本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练
python版本:3.7.1
框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visual studio一劳永逸,如果报错缺少前置依赖,就先安装依赖)
本篇主要对scrapy生成爬虫项目做一个基本的介绍
tips:在任意目录打开cmd的方式可以使用下面这两种方式
- shift + 右键打开cmd(window10的powershell你可以简单理解为cmd升级版)
- 在路径框直接输入cmd,回车
1、建立一个scrapy项目
在cmd窗口中输入:scrapy startproject lagou,这样就创建了一个项目文件夹,文件夹的名字是lagou

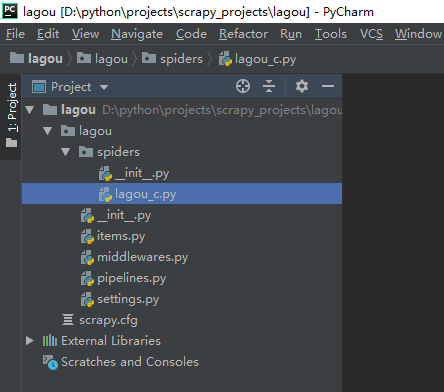
新生成一个scrapy项目,但是目前里面还没有一个爬虫,用pycharm打开外层lagou文件夹看看

从结构可以看出生成的lagou项目文件夹里面生成了一些新的文件夹和文件,
__init__.py:两个文件内容都是空的,存在的唯一目的就是让它所在的文件夹成为一个python包。
items.py:主要是用来定义要提取的字段的,比如我们要提取招聘职位的名称,薪酬,都需要对字段进行定义
middlewares.py:中间件,包括spider middleware和downloader middleware,前者可以对请求进行修改(比如加入代理,设置UA都可以在这里进行),后者可以对下载的页面进行修改
pipelines.py:主要是用来进行数据清洗,存储的
settings.py:爬虫项目的全局配置,比如全局的UA,是否开启middlewares中间键,设置延迟等
2、生成一个爬虫(注意:一个项目文件夹下面可以有多个爬虫)
首先进入到外层的lagou文件夹下
cd lagou
查看有哪些爬虫模板命令:scrapy genspider -l

一般用的比较多是basic和crawl两种,basic适合主页比较简单,url基本一致的情况,crawl适合有多种标签类别的网站
针对拉勾网,这里我们选用crawl模板生成爬虫,爬虫名称是lagou_c,爬取的首页url是lagou.com
scrapy genspider -t crawl lagou_c lagou.com (-t crawl代表以crawl模板生成爬虫,如果不加这个参数以basic模板生成的爬虫scrapy genspider lagou_c lagou.com)
注意:爬虫名称一般设置为要爬取的url名称,如lagou.com,设置为lagou为爬虫名,但爬虫名和项目名不能重复,我这里修改爬虫名为lagou_c

这样我们就建立了一个名称为lagou_c的爬虫项目,再次用pycharm打开可以看到多了一个lagou_c.py文件,这个文件就是爬虫的入口,它主要是用来产生新的请求和对返回的response进行解析。