这里引用吴恩达教授在课程中的截图。
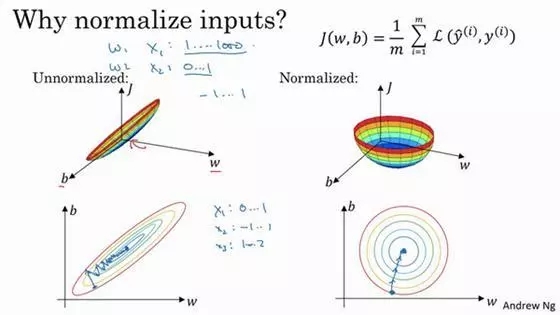
一、 w,b分布
我们首先分析一下为什么非归一化的的cost呈现这种分布。
对于一个没有归一化的数据,X和Y可能呈现很大的数量级差距,如果X相较于Y非常大的话,改变W对Z的影响将会相对b来说非常大。
举个例子,如果Y在0,1之间,而X在100000以上,在梯度下降的过程中,w将会变化极小,因为稍微变化百分之一,都可能造成cost变化非常大。
二、 梯度下降
我们再分析一下,梯度下降的过程会发生什么。对于第一个图,如果我们在图中标识的起始点,我们的梯度并没有指向最优点。所以在梯度下降的过程中,迭代结果可能并不是有效的,甚至变得更加糟糕。
而相反,我们从第二图中可以看出,在圆中的任意一点,我们的梯度下降的方向均是指向最优解,这让我们的迭代变得更加高效。
以上是归一化加速训练的原因。