分布式测试是测试领域中的集大成者,要做好做精,需要做到三方面的准备,一是测试能力的储备,包括功能,性能以及各种测试工具的开发的能力要到位;二是对于常用的分布式架构、技术、系统(如缓存,分布式数据库,消息,降级、熔断及限流等等)要有一定的理解,三是要对业务场景较为熟悉,因为每个分布式架构都有各种的优缺点,也就是要在所谓的CAP理论中找到一个平衡点,本文会从一下几个方面来展开:
- l 系统架构的演进(传统单体到分布式架构)
- l 分布式测试中的窘境
- l 透过一个生产事故案例来说明分布式测试的重要性
- l 常见分布式应用场景的一些测试要点
一、系统架构的演进(传统单体到分布式架构)
国内的互联网发展日新月异,据trustdata三月份发布的统计数据,排名前200位的App月活均超过了800万,在如此大的访问量的情况下,传统的业务单体架构模式,不太适合新的业务发展形态如突然激增的营销活动、快速的第三方进行交互集成、故障影响面,下面针对这三个问题来展开:
· 突增的营销活动
在传统的单体架构下,要应对可能流量激增的营销活动,应对的手法非常有限,基本就是靠硬件的物理扩容来实现,如果是垂直扩容还好(机器的配置增强,如增加内存,cpu等),这对系统的拓扑结构没有任何变化,但单机毕竟是有极限的,到垂直扩容到一定阶段,就没法升级了,这时候就只能水平扩容(增加新的机器)了,这就会麻烦多了,对于实现应用的部署方案,机器与机器之间的负载均衡策略等都带来了极大的负担
- 快速和第三方网络交互集成
在传统的单体架构下,和第三方的网络交互一般都是通过接口来实现,但接口交互存在在几个比较大的缺点,一个是耦合度比较高,有变动就很可能要通知到关联方,并且会影响多方的正常业务交互,第二个是处理并发能力不太理想,尤其是一些流量变化巨大的场景(比如访问量集中在某些时段)容易出错或者是存在着极大的资源浪费
- 故障影响面
在传统的单机架构下,往往一台主机挂了,那么基本上这个系统所有的功能都不可以了,这样就会对系统或者业务造成巨大影响
上述这些问题在分布式架构下,都有比较好的解决方案,比如针对突增的营销活动,通过spring cloud等架构,通过服务注册和发现来实现快速的弹性扩容,还有通过一些缓存如redis来提升数据处理能力;针对快速和第三方网路交互集成,可以采用各种消息系统(如kafka,以及各种MQ)来实现解耦和流量的削峰填谷;针对如何减小故障影响面,可以通过微服务的模式,这样一台主机挂了,也就影响其中一台机器,并且可以通过故障转移(如心跳检测)的方式,把这台机器下线,后续用户的访问同一服务中的其它正常节点。现在大多数公司的系统的架构都趋向于分布式设计,并寻求在CAP(一致性,可用性和分区可容忍性)里找到一个平衡点。
二、分布式测试中的窘境
针对系统结构的快速演进,我感觉大部分的测试同学都没有做好相应的准备,还是拿着传统那套测试的理念在实现分布式架构下的的测试工作,如下是我总结的分布式测试现状:

简单解释一下:
1. 我们同学的测试大多聚焦在功能性,兼容性或者性能上,很少去理解分布式中的一些比较容易出故障的地方,比如项目中涉及了哪些分布式事务;多线程分片处理会不会出现死锁;关联系统出现故障会不会拖垮我们等等
2. 缺少对分布式系统的了解,对于一些常用的分布式架构,比如缓存系统,消息系统,三段式分布式事务处理系统以及与他们相关的一些代表性产品,很多同学都只是听过而已,但不太熟悉它们的产生背景以及系统架构以及各自的优缺点。
3. 不太会把业务场景和分布式系统穿起来考虑,即使了解了项目或者产品中设计到的分布式系统 /架构,但如果没有吃透我们的业务场景,那设计用例时就只会生搬硬套
4. 项目排期比较紧,目前的排期基本职能实现既定的功能、性能等测试需求
5. 测试环境的制约,由于费用的原因,有些项目的测试环境的系统部署可能是一个假的分布式系统,阉割掉了不少的机器,比较典型的是一台nginx后面只放一个实例
因为开发同学对场景和技术都熟悉,测试同学和研发同学的差距就会越拉越大,所有久而久之 ,测试因为在分布式测试上缺少能力,也就丧失了测试上的独立性,在测试过程中也就形成:1. 开发说啥就是啥,完全按照开发的要求去做测试;2. 开发有着他的开发任务,顶多就是在分布式测试提一些指导性的建议,不会太注意测试上的细节,测试同学在测试执行的时候,有可能会遗漏一些要点或者没有完全领会测试重点,所有导致生产问题或者生产隐患的堆积。
所以要解决分布式测试中的窘境,还是需要我们积累自己的基本功,打铁还需自身硬,后面我会展开讨论分布式测试场景以及如何做好分布式测试
三、透过一个生产事故案例来说明分布式测试的重要性
两年前我们的App遇到了一个较大的生产事故,先说一下流程,我们是一个互联网金融的公司,在App上会有各种理财或者贷款产品的售卖,也拥有不小的日活,现在以启动举例,用户在登录状态下,启动App,就会加挂资产平台,资产平台会去缓存中捞取用户的资产信息,如果缓存中没有,就会通过集体的通用接口去相关的子公司或者外部的关联方获取相关的用户资产信息,大致流程如下:
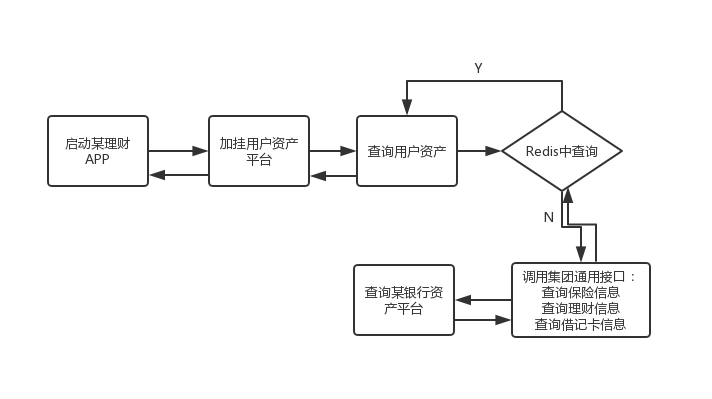
但有一点要在这里说明的,由于App是金融工具属性,这个不像社交或者日常工具那样使用频繁,可能是一个星期或者一个月才会使用那么几次,所有Redis的效果不是太好,很容易穿透缓存直接去请求服务。
事故的起因是某天的某个时间段,该银行的资产平台挂了,我们的请求由于缓存效果不太佳,不断有用户发起请求去查询该银行的资产平台,慢慢的所有的连接都被耗在这个系统的请求上,导致服务器被打爆,重启后有立马被这些慢查询给占满。说到这里可能大家也都知道了,这边出现的是什么问题,就是我们的系统没有做好熔断隔离:

后来的改造方案就是在网关层引入netflix的hystrix框架,通过hystrix来保证关联方系统的问题不至于造成我方的所有服务不可用,把问题的影响面降到最低,这里分布式测试的要点会有以下几个内容:
1. 并发请求量超过maxRequest
2. 请求时间超过timeout
3. 请求失败比例errorThreshold
4. 熔断恢复间隔
5. ......
但这里其实有一个很大的难度在于这些阈值的设定,阈值设置的太高,会对资源有极大的浪费,并且可能会降低日活;设置的过高,这样熔断有可能是形同虚设。所以这些都需要我们测试同学在测试环境以及生产环境上进行多轮的测试,并且即使设定好之后,还是需要定期的去检查并做好动态调整。
另外,再进一步,我们能不能从产品的角度去改进产品达到降低问题发生的可能性?如果能在产品上提一些有建设性并且有落地可能的建议,那么也会更多的获得研发同学或者产品同学的认可,在后面的测试工作的开展中也能起到更好的效果。如下是我们当时的一些建议:
- 一级菜单静态展示资产平台,用户主动点击来展示
- 资产平台通过二级菜单来展示
- 资产做分类,自己公司的资产启动时加挂,关联方资产点击时拉去
四、常见分布式应用场景的一些测试要点
1. 多线程分片处理
这个并不是分布式系统独有的,在传统系统中也同样存在,但这里我还是把他拉出来说,是因为这种场景还是很常见的,我们有比较多的问题就是因为这个原因造成的,举个例子:现在有A,B两个线程,A先锁表1,并操作表2,B是先锁表2,然后再操作表1,一开始由于数据量不大,这两个线程都非常快的处理完了事务,但随着表的数量越来越大,两个线程耗的时间也越来越多,终于到了某一天,两个线程重叠的时间到了临界点,A锁表1,然后操作表2的时候,表2被锁,B操作表1,表1被锁;造成了死锁现象。
隐患点:
- 在大批量运行下需要考虑片与片之间相互死锁的情况。
2. 分布式事务处理
这个现在太常见了,比如理财产品的售卖,可能涉及到货架,订单,积分等不同的系统,用户购买理财产品会涉及到支付成功,库存扣减,积分增加等结果,这些结果是要保持一致的,也就是要么都成功,要么失败后回滚到之前的状态。这些系统的数据也是分在不同的库中,目前处理分布式事务的普遍有两段式和三段式,对于我们来讲我们需要理解我们的场景,业务量以及我们采用的分布式事务框架。比如一致性高和并发量大,这两个是天然矛盾的,所有需要在选型的时候做好准备。
这里的隐患点有:
- 资源不足,比如库存不足
- 某些系统的性能问题会不会触发事务回滚
- 日志是否合理或者记录详细,尤其是需要人为来操作回滚
- 消息协调者故障如消息丢失或者消息服务宕机
3. job
job执行现在也越来越多的在各个项目中运用到了,但随之而来因为job带来的生产问题也越来越多,而且job的结果有一定的滞后性,有可能到T+1才发现的生产问题是和job执行有关,现在有比较多的开源分布式job,比如xxl-jobs等
这里的隐患点有:
- job的重试机制需要保证job的幂等性,这个不要觉得是理所当然的,有些job执行可能包含准备数据,插入临时表,临时表到正式表。如果我们的job只是这样设计的话,就没有满足幂等性要求,比如现在在临时表到正式表挂了,那么再起job的时候,如果没有清楚临时表,那么临时表的数据就会有大量的脏数据,就会导致插入正式表出问题,所以在启动job之前,都要把之前的一些临时表的记录都清除掉
- Failover后到下一个job执行是否OK
- 分布式job服务挂了等等
4. 消息中间件
消息中间件一方面起到了系统解耦的作用,另外对于业务并发处理也能起到削峰填谷的作用,目前常用的有kafka或者各种MQ来
这里的隐患点有:
- 消息不一致情况:生产者丢失消息或者消费段重复消费
- 消息堆积
- 重发导致消息乱序
5. 容错机制
这里指的是在高并发并且错综复杂的业务关联情况下,保证系统或者大部分系统的服务正常运转,通常有降级,熔断和限流三种类型,分别简单的来介绍,降级就是一种主动行为,主动意识到在某个时间段会有高并发的业务进来,那就把一些不太要紧的但使用量比较大的入口关掉,把这部分的资源让出来给高并发的业务;熔断是一种被动行为,就是防止关联方的问题影响到我方的大部分服务,具体可参见我上面的生产问题例子;限流就是为了防止过高的用户进来影响整个服务,预设了一定的阈值;把超过阈值的请求挡在外面,保护了服务的正常运转。
这里的隐患点主要是:
- 阈值的如何设定,这是一个很难的设置;而且随着业务和机器网络容量的变化需要动态调整
6. 缓存系统
缓存现在几乎在任何一个分布式场景中都会用到,经常用到的缓存是redis或者Memcache,他们对于数据的并发处理都非常强劲。
这里的隐患点主要是:
- 缓存穿透,缓存雪崩以及缓存击穿,这个要展开内容就比较多了,对这个不太了解的同学,建议大家搜索一下
- 缓存更新可能带来的数据不一致, 这个建议大家可以看一下这篇blog
7. 分布式数据库
这里主要涉及到的是数据库的读写分离以及分库分表
读写分离往往是主从架构,主库负责读写操作,从库负责读操作,对于一些读远远大于写的操作的系统,效率提升非常好
读写分离主要的隐患:
- 主从复制延迟,比如高并发大数据下,数据写完后立马读操作的场景,还是拿理财产品购买为例子,用户只有注册后才允许购买,现在用户注册完后,点击购买按钮,然后到从库去查询,由于并发压力大导致网络延迟比较严重,从库还没得到用户注册的记录,这个就尴尬了,明明用户已经注册了,还要求再次注册。解决这个问题一般有两种,一种是通用型的:读两次,就是在从库中没读到,再到主库中查询一次;另外一种是定制化的,对于某些服务,就是读写操作都是到主库中;各有各的优缺点。通用型的业务逻辑简单,但对主库的并发较高;定制化的不需要读两次,但代码耦合度比较高
分库解决的是存储和方案压力
分库的隐患有:
- 插入和join操作的复杂性,之前的join相关的业务逻辑有可能都要重写,我们测试也都需要重写测试
- 分布式事务问题,这个之前分布式事务中也讲到了,就不再展开了
分表:主要解决的是性能问题,可以有垂直分表和水平分表两种,垂直分表就是把大表分成热数据和冷数据,这样能大大提升读取的效率
垂直分表的隐患:
- 插入和join等操作都需要重写
水平分表,就是保持schema不变,但会根据路由的不同把相应的数据插到不同的子表中
水平分表的隐患:
- 路由的选择,如果是hash分表的话,需要考虑字表扩展的隐患,有可能扩一张表会导致所有的表内容都要搬家一次
- count,之前没有分表的时候或者垂直分表,count是一次到位,但现在分了多张表,要所有表的count,所以对count也要做好处理
- join的复杂性,这个和上面类似
所以,总体来讲,分布式测试是一项综合技能比较高的测试,要做好做精需要在多方面下文章