机器学习常见算法:
K最近邻算法,线性模型,朴素贝叶斯,决策树,随机森林,SVMs,神经网络等
要注意关心如下问题:
要了解每种算法的基本原理和用途,它的特性分别是什么?在不同的数据集中表现如何,如何使用它们建模,模型的参数如何调整等
kaggle大赛,使用来自真实世界的数据磨炼自己的技能
必要库的介绍:
- Numpy: 基础科学计算库。功能包括高维数组、线代计算,傅里叶变换以及生产伪随机数等等。是scikit-learn的基础
- Scipy: 强大的科学计算工具集,sk需要使用scipy里面的sparse函数生成稀疏矩阵
- pandas: 数据分析的利器
- scikit-learn----非常流行的机器学习库,建立在Scipy基础上
scikit-learn拥有众多顶级机器学习算法,主要有六大类:分类,回归,聚类,数据降维,模型选择和数据预处理
用户社区需要经常逛一下!!
2018-10-16 21:26:03
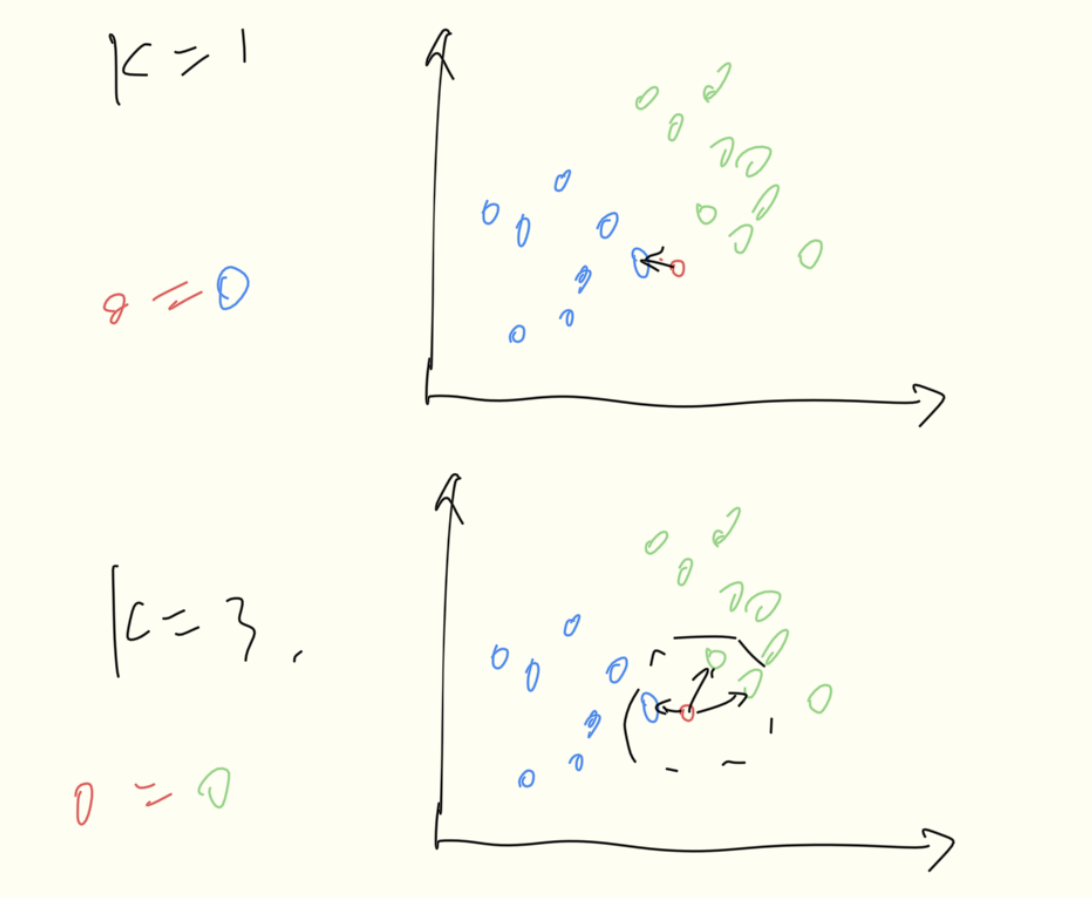
K近邻算法
K的含义:最近邻的个数。如下图,K的选取值为1,3时候,对于红o的的分类是不一样的
在scikit_learn 中,K值是通过n_neighbors参数来调节的