首先,我建了一个表t2,里面有1000条数据,有id,a,b三个字段,a字段加了索引
然后我又建立一个t1表,里面有100条数据,和t2表的前一百条数据一致,也是只有id,a,b三个字段,a字段加了索引
如下图
然后我们看这条语句,为了不影响效果,这里我用了STRAIGHT_JOIN ,也就是在这条语句里会把t1当做驱动表
select * from t1 STRAIGHT_JOIN t2 on t1.a=t2.a
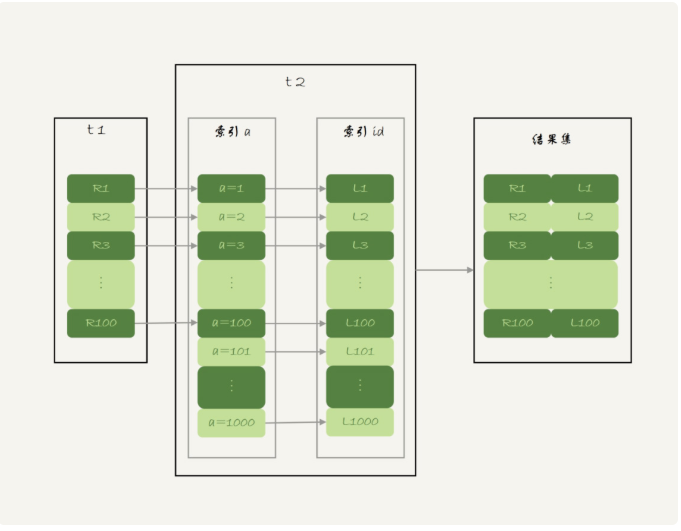
那么这条语句的执行流程就是这样的
1.从t1表查询出一行数据R
2.查出R这行数据的a字段的值到t2表中去查询
3.查询符合条件的数据和R组成一行,组装成结果集返回到客户端
4.重复执行步骤1-3,知道查到t1表的末尾
总结:由于我们在t2表上的a字段建立了索引,所以在第二步的时候不需要做全表扫描,也就是说,我们执行这条语句的扫描行数是200行,
首先t1表是扫描了100行,当和t2表每行去匹配的时候又扫描了t2表100行,所以这条语句总共扫描行数是200行,这种算法的扫描行数还是可以的。
对应的流程图如下图所示,这种算法叫作"Index Nested-Loop Join",简称NLJ
select * from t1 STRAIGHT_JOIN t2 on t1.a=t2.b
然后我们在看这条语句,由于b字段没有索引,所以在执行这条语句的时候,去t2表匹配的时候就要进行全表扫描
所以这条语句执行后的扫描行数就是100*1000=10万行
这个算法也有个名字叫做
Simple Nested-Loop Join
但是mysql没有使用这个算法,而是使用了另一种算法,叫做
Block Nested-Loop Join,简称BNL
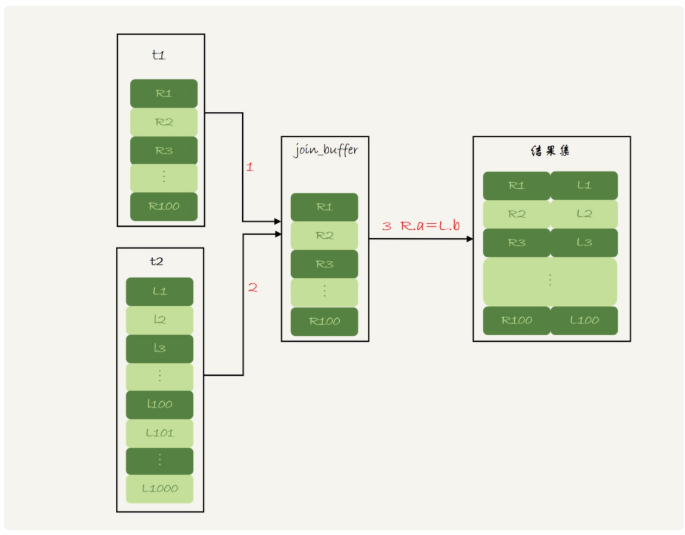
1.查询出t1的数据放入join_buffer中,由于这条语句是select *,因此是把整个表t1放入内存中
2.扫描表t2,将t2表的每一行数据和join_buffer中的数据进行匹配(全表扫描),符合条件的数据作为结果集的一部分返回
这里有个问题,如果join_buffer的大小不够存储t1表的数据怎么办呢?
其实也很简单,就是分成多部分查询放入join_buffer中
举个例子:
比如说join_buffer中只够存储50行数据,但是t1表有100行,那么就先查出t1表的50行数据放入join_buffer中,然后和t2表进行匹配
但是这样就带来了一个问题,也就是说我们要分两次放入join_buffer中,那么也就是说要对表t2进行两次全表扫描
这样扫描行数就是2200行了,不知道大家发现一个问题了没有,这个时候影响扫描行数的因素有哪些??
第一个因素就是这个join_buffer_size这个参数,如果他足够大,那么我们就只需要扫描表t2一次了,所以说有的时候我们发现了这个问题,
可以通过调大join_buffer_size这个参数来提高性能,当然不是说这个参数越大越好,要根据各方面情况来衡量。
第二个因素就是驱动表的大小,如果驱动表的数据小,那么要么不分段存入join_buffer中,那就只扫描了一次表t2,要么分段存入join_buffer中,这个时候,分段越少,那么扫描次数就越少
也就是说驱动表的数据越小越好
所以我们要使用小表来做驱动表,小表不是说某个表的真实的数据,而是说通过当前执行的语句中条件以及查询的字段而算出来的数据
例如
select t1.b,t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=100;
select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100;
在这个例子中表t1只查询出b字段放入join_buffer中
而表t2要把所有字段都放入join_buffer中,所以这个时候表t1是小表
这两种算法显然第一种算法也就是NLJ的性能要好,所以我们在写sql语句的时候要尽量让mysql使用这种算法
也就是要对连接的字段加上索引,如果该字段确实不适合加索引,没办法只能使用第二种算法,那么这个时候我们就要尽量使用小表来当做驱动表
了解更多:https://www.toutiao.com/c/user/83293539887/#mid=1633933053814798