https://zhuanlan.zhihu.com/p/386593288
SMP(Symmetric Multiprocessing)
SMP(对称多处理器)就是多个处理器核心共享一块内存,由一个操作系统负责统一管理多个核心,多个任务运行时,由操作系统根据每个核心的空闲状态,决定某个任务应该运行在哪个CPU核心上,动态调度,实现负载均衡,使CPU使用效率最大化。我们平时使用的电脑和智能手机通常都是SMP架构的,ARM-Linux系统一般也都是SMP架构。
AMP(Asymmetric Multiprocessing)
AMP(非对称多处理器)就是每个处理器核心都是独立的,有自己的内存,各自独立运行程序。程序编译后会分别下载到每个CPU核心,多个CPU核心之间能够相互通信。就像是将多个单独的芯片集成在了同一个封装中。FreeRTOS对AMP架构的芯片也有相应的支持,由于是AMP架构,所以每个CPU核心上都运行了一个FreeRTOS系统和自己的应用程序,FreeRTOS提供了多个CPU核心之间的通信功能。详细信息,可以查看FreeRTOS创始人Richard Barry发表的博文(有针对STM32H745平台的Demo):
[The STM32H745I demo in the FreeRTOS download provides a worked example of the control buffer scheme described below.]
In this post I describe how to implement a basic and light weight core to core communication scheme using FreeRTOS Message Buffers, which are lockless circular buffers that can pass data packets of varying sizes from a single sender to a single receiver. Message buffers just provide the transport for the data - they do not impose any formatting or higher level protocol to which the data must conform.
In the use case described below the sending and receiving tasks are on different cores of a multicore microcontroller (MCU) in an Asymmetric Multi-Processor (AMP) configuration - which means each core runs its own instance of FreeRTOS. The only hardware requirements (other than there being more than one core) are the ability for one core to generate an interrupt in the other core, and for there to be an area of memory that is accessible to both cores (shared memory). The message buffers are placed in the shared memory at an address known to the application running on each core. See figure #1. Ideally there will also be a memory protection unit (MPU) to ensure the Message Buffer can only be accessed through the kernel's Message Buffer API, and preferably mark the shared memory as non cacheable.
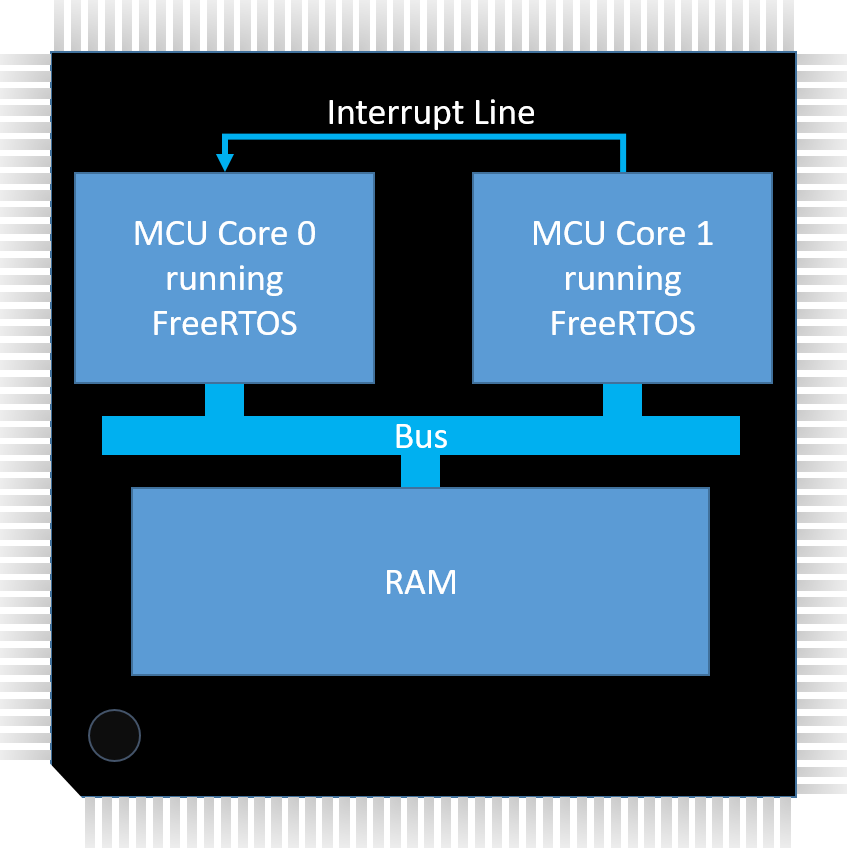
Figure 1: Hardware topology. Click to enlarge.
The following two pseudo code listings show the structure of the API functions used to send to and receive from a message buffer. It can be seen that, in both cases, the calling task can optionally enter the blocked state (so not consuming any CPU cycles) to wait until the operation can complete.
xMessageBufferSend()
{
/* If a time out is specified and there isn't enough
space in the message buffer to send the data, then
enter the blocked state to wait for more space. */
if( time out != 0 )
{
while( there is insufficient space in the buffer &&
not timed out waiting )
{
Enter the blocked state to wait for space in the buffer
}
}
if( there is enough space in the buffer )
{
write data to buffer
sbSEND_COMPLETED()
}
}
Simplified psuedocode for sending data to a stream buffer
|
xMessageBufferReceive()
{
/* If a time out is specified and the buffer doesn't
contain any data that can be read, then enter the
blocked state to wait for the buffer to contain data. */
if( time out != 0 )
{
while( there is no data in the buffer &&
not timed out waiting )
{
Enter the blocked state to wait for data
}
}
if( there is data in the buffer )
{
read data from buffer
sbRECEIVE_COMPLETED()
}
}
Simplified psuedocode for reading data from a stream buffer
|
If a task entered the blocked state in xMessageBufferReceive() to wait for the buffer to contain data then sending data to the buffer must unblock the task so it can complete its operation. The task gets unblocked when xMessageBufferSend() calls sbSEND_COMPLETED(), which is a preprocessor macro.
The default sbSEND_COMPLETED implementation assumes the sending task (or interrupt) and the receiving task are under the control of the same instance of the FreeRTOS kernel and run on the same MCU core. In this AMP example the sending task and the receiving task are under the control of two different instances of the FreeRTOS kernel, and run on different MCU cores, so the default sbSEND_COMPLETED implementation won't work (each FreeRTOS kernel instance only knowns about the tasks under its control). AMP scenarios therefore require the sbSEND_COMPLETED macro (and potentially the sbRECEIVE_COMPLETED macro, see below) to be overridden, which is done by simply providing your own implementation in the project's FreeRTOSConfig.h file. The re-implemented sbSEND_COMPLETED() macro can simply trigger an interrupt in the other MCU core. The interrupt's handler (the ISR that was triggered by one core but executed in another core) must then do the job that would otherwise be done by the default implementation of sbSEND_COMPLETE - namely unblock a task if the task was waiting to receive data from the message buffer that now contains data. The ISR unblocks the task by passing the message buffer's handle as a parameter to the xMessageBufferSendCompletedFromISR() function. This sequence is shown by the numbered arrows in figure 2, where the sending and receiving tasks are on different MCU cores:
- The receiving task attempts to read from an empty message buffer and enters the blocked state to wait for data to arrive.
- The sending task writes data to the message buffer.
- sbSEND_COMPLETED() triggers an interrupt in the core on which the receiving task is executing.
- The interrupt service routine calls xMessageBufferSendCompletedFromISR() to unblock the receiving task, which can now read from the buffer as the buffer is no longer empty.
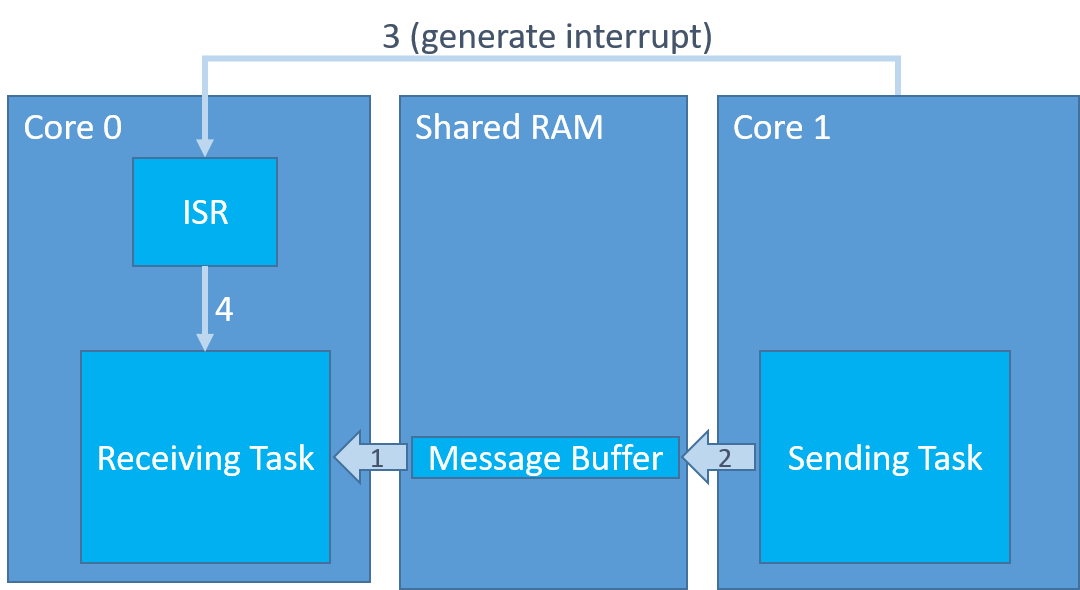
Figure 2: The numbered arrows correspond to the numbered list above, which describes the transfer of one data item through the message buffer. Click to enlarge.
It is easy to pass the handle of the message buffer into xMessageBufferSendCompletedFromISR() when there is only one message buffer, but consider the case where there are two or more message buffers - then the ISR must first determine which of the message buffers contains data. There are several ways this can be done if the number of message buffers is small. For example:
- If the hardware allows then each message buffer can use a different interrupt line, which keeps the one to one mapping between the interrupt service routine and the message buffer.
- The interrupt service routine could simply query each message buffer to see if it contains data.
- Multiple message buffers could be replaced by a single message buffer that passes both metadata (what the message is, what its intended recipient is, etc.) as well as the actual data.
However these techniques are inefficient if there are a large or unknown number of message buffers - in which cases a scalable solution is to introduce a separate control message buffer. As demonstrated by the code below, sbSEND_COMPLETED() uses the control message buffer to pass the handle of the message buffer that contains data into the interrupt service routine.
/* Added to FreeRTOSConfig.h to override the default implementation. */
#define sbSEND_COMPLETED( pxStreamBuffer ) vGenerateCoreToCoreInterrupt( pxStreamBuffer )
/* Implemented in a C file. */
void vGenerateCoreToCoreInterrupt( MessageBufferHandle_t xUpdatedBuffer )
{
size_t BytesWritten;
/* Called by the implementation of sbSEND_COMPLETED() in FreeRTOSConfig.h.
If this function was called because data was written to any message buffer
other than the control message buffer then write the handle of the message
buffer that contains data to the control message buffer, then raise an
interrupt in the other core. If this function was called because data was
written to the control message buffer then do nothing. */
if( xUpdatedBuffer != xControlMessageBuffer )
{
BytesWritten = xMessageBufferSend( xControlMessageBuffer,
&xUpdatedBuffer,
sizeof( xUpdatedBuffer ),
0 );
/* If the bytes could not be written then the control message buffer
is too small! */
configASSERT( BytesWritten == sizeof( xUpdatedBuffer );
/* Generate interrupt in the other core (pseudocode). */
GenerateInterrupt();
}
}
The implementation of sbSEND_COMPLETED() when a control message buffer is used.
|
The ISR then reads the control message buffer to obtain the handle, then passes the handle as a parameter into xMessageBufferSendCompletedFromISR(). See the code listing below.
void InterruptServiceRoutine( void )
{
MessageBufferHandle_t xUpdatedMessageBuffer;
BaseType_t xHigherPriorityTaskWoken = pdFALSE;
/* Receive the handle of the message buffer that contains data from the
control message buffer. Ensure to drain the buffer before returning. */
while( xMessageBufferReceiveFromISR( xControlMessageBuffer,
&xUpdatedMessageBuffer,
sizeof( xUpdatedMessageBuffer ),
&xHigherPriorityTaskWoken )
== sizeof( xUpdatedMessageBuffer ) )
{
/* Call the API function that sends a notification to any task that is
blocked on the xUpdatedMessageBuffer message buffer waiting for data to
arrive. */
xMessageBufferSendCompletedFromISR( xUpdatedMessageBuffer,
&xHigherPriorityTaskWoken );
}
/* Normal FreeRTOS "yield from interrupt" semantics, where
xHigherPriorityTaskWoken is initialised to pdFALSE and will then get set to
pdTRUE if the interrupt unblocks a task that has a priority above that of
the currently executing task. */
portYIELD_FROM_ISR( xHigherPriorityTaskWoken );
}
The implementation of the ISR when a control message buffer is used.
|
Figure 3 shows the sequence when a control message buffer is used. Again the numbered items related to the numbered arrows in the diagram:
- The receiving task attempts to read from an empty message buffer and enters the blocked state to wait for data to arrive.
- The sending task writes data to the message buffer.
- sbSEND_COMPLETED() sends the handle of the message buffer that now contains data to the control message buffer.
- sbSEND_COMPLETED() triggers an interrupt in the core on which the receiving task is executing.
- The interrupt service routine reads the handle of the message buffer that contains data from the control message buffer, then passes the handle into the xMessageBufferSendCompletedFromISR() API function to unblock the receiving task, which can now read from the buffer as the buffer is no longer empty.

Figure 3: The numbered arrows correspond to the numbered list above, which describes the transfer of one data item through one of many message buffers using a control message buffer to allow the ISR to know which message buffer contains data. Click to enlarge.
So far we have only considered the cases where the sending task must unblock the receiving task. If it is possible for a message buffer used for core to core communication to get full, causing the sending task to block, then it is also necessary to consider how the receiving task unblocks the sending task. That can be done by overriding the default implementation of the sbRECEIVE_COMPLETED() in exactly the same way as already described for sbSEND_COMPLETED().
In all cases it is good defensive programming practice to ensure a task never blocks indefinitely on a message queue, in case an interrupt is missed, and always drains a message queue completely, rather than assuming there is one message per interrupt.