到系统调用完成为止(数据传输完成或发生错误)。调用应用程序处于一种不再消费 CPU 而只是简单等待响应的状态,因此从处理的角度来看,这是非常有效的。
图 2 给出了传统的阻塞 I/O 模型,这也是目前应用程序中最为常用的一种模型。其行为非常容易理解,其用法对于典型的应用程序来说都非常有效。在调用 read 系统调用时,应用程序会阻塞并对内核进行上下文切换。然后会触发读操作,当响应返回时(从我们正在从中读取的设备中返回),数据就被移动到用户空间的缓冲区中。然后应用程序就会解除阻塞(read 调用返回)。
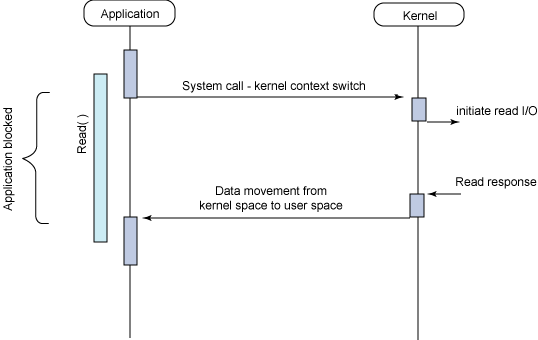
图 2. 同步阻塞 I/O 模型的典型流程
从应用程序的角度来说,read 调用会延续很长时间。实际上,在内核执行读操作和其他工作时,应用程序的确会被阻塞。
同步非阻塞 I/O
同步阻塞 I/O 的一种效率稍低的变种是同步非阻塞 I/O。在这种模型中,设备是以非阻塞的形式打开的。这意味着 I/O 操作不会立即完成,read 操作可能会返回一个错误代码,说明这个命令不能立即满足(EAGAIN 或 EWOULDBLOCK),如图 3 所示。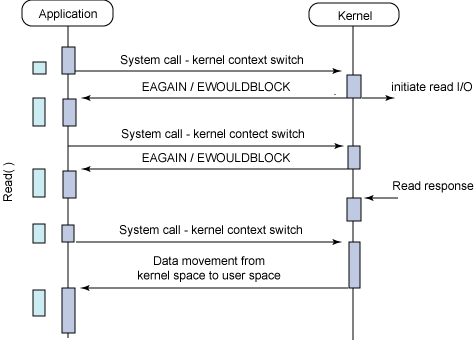
图 3. 同步非阻塞 I/O 模型的典型流程
非阻塞的实现是 I/O 命令可能并不会立即满足,需要应用程序调用许多次来等待操作完成。这可能效率不高,因为在很多情况下,当内核执行这个命令时,应用程序必须要进行忙碌等待,直到数据可用为止,或者试图执行其他工作。正如图 3 所示的一样,这个方法可以引入 I/O 操作的延时,因为数据在内核中变为可用到用户调用 read 返回数据之间存在一定的间隔,这会导致整体数据吞吐量的降低。
异步阻塞 I/O
另外一个阻塞解决方案是带有阻塞通知的非阻塞 I/O。在这种模型中,配置的是非阻塞 I/O,然后使用阻塞 select 系统调用来确定一个 I/O 描述符何时有操作。使 select 调用非常有趣的是它可以用来为多个描述符提供通知,而不仅仅为一个描述符提供通知。对于每个提示符来说,我们可以请求这个描述符可以写数据、有读数据可用以及是否发生错误的通知。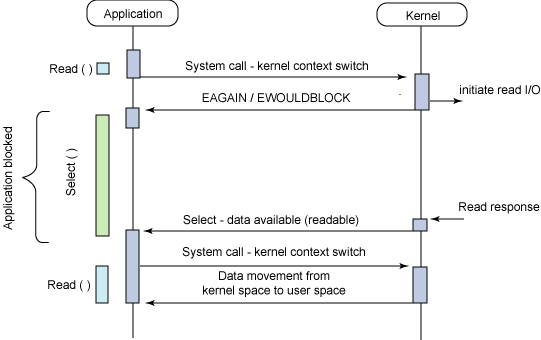
图 4. 异步阻塞 I/O 模型的典型流程 (select)
select 调用的主要问题是它的效率不是非常高。尽管这是异步通知使用的一种方便模型,但是对于高性能的 I/O 操作来说不建议使用。
异步非阻塞 I/O(AIO)
最后,异步非阻塞 I/O 模型是一种处理与 I/O 重叠进行的模型。读请求会立即返回,说明 read 请求已经成功发起了。在后台完成读操作时,应用程序然后会执行其他处理操作。当 read 的响应到达时,就会产生一个信号或执行一个基于线程的回调函数来完成这次 I/O 处理过程。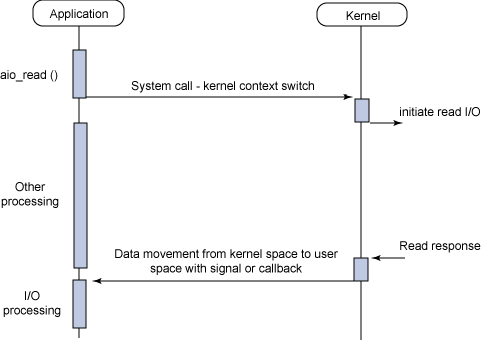
图 5. 异步非阻塞 I/O 模型的典型流程
在一个进程中为了执行多个 I/O 请求而对计算操作和 I/O 处理进行重叠处理的能力利用了处理速度与 I/O 速度之间的差异。当一个或多个 I/O 请求挂起时,CPU 可以执行其他任务;或者更为常见的是,在发起其他 I/O 的同时对已经完成的 I/O 进行操作。
从前面 I/O 模型的分类中,我们可以看出 AIO 的动机。这种阻塞模型需要在 I/O 操作开始时阻塞应用程序。这意味着不可能同时重叠进行处理和 I/O 操作。同步非阻塞模型允许处理和 I/O 操作重叠进行,但是这需要应用程序根据重现的规则来检查 I/O 操作的状态。这样就剩下异步非阻塞 I/O 了,它允许处理和 I/O 操作重叠进行,包括 I/O 操作完成的通知。除了需要阻塞之外,select 函数所提供的功能(异步阻塞 I/O)与 AIO 类似。不过,它是对通知事件进行阻塞,而不是对 I/O 调用进行阻塞。
Linux 上的 AIO 简介
linux下有aio封装,aio_*系列的调用是glibc提供的,是glibc用线程+阻塞调用来模拟的,性能很差,为了能更多的控制io行为,可以使用更为低级libaio。
libaio项目: http://oss.oracle.com/projects/libaio-oracle/
libaio的使用并不复杂,过程为:libaio的初始化,io请求的下发和回收,libaio销毁。
一、libaio接口
libaio提供下面五个主要API函数:
int io_setup(int maxevents, io_context_t *ctxp);
int io_destroy(io_context_t ctx);
int io_submit(io_context_t ctx, long nr, struct iocb *ios[]);
int io_cancel(io_context_t ctx, struct iocb *iocb, struct io_event *evt);
int io_getevents(io_context_t ctx_id, long min_nr, long nr, struct io_event *events, struct timespec *timeout);
五个宏定义:
void io_set_callback(struct iocb *iocb, io_callback_t cb);
void io_prep_pwrite(struct iocb *iocb, int fd, void *buf, size_t count, long long offset);
void io_prep_pread(struct iocb *iocb, int fd, void *buf, size_t count, long long offset);
void io_prep_pwritev(struct iocb *iocb, int fd, const struct iovec *iov, int iovcnt, long long offset);
void io_prep_preadv(struct iocb *iocb, int fd, const struct iovec *iov, int iovcnt, long long offset);
这五个宏定义都是操作struct iocb的结构体。struct iocb是libaio中很重要的一个结构体,用于表示IO,但是其结构略显复杂,为了保持封装性不建议直接操作其元素而用上面五个宏定义操作。
二、libaio的初始化和销毁
观察libaio五个主要API,都用到类型为io_context的变量,这个变量为libaio的工作空间。不用具体去了解这个变量的结构,只需要了解其相关操作。创建和销毁libaio分别用到io_setup(也可以用io_queue_init,区别只是名字不一样而已)和io_destroy。
int io_setup(int maxevents, io_context_t *ctxp);
int io_destroy(io_context_t ctx);
三、libaio读写请求的下发和回收
1. 请求下发
libaio的读写请求都用io_submit下发。下发前通过io_prep_pwrite和io_prep_pread生成iocb的结构体,做为io_submit的参数。这个结构体中指定了读写类型、起始扇区、长度和设备标志符。
libaio的初始化不是针对一个具体设备进行初始,而是创建一个libaio的工作环境。读写请求下发到哪个设备是通过open函数打开的设备标志符指定。
2. 请求返回
读写请求下发之后,使用io_getevents函数等待io结束信号:
int io_getevents(io_context_t ctx_id, long min_nr, long nr, struct io_event *events, struct timespec *timeout);
io_getevents返回events的数组,其参数events为数组首地址,nr为数组长度(即最大返回的event数),min_nr为最少返回的events数。timeout可填NULL表示无等待超时。io_event结构体的声明为:
struct io_event {
PADDEDptr(void *data, __pad1);
PADDEDptr(struct iocb *obj, __pad2);
PADDEDul(res, __pad3);
PADDEDul(res2, __pad4);
};
其中,res为实际完成的字节数;res2为读写成功状态,0表示成功;obj为之前下发的struct iocb结构体。这里有必要了解一下struct iocb这个结构体的主要内容:
iocbp->iocb.u.c.nbytes 字节数
iocbp->iocb.u.c.offset 偏移
iocbp->iocb.u.c.buf 缓冲空间
iocbp->iocb.u.c.flags 读写
3. 自定义字段
struct iocb除了自带的元素外,还留有供用户自定义的元素,包括回调函数和void *的data指针。如果在请求下发前用io_set_callback绑定用户自定义的回调函数,那么请求返回后就可以显示的调用该函数。回调函数的类型为:
void callback_function(io_context_t ctx, struct iocb *iocb, long res, long res2);
另外,还可以通过iocbp->data指针挂上用户自己的数据。
注意:实际使用中发现回调函数和data指针不能同时用,可能回调函数本身就是使用的data指针。
四、使用例子
通过上面的说明并不能完整的了解libaio的用法,下面通过简单的例子进一步说明。
#include <stdlib.h>
#include <stdio.h>
#include <libaio.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <libaio.h>
int srcfd=-1;
int odsfd=-1;
#define AIO_BLKSIZE 1024
#define AIO_MAXIO 64
static void wr_done(io_context_t ctx, struct iocb *iocb, long res, long res2)
{
if(res2 != 0)
{
printf(“aio write error
”);
}
if(res != iocb->u.c.nbytes)
{
printf( “write missed bytes expect %d got %d
”, iocb->u.c.nbytes, res);
exit(1);
}
free(iocb->u.c.buf);
free(iocb);
}
static void rd_done(io_context_t ctx, struct iocb *iocb, long res, long res2)
{
/*library needs accessors to look at iocb*/
int iosize = iocb->u.c.nbytes;
char *buf = (char *)iocb->u.c.buf;
off_t offset = iocb->u.c.offset;
int tmp;
char *wrbuff = NULL;
if(res2 != 0)
{
printf(“aio read
”);
}
if(res != iosize)
{
printf( “read missing bytes expect %d got %d”, iocb->u.c.nbytes, res);
exit(1);
}
/*turn read into write*/
tmp = posix_memalign((void **)&wrbuff, getpagesize(), AIO_BLKSIZE);
if(tmp < 0)
{
printf(“posix_memalign222
”);
exit(1);
}
snprintf(wrbuff, iosize + 1, “%s”, buf);
printf(“wrbuff-len = %d:%s
”, strlen(wrbuff), wrbuff);
printf(“wrbuff_len = %d
”, strlen(wrbuff));
free(buf);
io_prep_pwrite(iocb, odsfd, wrbuff, iosize, offset);
io_set_callback(iocb, wr_done);
if(1!= (res=io_submit(ctx, 1, &iocb)))
printf(“io_submit write error
”);
printf(“
submit %d write request
”, res);
}
void main(int args,void * argv[])
{
int length = sizeof(“abcdefg”);
char * content = (char * )malloc(length);
io_context_t myctx;
int rc;
char * buff=NULL;
int offset=0;
int num,i,tmp;
if(args<3)
{
printf(“the number of param is wrong
”);
exit(1);
}
if((srcfd=open(argv[1],O_RDWR))<0)
{
printf(“open srcfile error
”);
exit(1);
}
printf(“srcfd=%d
”,srcfd);
lseek(srcfd,0,SEEK_SET);
write(srcfd,”abcdefg”,length);
lseek(srcfd,0,SEEK_SET);
read(srcfd,content,length);
printf(“write in the srcfile successful,content is %s
”,content);
if((odsfd=open(argv[2],O_RDWR))<0)
{
close(srcfd);
printf(“open odsfile error
”);
exit(1);
}
memset(&myctx, 0, sizeof(myctx));
io_queue_init(AIO_MAXIO, &myctx);
struct iocb *io = (struct iocb*)malloc(sizeof(struct iocb));
int iosize = AIO_BLKSIZE;
tmp = posix_memalign((void **)&buff, getpagesize(), AIO_BLKSIZE);
if(tmp < 0)
{
printf(“posix_memalign error
”);
exit(1);
}
if(NULL == io)
{
printf( “io out of memeory
”);
exit(1);
}
io_prep_pread(io, srcfd, buff, iosize, offset);
io_set_callback(io, rd_done);
printf(“START…
”);
rc = io_submit(myctx, 1, &io);
if(rc < 0)
printf(“io_submit read error
”);
printf(“
submit %d read request
”, rc);
//m_io_queue_run(myctx);
struct io_event events[AIO_MAXIO];
io_callback_t cb;
num = io_getevents(myctx, 1, AIO_MAXIO, events, NULL);
printf(“
%d io_request completed
”, num);
for(i=0;i<num;i++)
{
cb = (io_callback_t)events[i].data;
struct iocb *io = events[i].obj;
printf(“events[%d].data = %x, res = %d, res2 = %d
”, i, cb, events[i].res, events[i].res2);
cb(myctx, io, events[i].res, events[i].res2);
}
}