本文《machine learning in action》学习笔记
数据源码可以在这里获取 :https://www.manning.com/books/machine-learning-in-action
这里Python 3+的code
from numpy import *
import matplotlib.pyplot as plt
import operator
def kNNClassify(inX, dataSet, labels, k):
'''put the kNN classification algorithm into action'''
dataSetSize = dataSet.shape[0]
diffMax = tile(inX,(dataSetSize,1)) - dataSet
sqDiffMax = diffMax ** 2
sqDistances = sqDiffMax.sum(axis=1)
distances = sqDistances**0.5
# argsort 返回由大到小的索引值
sortedDistIndicies = distances.argsort()
classCount= {}
for i in range(k):
# 找到最大索引值对应数据的label
voteIlabel = labels[sortedDistIndicies[i]]
# returns a value for the given key
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
# 按照键值的大小排列
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]
def file2matrix(filename):
"""process the text information"""
fr = open(filename)
arrayofLines = fr.readlines()
fr.close()
numberofLines = len(arrayofLines)
returnMat = zeros((numberofLines, 3))
classLabelVector = []
index = 0
for line in arrayofLines:
# Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)
line = line.strip()
# split()通过指定分隔符对字符串进行切片,这里使用tab
listFromLine = line.split(' ')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector
def autonorm(dataset):
"""归一化"""
# 求每一列最小值和最大值
minvalue = dataset.min(0)
maxvalue = dataset.max(0)
ranges = maxvalue - minvalue
# 使用shape获取dataset的shape
normdataset = zeros(shape(dataset))
# shape[0] 获取第一行元素个数
m = dataset.shape[0]
# 使用tile函数将变量内容复制成输入矩阵同样大小的矩阵做矩阵的减法
normdataset = dataset - tile(minvalue, (m,1))
# 做矩阵的除法
normdataset = normdataset / tile(ranges, (m,1))
return normdataset, ranges, minvalue
def datingclasstest():
horatio = 0.1
datingdatamat, datinglabel = file2matrix("datingTestset2.txt")
normat, ranges, minvalues = autonorm(datingdatamat)
m = normat.shape[0]
numtestvec = int(m*horatio)
errorcount = 0.0
for i in range(numtestvec):
#classifierresult = classify0(normat[i,:], normat[numtestvec:m,:], datinglabel[numtestvec:m,:], 3)
classifierresult = kNNClassify(normat[i, :], normat[numtestvec:m], datinglabel[numtestvec:m], 3)
print("No.%d test data, the classifier came back with : %d, the real answeris: %d" %(i, classifierresult, datinglabel[i]))
if (classifierresult != datinglabel[i]):
errorcount += 1.0
print ("the total error rate is: %f" % (errorcount/float(numtestvec)))
if __name__ == '__main__':
datingdatamat, datinglabel = file2matrix('datingTestSet2.txt')
normdataset, ranges, minvalue = autonorm(datingdatamat)
print(normdataset)
print("ranges = ", ranges)
print("minvalue = ", minvalue)
fig = plt.figure()
ax = fig.add_subplot(111)
# 画散点图 scatter
ax.scatter(datingdatamat[:,1], datingdatamat[:,2], 15.0*array(datinglabel), 15.0*array(datinglabel))
plt.show()
datingclasstest()
读取TXT数据
def file2matrix(filename):
"""process the text information"""
fr = open(filename)
arrayofLines = fr.readlines()
numberofLines = len(arrayofLines)
returnMat = zeros((numberofLines, 3))
classLabelVector = []
index = 0
for line in arrayofLines:
# Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)
line = line.strip()
# split()通过指定分隔符对字符串进行切片,这里使用tab
listFromLine = line.split(' ')
returnMat[index:1] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector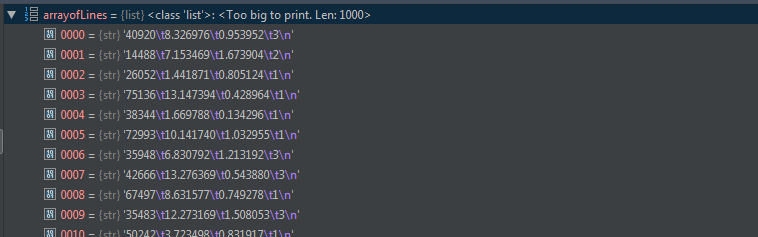
normalization result:

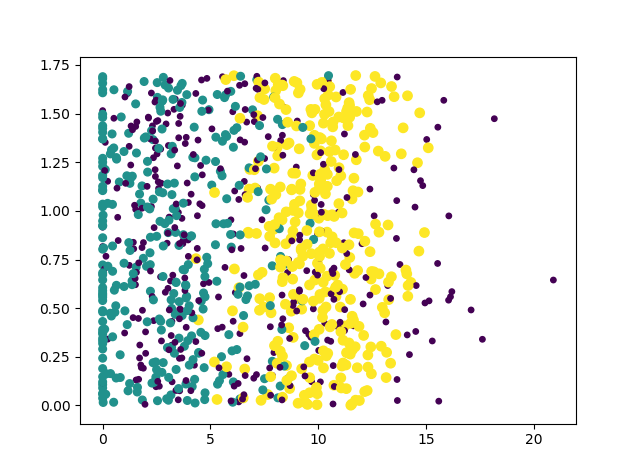
plot:
test result:
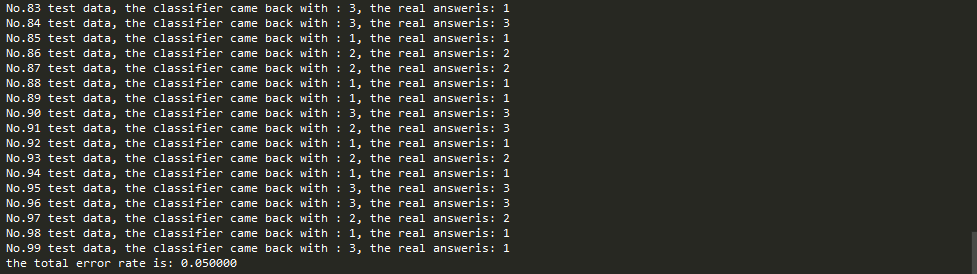
结果与书中的结果并不一致,kNN这么简单的算法,其结果应该一致才对。为什么?