GPU通用计算发展势头迅猛
泡泡网显卡频道8月27日 现在的显卡市场,同质化已经严重到了什么地步呢?不仅仅是板卡厂商之间的显卡性能基本没区别,而且同价位的N卡和A卡在不同游戏中的表现也是难分胜负,让游戏玩家们难以抉择。

于是NVIDIA和AMD的竞争开始逐渐淡化游戏,而强调功能和应用,三屏、3D、PhysX、视频等开始大行其道。不过这些功能都难以量化,随着CUDA和Stream的飞速发展催生了OpenCL和DirectCompute通用计算标准,使得NVIDIA和AMD在另一条道路上展开了新的竞赛——并行计算。
近年来GPU已经在科学研究和超级计算领域取得突破性进展,随着数百万支持CUDA的GPU已经遍布全球计算机,软件开发人员、科学人士和研究人员正在利用CUDA探测到更多更广的领域中,包括图像和视频编辑、计算生物学和计算化学、流体力学模拟、CT图像重组、地震分析、光线追踪以及其它更多。近年来超级计算机的突飞猛进很大程度上也是得益于强大的GPU加盟。

对显卡感兴趣的朋友都知道,通用计算之所以如此热门,根本原因在于显卡核心GPU的多流处理器(相当于数百核心)架构:GPU强大的并行浮点运算能力是仅仅拥有个位数核心的中央处理器CPU无法望其项背的。而通用计算技术可以发挥GPU的长处,让其电脑运算速度飙升,一些应用程序的速度可以提高数倍甚至数十倍,让原来因为运算量巨大而不可完成的任务变得可行。
而在家用、办公电脑上,借助GPU加速的软件也越来越多,这些软件有的可以用来转码,有的可以用来增强图像、视频的画质,有的可以将2D电影转换成3D,有的还能智能归类和编辑照片……
跟以往的GPGPU概念不同的是,CUDA是一个完整的解决方案,包含了API、C编译器等,能够利用显卡核心的片内L1 Cache共享数据,使数据不必经过内存-显存的反复传输,shader之间甚至可以互相通信,对数据的存储也不再约束于以往GPGPU的纹理方式,存取更加灵活,可以充分利用stream out(流输出)特性,最典型的例子就是PhysX物理加速特效。PhysX最早是Aegia公司推出的硬件级物理加速技术,NVIDIA将其收购之后便通过CUDA环境将PhysX软件化,由显卡中的shader单元承担物理加速特效的运算。

对于Stream技术,AMD宣称可让显卡内数百个平行串流核心,为各种一般用途的应用带来加速的效果,打造各种优异的平台,并可大幅提升每瓦性能,而实现这一点的前提就依赖于AMD独特的流处理器单元设计。
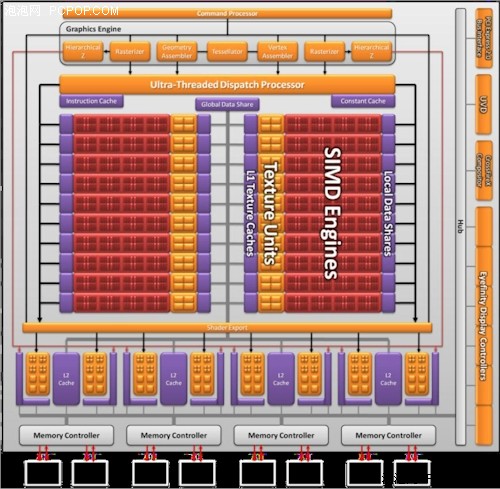
GF100的512个CUDA核心都符合IEEE 754-2008浮点算法(Cypress也是如此)和完整的32位整数算法,而后者在过去只是模拟的,事实上仅能计算24-bit整数乘法;同时全面引入的还有积和熔加运算(Fused Multiply-Add/FMA)。此外双精度浮点(FP64)性能大大提升,峰值执行率可以达到单精度浮点(FP32)的1/2,而过去只有1/8,AMD从R600开始到现在的Cypress核心都是1/5,没有做任何变化。
其实业界第一款GPU通用计算软件就是用户科学计算,它就是由斯坦福大学主导的Folding @ Home分布式计算,最早支持ATI显卡,而NVIDIA后来者居上,目前N卡所贡献的运算能力已经超越了所有CPU之和,A卡也不弱!

Folding@home是一个研究蛋白质折叠、误折、聚合及由此引起的相关疾病的分布式计算工程。最开始F@H仅支持CPU,后来加入了对PS3游戏机的支持,但同样是使用内置的CELL处理器做运算。F@H因ATI的加入为GPU计算翻开了新的一页,如今F@H第二代GPU客户端已经能够支持ATI和NVIDIA的全系列DX10 11 GPU

针对Fermi核心的平衡运算优势,《Folding@Home》最新版本GPU3,专为新一代Fermi系列显卡而设,进一步善用Fermi核心架构之优势。
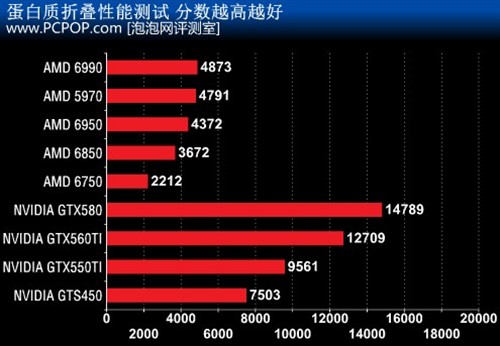
据官方介绍,新版的蛋白质折叠运算速度及稳定性已经大幅提高,而且加入更加科学计算项目,希望能籍Fermi核心的架构优势,加快《Folding@Home》内的各项复杂运算。Shader的频率对影响运算效能非常大,所以NVIDIA可以领先AMD很多。
遗失密码是一件令人相当烦恼的事,尤其因忘记工作文档密码所做造成的金钱损失更是十分“杯具”,如何快捷高效地找回密码是件难事。现行GPU的发展越来越强势,通用运行能力已经远超于CPU,而CPU的运行能力却是有限的,所以能够发挥出GPU强大的通用运算能力定必会大大缩短破解密码的时间。
GPU就是显示卡的“心脏”,也就相当于CPU在电脑中的作用,它决定了该显卡的档次和大部分性能外,还有着大规模的并行计算能力,可以让开发人员领先出引人入用的消费级和专业级的计算应用程序。无论是NVIDIA的CUDA或者是AMD的Stream运算,都是众多软件厂商所追捧的。

我们找来了Elcomsoft出品的ADVanced Office Password Recovery,是一款同时支持CPU与GPU的Office密码恢复软件。最多可支持32个CPU或内核和8个GPU同样运行,也可以指定全部或者是部分CPU/GPU核心进行恢复密码的工作。
测试中我们关闭所有CPU核心,完全由GPU独立工作来破解一个由6位数字加密的Word文件。
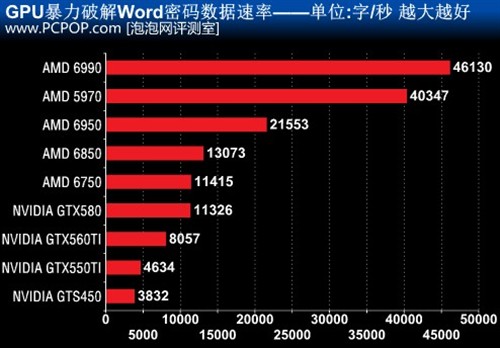
密码破解对于流处理器数量非常敏感。AMD的GPU由于SIMD架构的庞大流处理器优势遥遥领先于NVIDIA GPU。
Cyberlink(讯连科技)旗下大名鼎鼎PowerDVD相信大家都非常熟悉,作为一家专注视频与多媒体的软件开发商,Cyberlink不久前推出了一款专业的快速视频转换软件——MediaShow Espresso,需要注意的是MediaShow(魅力四射)是一款视频编辑软件,而MediaShow Espresso才是视频转换软件。

现在编码解码软件满天飞,但是MediaShow Espresso却有它的独到之处。它是第一款同时支持CUDA与Stream加速的视频转换软件,除此之外它还对Intel Core i7处理器的超线程及SSE4指令集做了优化,因此无论纯CPU转码还是GPU加速,其速度比传统软件都要快。
测试视频文件为长度为3分42秒码率22M的H.264编码的M2TS文件。测试中我们打开GPU解码与GPU编码选项,将编解码工作交由GPU来完成。
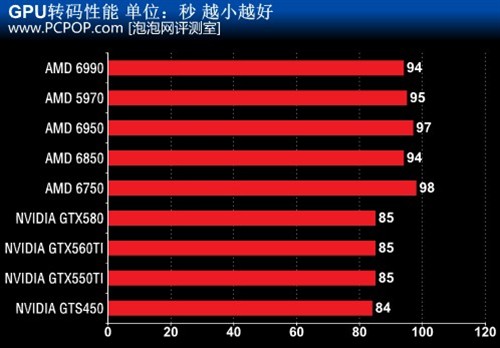
可以看出,GPU视频转码时,CPU和GPU都要参加计算,而且GPU不需要尽全力,所以高端GPU和中端GPU的性能是差不多的。总体来看N卡的CUDA性能要优于A卡的Stream性能。
值得注意的是,本次测试使用的是同时支持CUDA和Stream的MediaShow Espresso进行测试,如果使用仅支持CUDA的MediaCoder软件的话,N卡的视频转码速度还能更快,这方面A卡无论性能还是软件支持度都不如N卡。
ComputeMark由捷克硬件和游戏网站CzechGamer.com的Robert Varga开发制作,引擎是基于Jan Vlietinck的Fluid3D Demo。软件能够使显卡占用率达到99%,而CPU占用率仅0-1%,避免由CPU性能造成对测试成绩的影响。同时该软件还有功耗测量的功能,测试时间可以随意设定。
ComputeMark需要在纯DX11环境下运行,包括Windows 7 32/64位操作系统、DX11 API和DX11显卡。

最终结果很和谐,虽然A卡的理论浮点运算能力很高,但在DirectCompute理论测试当中,同级别的A卡并不比N卡高多少。因为DirectCompute现阶段主要还是在游戏当中使用,因此意义不是很大。
如果您还不了解比特币的话,不妨看看前不久我们的评测文章《挂机也能赚钱?教你用显卡挖矿赚美元》。这里就直接引用测试数据:
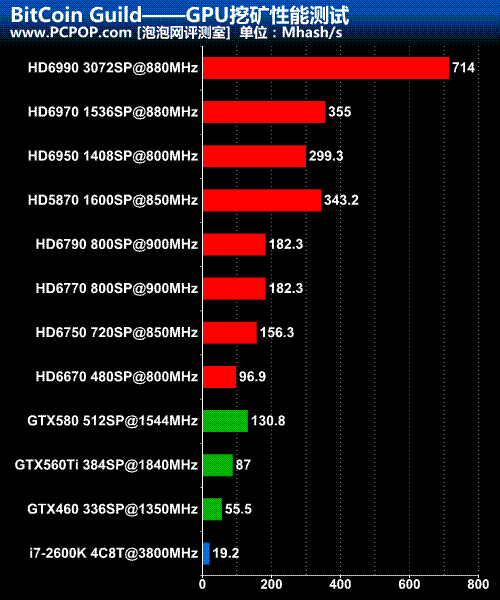
下面笔者做个简要分析:
1. HD6990拥有两颗GPU,核心频率与单核心的HD6970完全相同,所以挖矿性能正好翻倍。事实上HD6990就是需要开两个挖掘器分配给两颗GPU一起计算。
2. AMD上代HD5870流处理器稍多于HD6970,但核心频率稍低,最终两代旗舰单卡的挖矿性能差不多。要知道VLIW4架构的HD6970游戏性能要强于VLIW5架构的HD5870,但挖矿性能似乎只取决于理论浮点运算能力,跟架构和效率毫无关系。
3. Barts核心的HD6790拥有256Bit显存位宽,比128Bit的HD6770大一倍。但两者的挖矿性能完全相同,所以显存位宽频率对性能没有任何影响,影响性能的唯一因素就是流处理器数量及频率。
4. NV顶级单卡GTX580还不如HD6750,但要比CPU强很多,毕竟它也有数百颗核心。
那为什么A卡和N卡的差距如此之大呢?比特币挖掘器采用的是SHA-256,这是由美国国家安全局发明的一种安全散列函数,一般用于密码加密与解密。这种算法会进行大量32位整数循环右移运算,这个操作在AMD GPU那里可以通过单一硬件指令实现,而在NVIDIA GPU那里需要三次硬件指令来模拟(2移+1加),仅这一条就为AMD带来额外的1.7倍运算效率优势(大约1900指令来执行SHA-256压缩操作,而不是NVIDIA的大约3250指令)。
如此一来,AMD较高的浮点运算能力再加上算法效率优势,AMD GPU在密码破解与比特币挖掘时的性能,大概是NVIDIA GPU的3倍以上!
通过前面几项不同类型的通用计算应用来看,A卡和N卡之间的性能差距是相当大的,而且动不动就是几倍以上的差距。A卡恐怖的理论性能有时候确实有效果,但有时候还是要大幅落后于N卡,这与双方在3D游戏中和谐愉快的表现截然相反!
这种奇怪的现象,一方面是由双方截然不同的架构所造成的,另一方面是不同应用的算法不同,可能会比较“偏爱”某一种架构。最终,就要看谁在软件优化方面做得好,谁就能胜出。目前来看CUDA还是占有明显的上风,已经有很多超级计算机配备了NVIDIA Tesla加速卡,CUDA的应用软件还是要比Stream多很多的。

不管CUDA和Stream孰强孰弱,OpenCL和DirectCompute标准谁能笑到最后,GPU的地位显然在迅速攀升。超级计算机想要在性能上取得突破,使用GPU+CPU的异构架构是唯一选择,未来高性能计算已经离不开GPU的支持了。
NVIDIA和ATI从3D游戏战场打到了通用并行计算领域,到底谁能笑到最后现在还是个未知数。

对于普通用户来说,显卡已经不再是一块单纯的3D游戏加速卡,以视频应用为代表的高性能计算软件率先步入GPU通用计算的大门,未来将会有更多计算软件使用GPU强大的运算能力来加速,CPU和GPU的地位将变得同等重要。现在,玩家们因一两款特别喜爱的游戏而升级显卡;将来,或许很多不玩游戏的人,也会加入到独立显卡的行列!■
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow