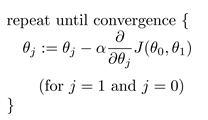教机器进行学习,数据集有标签 ,主要有:
以线性回归为例,主要有:
以二分类为例,主要有:
逻辑回归(Logistic Regression)算法/模型(该模型的输出变量范围始终在0和1之间)
让机器自己学习,数据集无标签 ,主要有:
T r a i n i n g S e t ↓ Training Set \
downarrow \
T r a i n i n g S e t ↓ L e a r n i n g A l g o r i t h m ↓ Learning Algorithm \
downarrow L e a r n i n g A l g o r i t h m ↓ S i z e o f h o u s e → h → E s t i m a t e d p r i c e Size of house o h o Estimated price S i z e o f h o u s e → h → E s t i m a t e d p r i c e
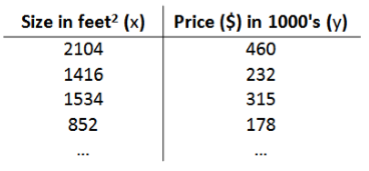
以根据房屋面积预测房价为例对该模型进行解释,训练集如下:
h θ ( x ) = θ 0 + θ 1 x h_{θ}(x) = θ_{0} + θ_{1}x h θ ( x ) = θ 0 + θ 1 x
注:θ i θ_i θ i θ θ θ θ θ θ
J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(θ_{0},θ_{1}) = frac{1}{2m}sum_{i=1}^{m}(h_θ(x^{(i)})-y^{(i)})^2 J ( θ 0 , θ 1 ) = 2 m 1 i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) 2 θ θ θ x ( i ) x^{(i)} x ( i ) y ( i ) y^{(i)} y ( i ) x ( 1 ) x^{(1)} x ( 1 ) y ( 1 ) y^{(1)} y ( 1 )
m i n i m i z e ( θ 0 , θ 1 ) J ( θ 0 , θ 1 ) minimize_{(θ_{0},θ_{1})}J(θ_{0},θ_{1}) m i n i m i z e ( θ 0 , θ 1 ) J ( θ 0 , θ 1 ) J ( θ 0 , θ 1 ) J(θ_{0},θ_{1}) J ( θ 0 , θ 1 )
Batch :Each step of gradient descent use all the training examples.即批梯度下降法每次更新参数θ都使用全部的训练样本数据,看下面梯度下降更新公式的向量形式及向量形式前面的更新公式就可以明白 。
用来最小化代价函数J ( θ 0 , θ 1 ) J(θ_{0},θ_{1}) J ( θ 0 , θ 1 ) 注意 的两点:θ 0 , θ 1 θ_{0},θ_{1} θ 0 , θ 1
t e m p 0 = θ 0 − α ∂ ∂ θ 0 J ( θ 0 , θ 1 ) temp0 = θ_{0} - α fracpartial{partial θ_{0}}J(θ_{0},θ_{1}) t e m p 0 = θ 0 − α ∂ θ 0 ∂ J ( θ 0 , θ 1 ) t e m p 1 = θ 1 − α ∂ ∂ θ 1 J ( θ 0 , θ 1 ) temp1 = θ_{1} - α fracpartial{partial θ_{1}}J(θ_{0},θ_{1}) t e m p 1 = θ 1 − α ∂ θ 1 ∂ J ( θ 0 , θ 1 )
θ 0 = t e m p 0 θ_{0} = temp0 θ 0 = t e m p 0 θ 1 = t e m p 1 θ_{1} = temp1 θ 1 = t e m p 1
(3)J ( θ 0 , θ 1 ) J(θ_{0},θ_{1}) J ( θ 0 , θ 1 )
为了便于进行向量化的运算,在训练数据集的第一列插入一列值全为1的特征,即x 0 ( i ) x_{0}^{(i)} x 0 ( i ) h θ ( x ) = θ 0 + θ 1 x = θ 0 x 0 + θ 1 x 1 h_{θ}(x) = θ_{0} + θ_{1}x = θ_{0}x_{0} + θ_{1}x_1 h θ ( x ) = θ 0 + θ 1 x = θ 0 x 0 + θ 1 x 1 J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( θ 0 x 0 ( i ) + θ 1 x 1 ( i ) − y ( i ) ) 2 J(θ_{0},θ_{1}) = frac{1}{2m}sum_{i=1}^{m}(θ_{0}x_{0} ^{(i)}+ θ_{1}x_1^{(i)}-y^{(i)})^2 J ( θ 0 , θ 1 ) = 2 m 1 i = 1 ∑ m ( θ 0 x 0 ( i ) + θ 1 x 1 ( i ) − y ( i ) ) 2
将此假设函数、代价函数代入到梯度下降法的更新公式中,则有:θ j = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) θ_{j} = θ_{j} - α frac{1}{m}sum_{i=1}^{m}(h_θ(x^{(i)})-y^{(i)})x_{j}^{(i)} θ j = θ j − α m 1 i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) θ j = θ j − α 1 m ( X θ − y ⃗ ) x j θ_{j} = θ_{j} - α frac{1}{m}(Xθ-vec y)x_j θ j = θ j − α m 1 ( X θ − y ) x j X = [ ⋯ ( x ( 1 ) ) T ⋯ ⋯ ( x ( 2 ) ) T ⋯ ⋮ ⋯ ( x ( m ) ) T ⋯ ] , y ⃗ = [ y ( 1 ) y ( 2 ) ⋮ y ( m ) ] X = �egin{bmatrix}
cdots & (x^{(1)})^T & cdots \
cdots & (x^{(2)})^T & cdots \
& vdots & \
cdots & (x^{(m)})^T & cdots
end{bmatrix}, qquad
vec y = �egin{bmatrix}
y^{(1)} \
y^{(2)} \
vdots \
y^{(m)}
end{bmatrix} X = ⎣ ⎢ ⎢ ⎢ ⎡ ⋯ ⋯ ⋯ ( x ( 1 ) ) T ( x ( 2 ) ) T ⋮ ( x ( m ) ) T ⋯ ⋯ ⋯ ⎦ ⎥ ⎥ ⎥ ⎤ , y = ⎣ ⎢ ⎢ ⎢ ⎡ y ( 1 ) y ( 2 ) ⋮ y ( m ) ⎦ ⎥ ⎥ ⎥ ⎤ x ( i ) x^{(i)} x ( i ) y ⃗ vec y y x j x_j x j
向量形式的更新公式更便于梯度下降法的编程实现。