数据转换指的是对数据的过滤、清理以及其他的转换操作。
移除重复数据
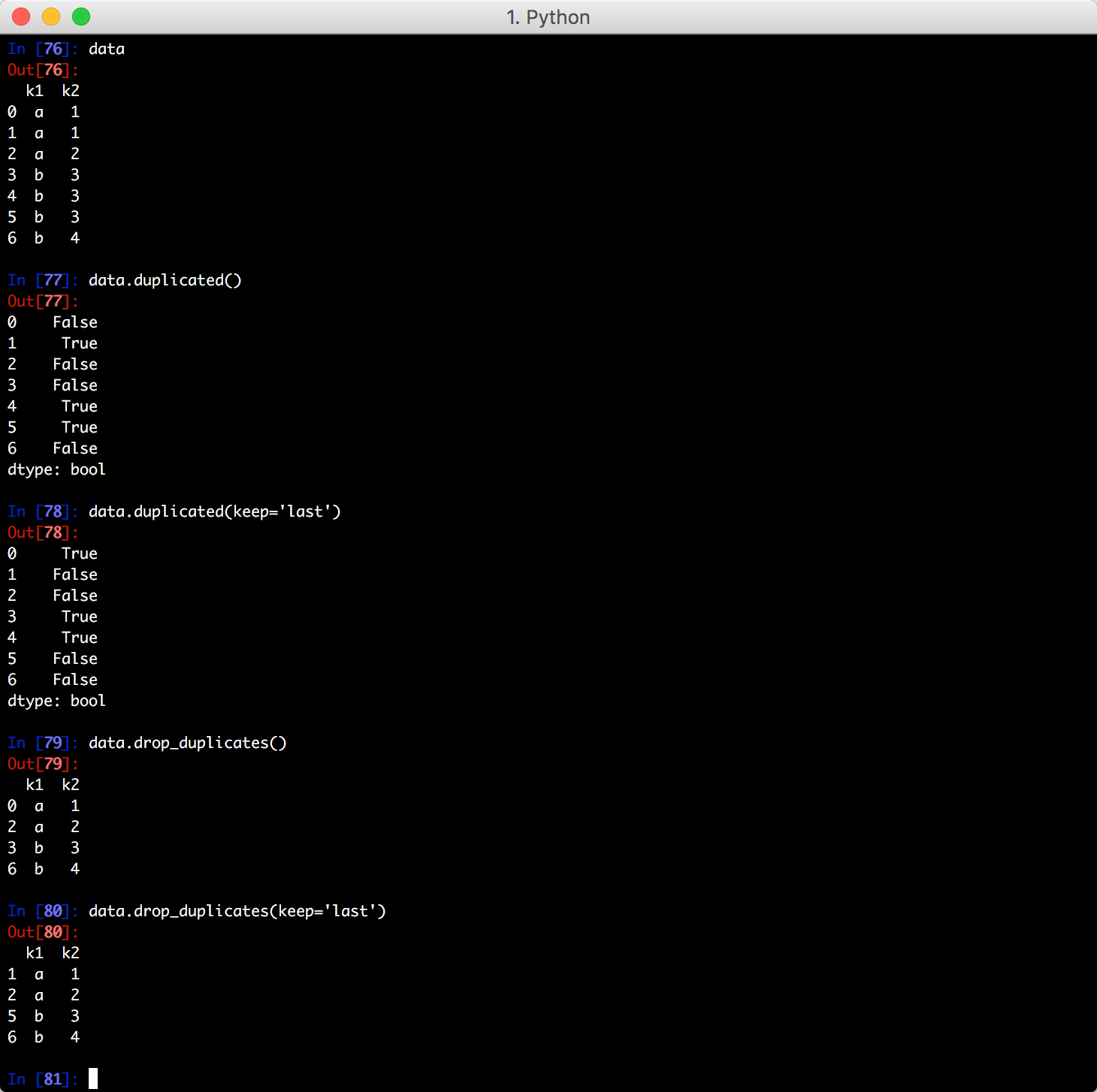
DataFrame里经常会出现重复行,DataFrame提供一个duplicated()方法检测各行是否重复,另一个drop_duplicates()方法用于丢弃重复行:
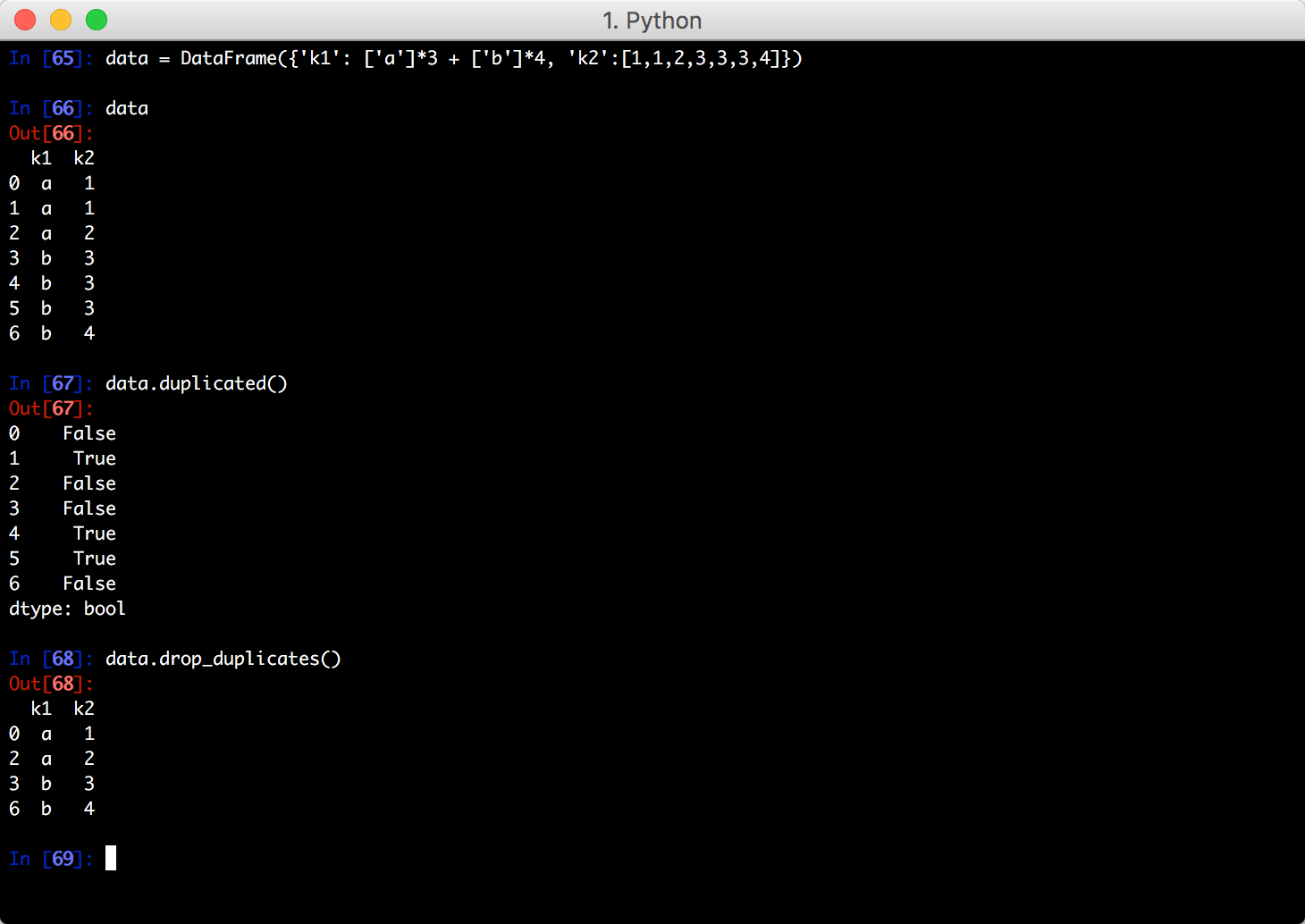
duplicated()和drop_duplicates()方法默认判断全部列,如果不想这样,传入列的集合作为参数可以指定按列判断,例如:

duplicated()和drop_duplicates()方法默认保留第一个出现的值,传入take_last=True保留最后一个值:
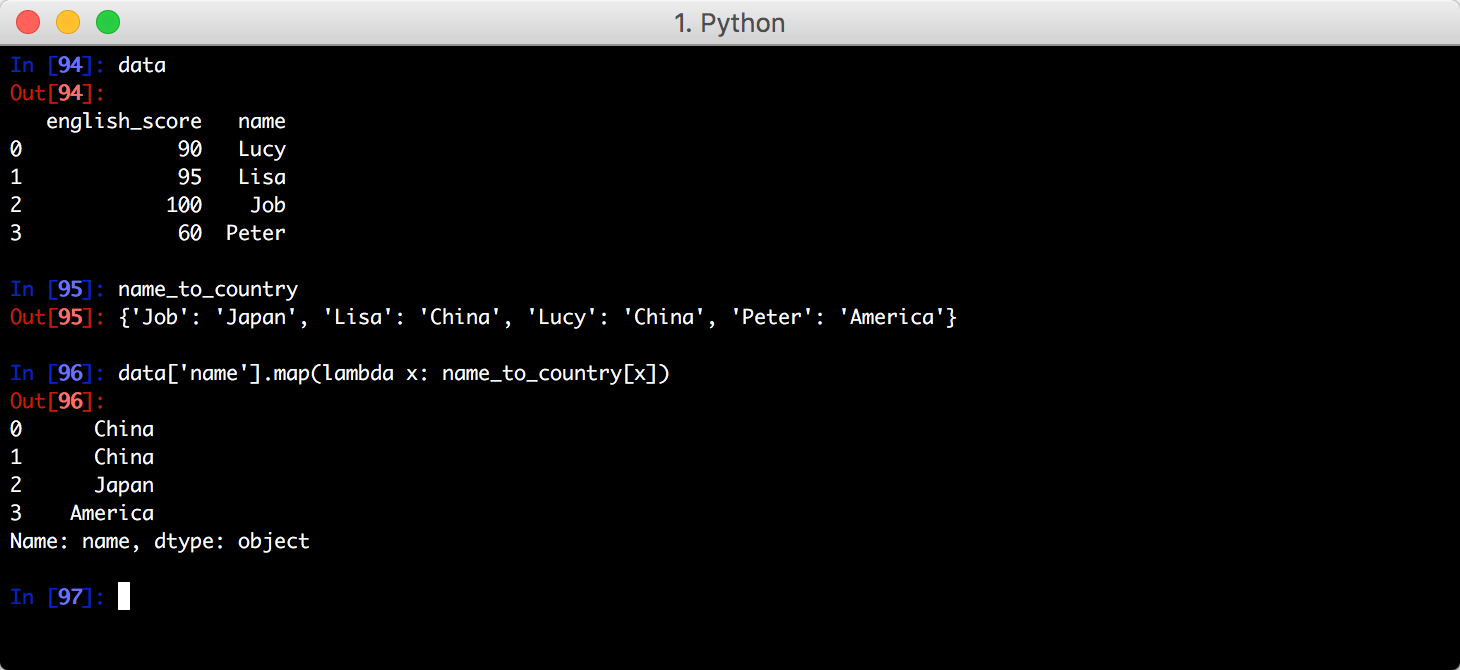
利用映射进行数据转换
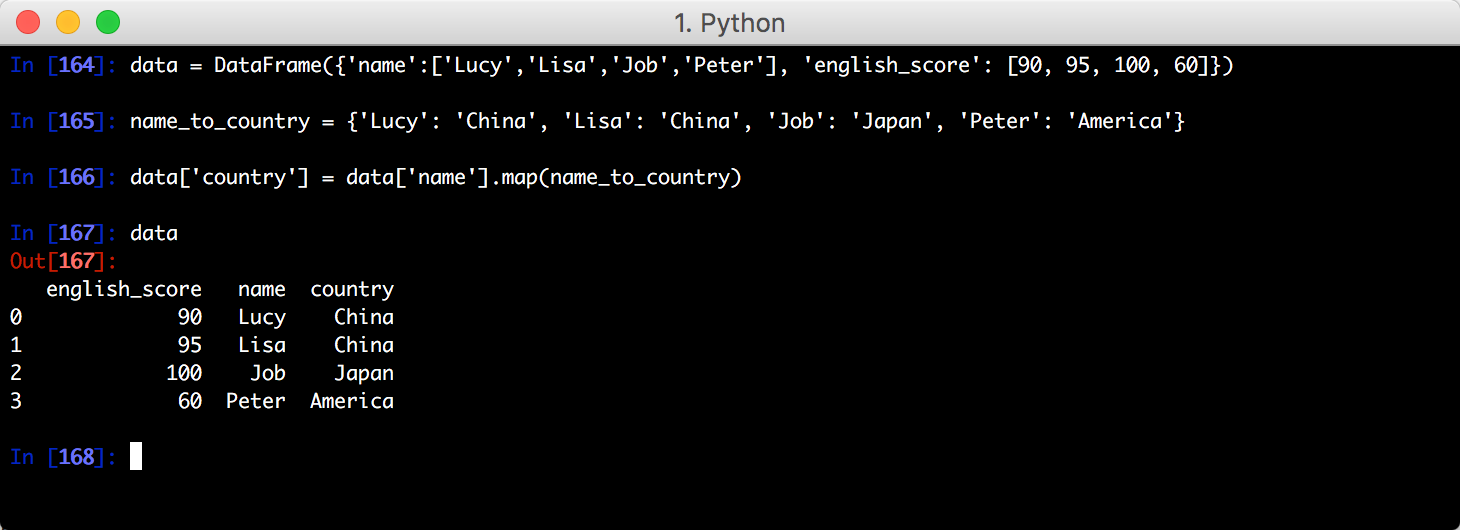
使用函数也能达到同样的效果:
替换值
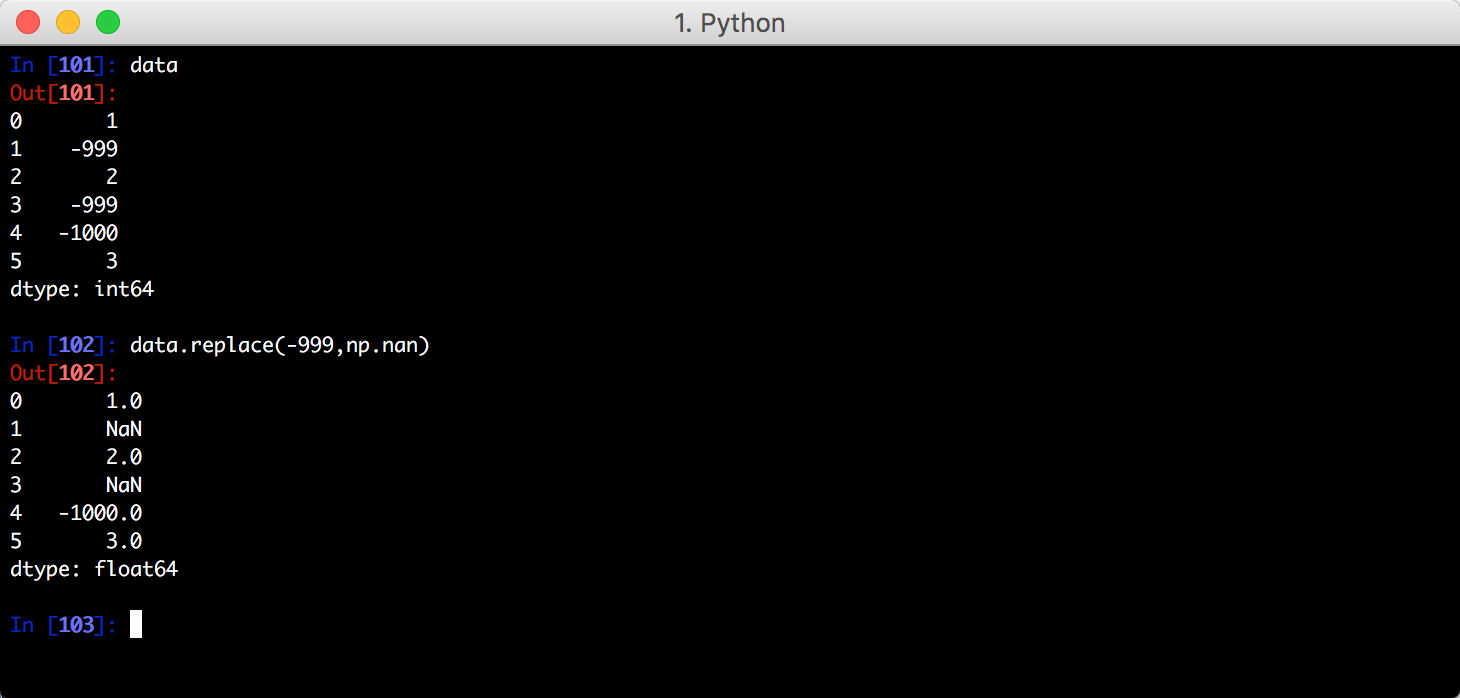
replace()方法用于替换:
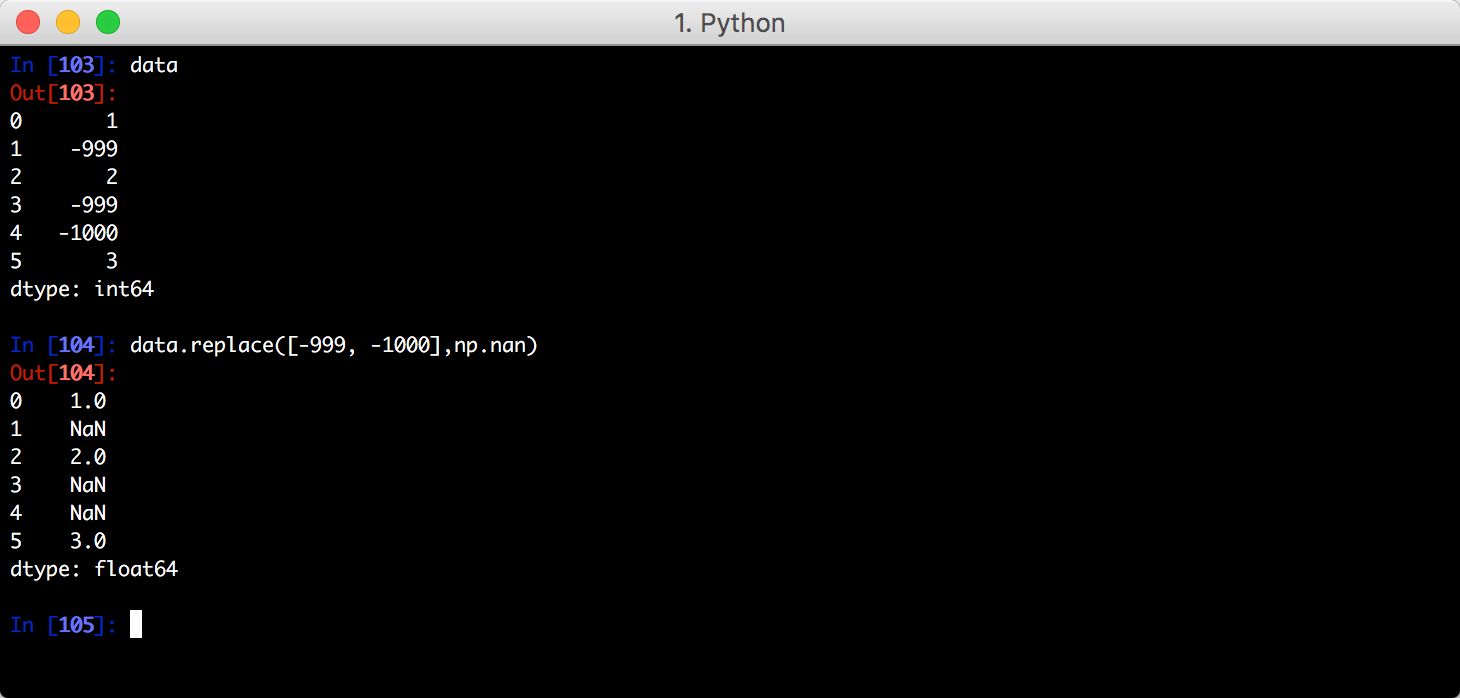
一次替换多个值:
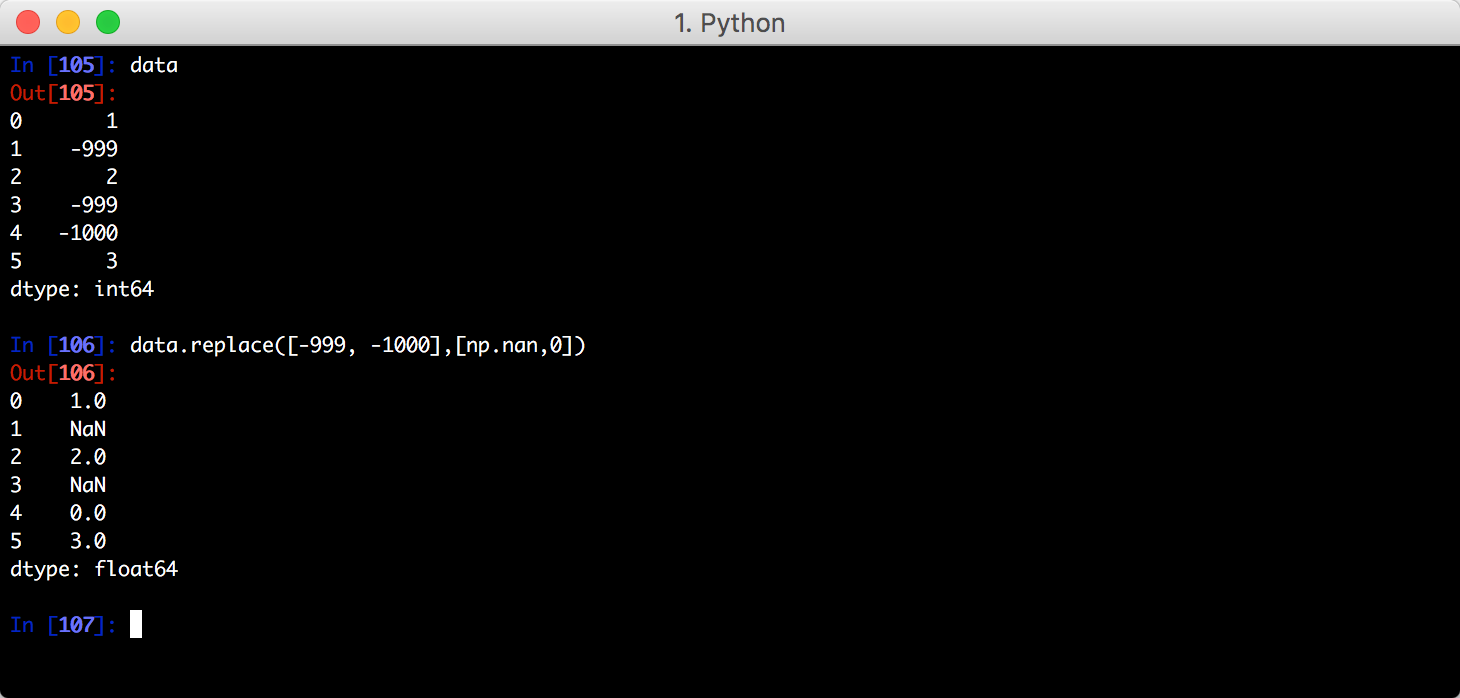
对不同的值进行不同的替换:
DataFrame重命名轴索引
重命名列:
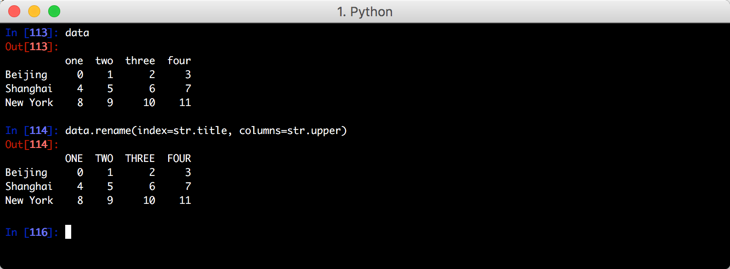
重命名索引:

将数据划分成不同的组:

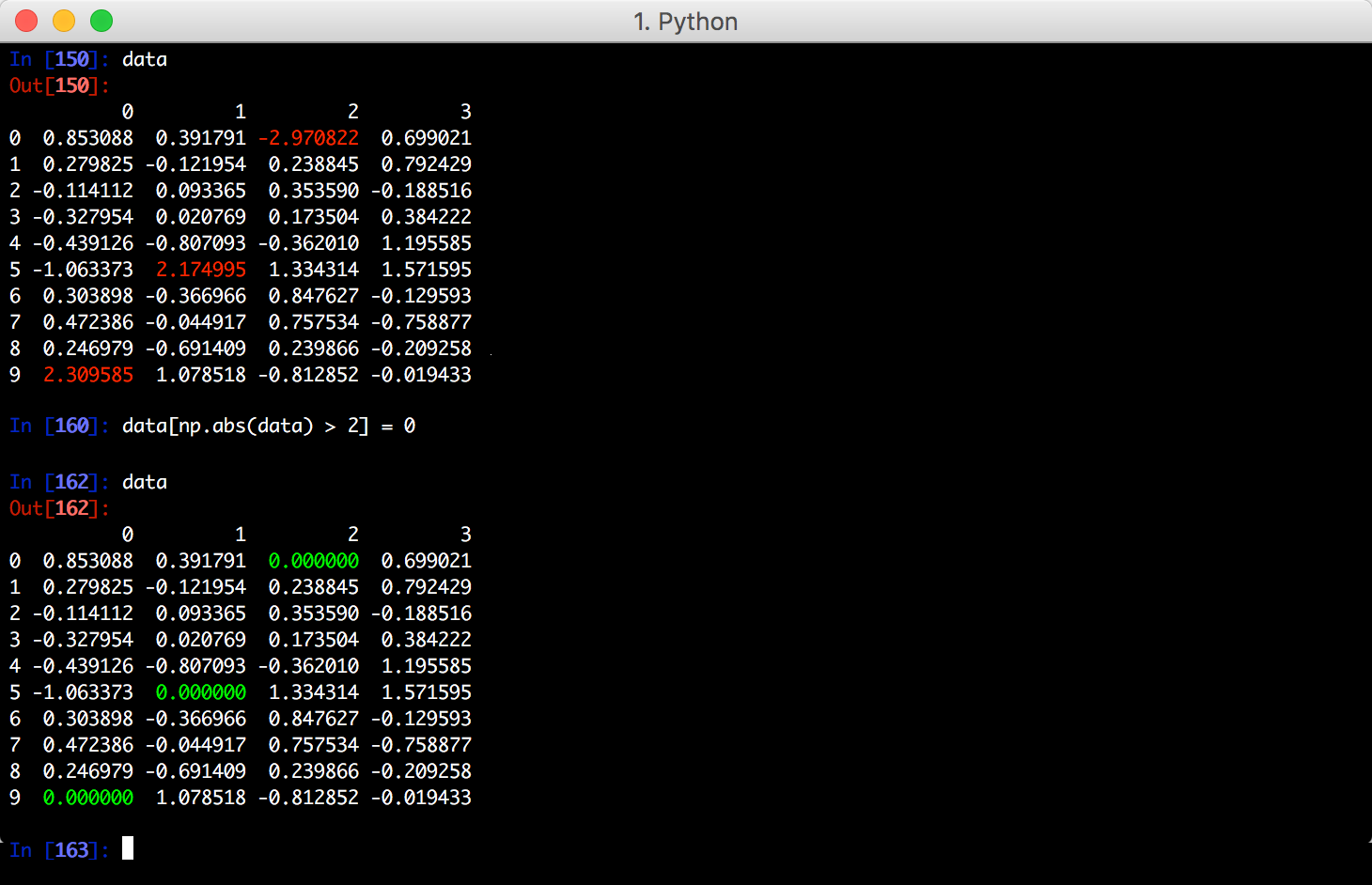
检测和过滤异常值
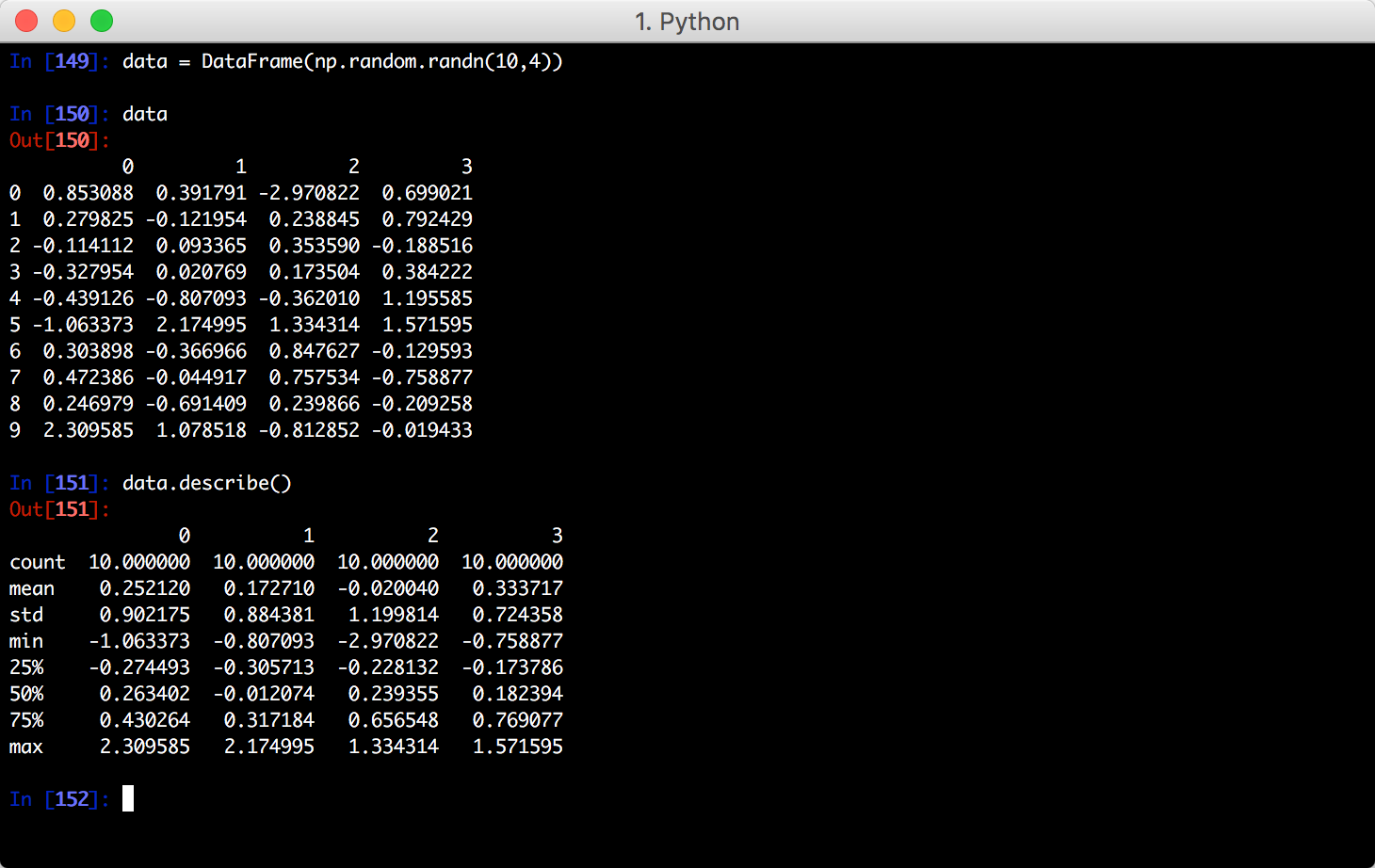
假设你有一组数据:
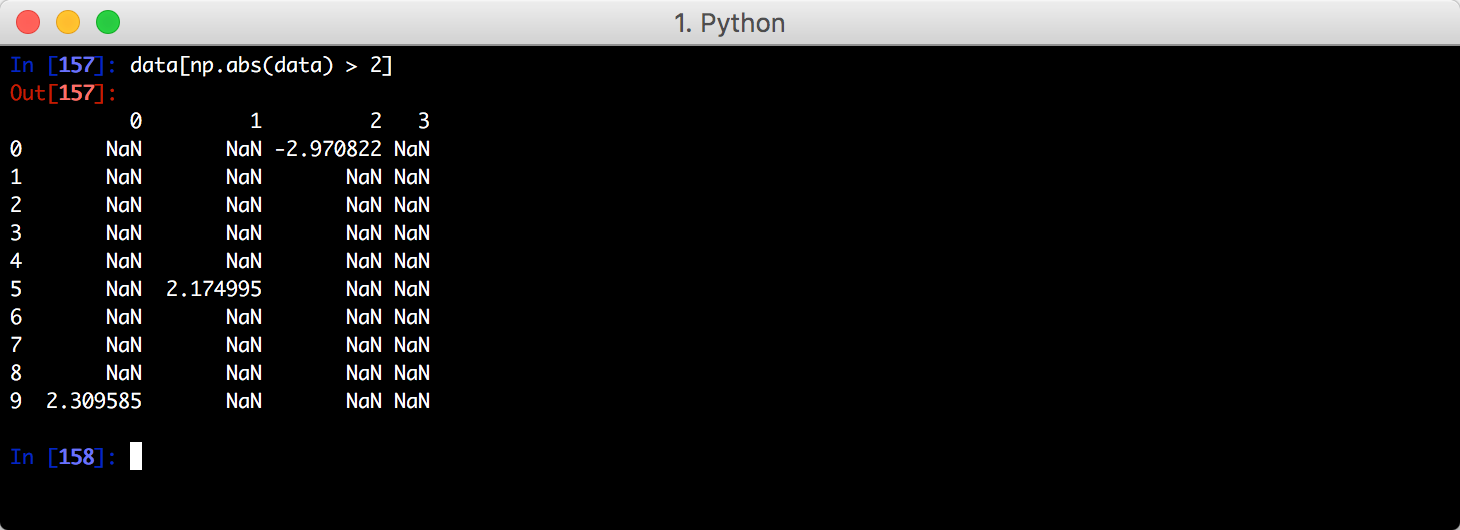
找出绝对值大于2的值:
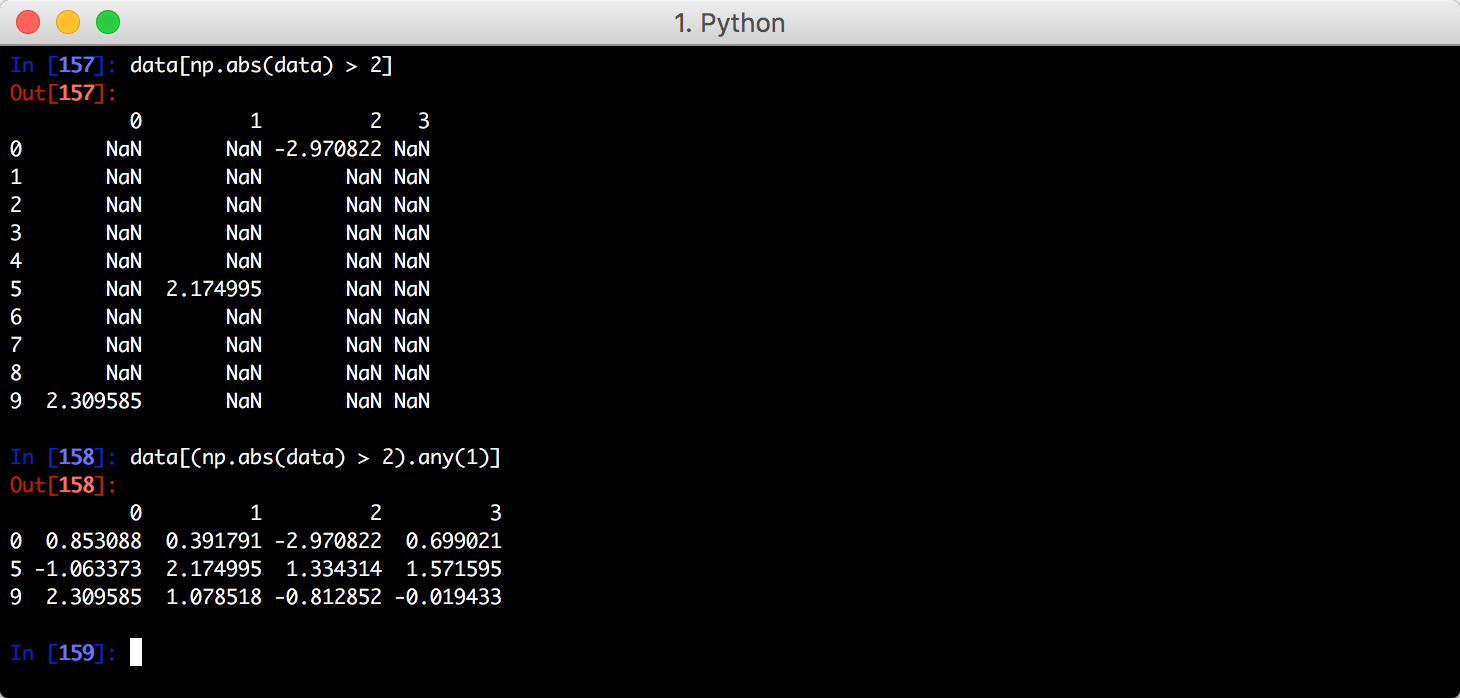
找出绝对值大于2的行:
将异常值设置为0: