1. Gradient Checking
我们讨论了如何进行前向传播以及后向传播,从而计算导数。但有一个不幸的消息是,它们有很多细节会导致一些BUG。 如果你用梯度下降来计算,你会发现表面上它可以工作,实际上, J虽然每次迭代都在下降,但是可能表面上关于theta的函数J在减小而你最后得到的结果实际上有很大的误差。有一个想法叫梯度检验Gradient Checking。
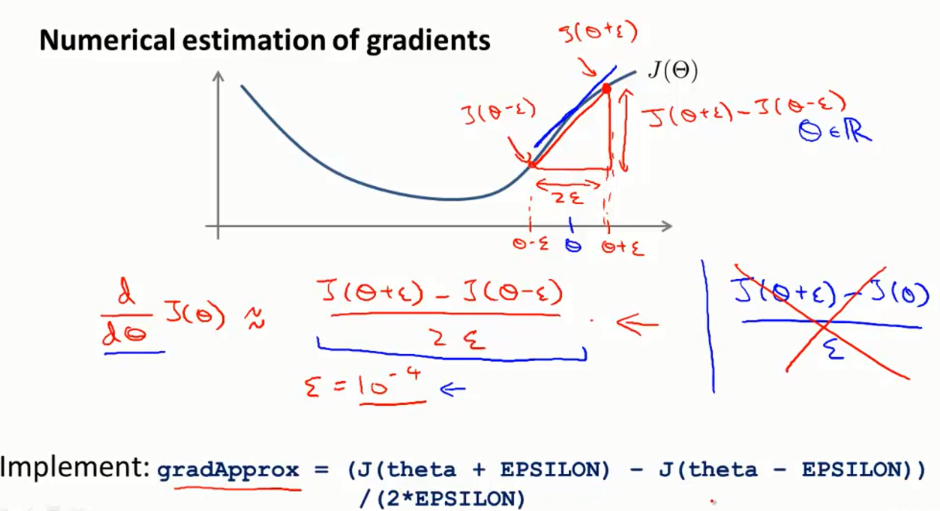
假设我们有一个关于theta的函数H,现在有它的一个值,假设是实数,想要预测它的导数, 导数等于这个点的斜度 。我们不适用求导的方法求这个点的导数,而是使用数值逼近的方法去逼近这个导数。取, 两边x的坐标,, ,,代入函数计算,,得到两个坐标(,, (,,蓝线就是真实斜率,红线是逼近的斜率,他们相差很小。这里计算使用了精度跟高的双边导数。红色标注的双边导数近似公式,除以的是2倍。
神经网络中,theta是一个向量有n个取值。我们把它展开成一行或者一列,对于每一个theta都能做梯度检测。

在使用梯度检测是有一些需要注意的事项:

2.Random initialization
权重的初始化对梯度的优化是很关键的,初始位置不同,最终得到的可能不是全局最小值,而是局部最小值。下面讨论不同的处置对网络的影响。
全部初始化为0会出现问题,通过计算梯度,更新的结果是这参数都一样。
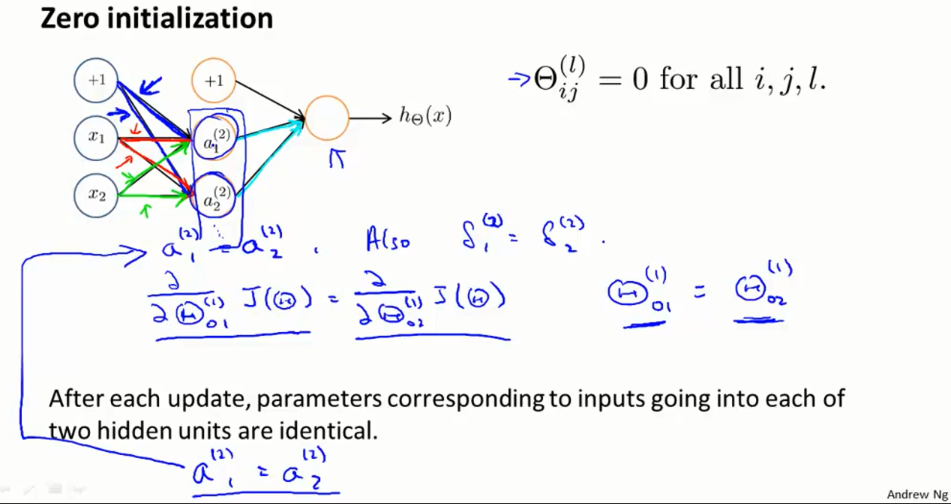
为了表面上述的问题,我们在初始化权重的时候,有一个准则就是打破这种对称性。常使用下面这个初始化方式。

一个问题:

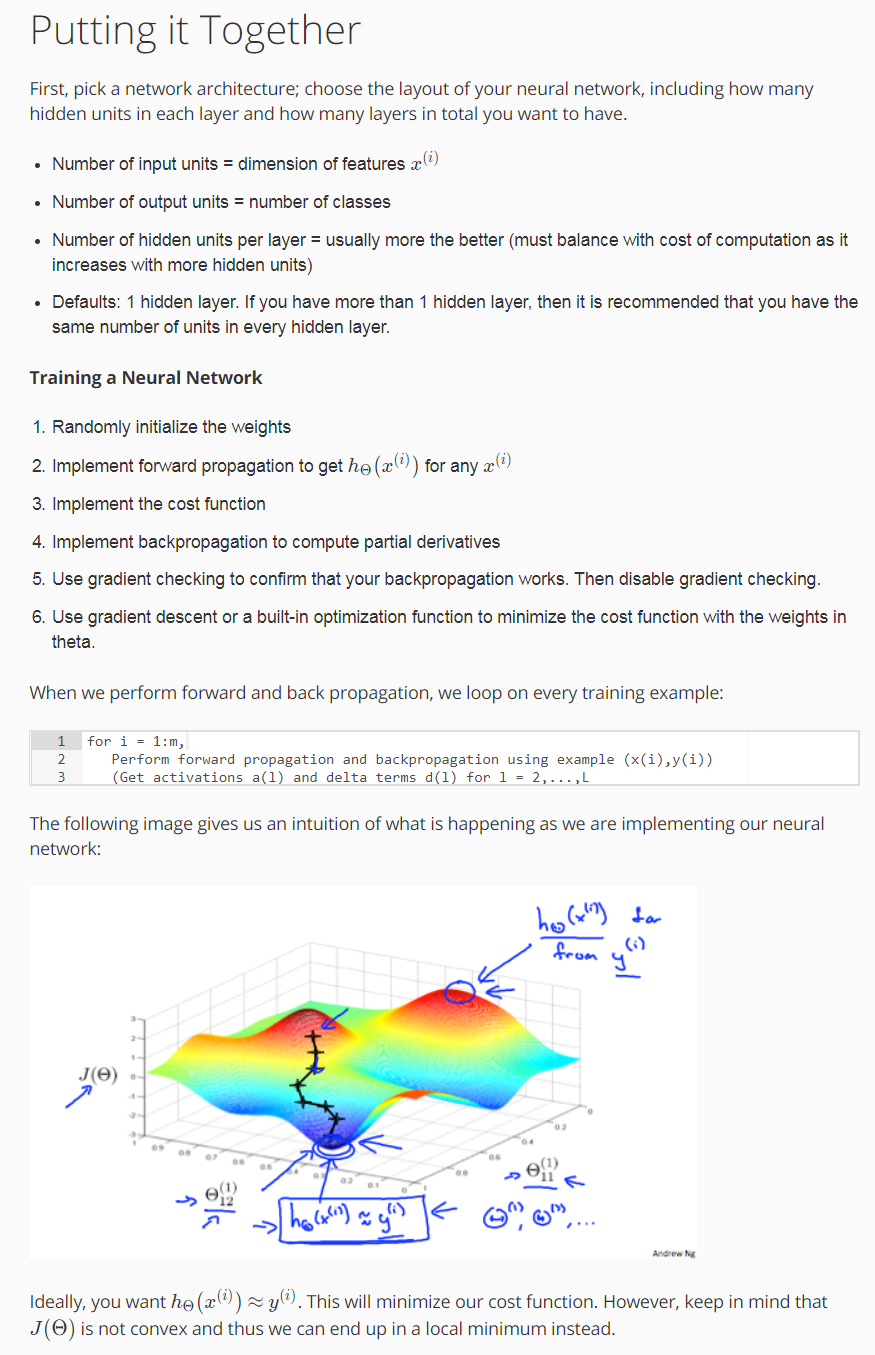
put it together
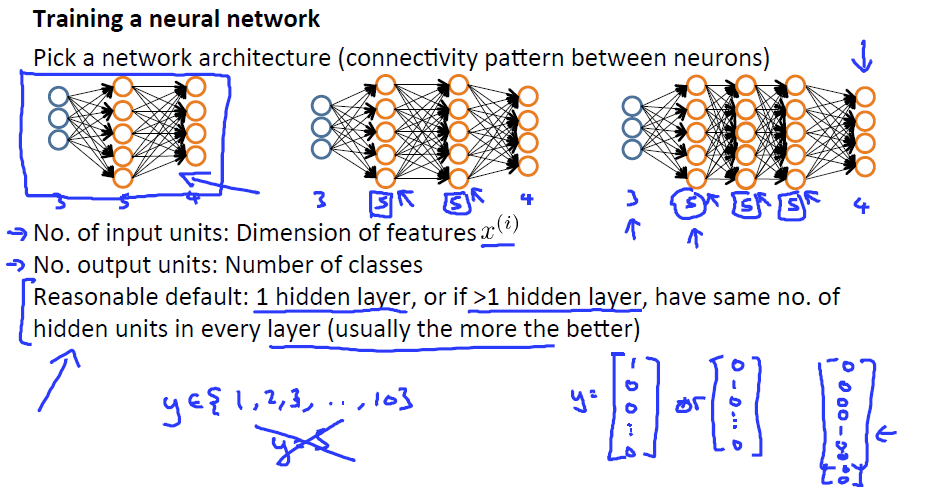
训练一个网络,我们需要先选择一个网络结构,确定输入和输出的个数,网络的层数。默认我们设置为1层,如果大于一层,每层unit的个数也设置为相同。


我们知道如何去计算代价函数,如何使用反向传播算法来计算偏导数。 那么我们就能使用某个最优化方法来最小化代价函数J(θ)。 对于神经网络代价函数 J(θ)是一个非凸函数,因此理论上是会停留在局部最小值的位置。 实际上梯度下降算法其他一些高级优化方法理论上都会收敛于局部最小值。尽管我们不能保证这些优化算法一定会得到全局最优值,但通常来讲 像梯度下降这类的算法在最小化代价函数 J(θ)的过程中还是表现得很不错的,通常能够得到一个很小的局部最小值。
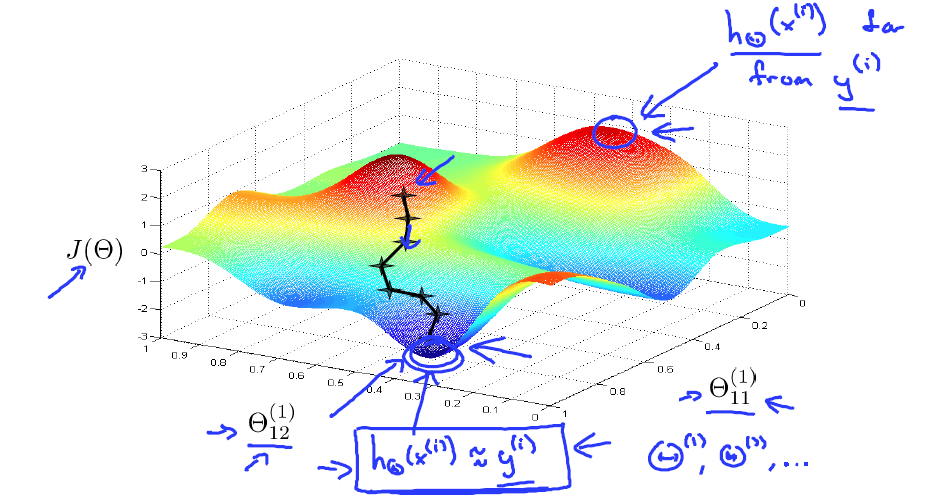
反向传播算法的目的就是算出梯度下降的方向。而梯度下降的过程就是沿着这个方向一点点的下降,一直到我们希望得到的点。