一、题目
1、审题

2、分析
给定一个数组,记载了某研究人员的文章引用次数(每篇文章的引用次数都是非负整数),编写函数计算该研究人员的h指数。
根据维基百科上对h指数的定义:“一名科学家的h指数是指在其发表的N篇论文中,有h篇论文分别被引用了至少h次,其余N-h篇的引用次数均不超过h次”。
例如,给定一个数组citations = [3, 0, 6, 1, 5],这意味着该研究人员总共有5篇论文,每篇分别获得了3, 0, 6, 1, 5次引用。由于研究人员有3篇论文分别至少获得了3次引用,其余两篇的引用次数均不超过3次,因而其h指数是3。
注意:如果存在多个可能的h值,取最大值作为h指数。
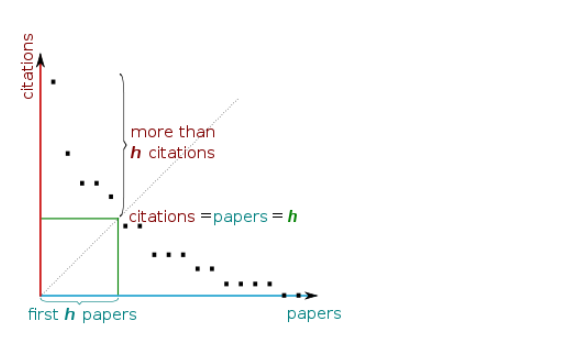
通过下图,可以更直观了解h值的定义,对应图中,即是球左下角正方形的最大值:
二、解答
1、思路
开辟一个新数组 arr,用于记录0~N次引用次数的各有几篇文章(引用次数大于N的按照N次计算)遍历数组,统计过后,遍历一次统计数组 arr,即可算出h值的最大值。时间复杂度为O(n)。
最终返回的是 count >= i 时的最大值 i 。
// 返回的 n,其中引用数 > n 的论文数要 >= n public int hIndex(int[] citations) { int len = citations.length; if(len == 0) return 0; int[] arr = new int[len + 1]; for (int i = 0; i < len; i++) { if(citations[i] >= len) arr[len]++; else arr[citations[i]]++; } int t = 0; for(int i = len; i >= 0; i--) { t += arr[i]; if(t >= i) return i; } return 0; }