REST(representational state transfer) 接口开发 接口规范
幂等:无论操作多少次,请求的结果都是一样的。
安全:访问资源不会对资源发生修改。
POST的不幂等,应该被设计为用于提交修改。
| 接口 | 幂等 | 安全 |
|---|---|---|
| POST | × | × |
| GET | √ | √ |
| HEAD | √ | ? |
| DELETE | √ | × |
| PUT | √ | × |
数据分箱的相关概念以及练习
等宽分箱:可以参考百度回答
800、 1000、 1200 、1500、 1500、 1800、 2000、 2300、 2500、 2800、 3000、 3500、 4000、 4500、 4800、 5000按照宽度为800进行分箱。
就是分为等区间的箱。
- 800、1000、1200、1500、1500
- 1800、2000、2300、2500
- 2800、3000、3500
- 4000、4500、4800
- 5000
K近邻(KNN)
计算原理:
输入不带标签的数据, 将其每个特征与样本数据(带标签分类)对应的特征进行比较。计算新数据与样本每一条数据的距离,对求得的所有距离进行排序。距离小的说明相似。取TopK,K个数据中出现最多的分类标签作为新数据的分类。
决策树
信息熵(香农熵):混乱程度
信息增益:划分数据集前后信息发生的变化。他等于前熵减去后熵,理解起来就是,添加一个特征之后,对于结果确定性的判断影响了多少。信息增益越大,说明该信息越有用,表现为该特征是关键特征。
例子:明天有可能下雨,如果知道了明天阴天,那么下雨的不确定性就会降低很多。
优点:计算复杂度不高,输出易理解。对中间的缺失值不敏感,可以处理不相关特征数据(就是说如果有一些特征对于结果的作用影响不大,那么他们也不会影响决策树的准确构建,同样的道理,我们也很容易知道哪些字段比较重要)。
缺点:难以预测连续的字段
类别较多时,错误增加的可能会比较快(过拟合)。
朴素贝叶斯
贝叶斯分类器,二分类c1、c2。数据是数值型或者bool型。条件概率。新数据(x,y),比较P(c1|x,y)和P(c2|x,y)
朴素贝叶斯基于两个假设:特征独立,并且特征同等重要
就文档分类描述工作原理:
看不懂。。
算法特点:
优点:对少量数据也适用,可以处理多类别问题
缺点:输入数据需要满足数值型或者bool型,往往都需要进行数值转化。
用途案例:社区侮辱性言论屏蔽。
java控制权限,编译时控制,可以通过反射访问私有成员,私有方法
| 关键字 | 类内 | 包内 | 子孙 | 包外 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| default | √ | √ | × | × |
| private | √ | × | × | × |
字符串的比较都是用equals比较,不用==
Integer和int的区别
null和0
一个是封装的类,一个是基本数据类型
前者可以表达书未赋值和赋值为0的区别。int不能表达出未赋值的意思。
抽象类和普通类的区别:不能创建类的实例,允许有抽象方法。
java深拷贝和浅拷贝
深拷贝实现cloneable接口,重写clone方法
实现彻底的深拷贝需要逐步重写clone方法
内部类:
成员内部类 :类似于成员变量
方法内部类 :只能访问方法中定义的final类型的变量
匿名内部类 :实际上也是方法内部类的一种。特点是只能实例化一次,而且没有名字。需要继承一个基类,但是不使用extends关键字。或是实现一个接口,也不使用implements关键字。
this.getClass().getName();
super.getClass().getName();
//两句等效。
super.getClass().getName();
this.getClass().getSuperClass().getName();//这个才能获取到父类的名字。因为getClass()方法是Object基类的一个final方法。super.getClass()和this.getClass()访问的实际上都是Object的getClass()方法,是同一个。getClass()用于获取当前运行类的名字。获取父类需要用getSuperClass()
关于try{return;}catch{}finally{return;} try中返回只是将值存在函数栈,继续执行finally中的return ,更新了值。之后返回控制权。
final finally finalize区别:
final关键字 用于修饰
finally总是执行 捕获异常时使用
finalize是Object的一个方法。是垃圾回收期调用,用来回收资源使用的。可以重写。
创建线程的两种方式:
继承Thread类:
MyThread mthread=new MyThread();
mthread.start();
实现Runable接口
MyThread mthread=new MyThread();
new Thread(mthread).start();
servlet
继承HttpServlet
doGet(HttpServletRequest,HttpServletResponse)
生命周期
- init() 初始化
- service() 处理客户端请求。检查请求类型(put,get,post,delete)
- doXX 比如doGet,doPost..
- destory()
软件开发模型
-
迭代模型
-
螺旋模型
何时使用:大系统风险大,需求不明
可以看做是每个阶段都事先加了风险分析的快速原型模型。一圈一圈螺旋线。 -
增量模型
-
快速原型模型
何时使用:需求不明确时
特点:可以跟客户进行全面的沟通,获取更为详细明确的需求和需求变化。原型开发简单,周期短,经济。
过程见图:
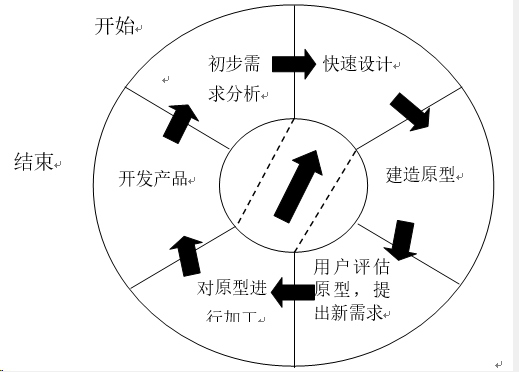
-
瀑布模型
何时使用:大系统风险小
特点:经典,老套;前一阶段的输出作为下一阶段的输入,顺序性和依赖性;每个阶段都要交付合格的文档;如果用户需求突然变更会很头疼。
过程: 可行性研究 ->需求分析->概要设计 ->详细设计 ->编码以及单元测试->测试
冯诺依曼体系结构
存储器:存放数据和程序
控制器:控制指挥程序和数据的输入运行,处理运算结果
运算器:完成算数运算和逻辑运算,并暂存中间结果
输入:键盘,鼠标
输出:显示器

线程池,说一下线程池工作原理,任务拒接策略有哪几种
首先说一下线程池的意义:
执行一个任务的耗时,包含三个部分:T1创建线程,T2执行任务,T3销毁线程。如果T1+T3的时间远大于T2,那么创建并维护一个线程池来管理线程就很有必要了,对于提升服务性能有很大的帮助。重复利用闲置线程,尽量避免创建和销毁线程的耗时操作。
常见线程池的类型:
newSingleThreadExecutor池中单线程工作
newFixedThreadExecutor池中的线程数固定。池满,新任务则等待。
newCacheThreadExecutor重点在于,空闲线程超过固定时间之后,会被回收。当需要新的线程还会重新创建。
newScheduleThreadExecutor线程数无限。
java提供了一个java.util.concurrent.Executors工具类用于创建线程池。读其源码,可以看到它实际上是通过 ThreadPoolExecutor 在创建线程池。
看ThreadPoolExecutor的构造方法:
public ThreadPoolExecutor(int corePoolSize,//即使没有任务,依然存在的线程(等候任务的分配)。
int maximumPoolSize,//哪怕任务再多,也不能分配更多的线程(考虑机器性能有上限)
long keepAliveTime,//空转线程(非核心线程)最长空转时间,自动销毁。
TimeUnit unit,//指定存活时间的单位
BlockingQueue<Runnable> workQueue,//提交的任务都在队列中。阻塞队列。队列内的任务数存在上限。
ThreadFactory threadFactory,
RejectedExecutionHandler handler//拒绝策略,当线程池满了,并且队列也是满的时候,会调用,拒绝执行该任务。
) {
if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
任务提交执行流程:
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {//如果当前活跃线程数小于核心线程数,则可以直接创建线程执行任务(addworker())
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {//将任务添加到阻塞队列,并且添加成功
int recheck = ctl.get();//再次检查
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))//添加到阻塞队列失败。执行拒绝策略
reject(command);
总的来说:新任务到来,首先检查当前活跃线程数是否小于核心线程数,小于,则获取线程并执行任务,不小于,则再判断阻塞队列是否已满,不满,则添加任务入队列等待执行,满了,则判断线程池是否满了,如果未满,则创建线程执行任务,满了则拒绝任务执行。
拒绝策略的种类(内置四种):
- discardpolicy 直接抛弃,不执行任务
- DiscardOldestPolicy 抛出队列中最老的任务,并尝试重新运行刚提交的任务
- abortpolicy(默认) 不执行任务并抛出异常RejectedExecutionException。需要try catch。
- callerRunspolicy 线程池没有资源了,本来想让别人帮忙干活的,现在只能自己干了。会造成当前线程的阻塞。
进程和线程的区别
我们写的代码,都可以称为是一个程序,一个程序的运行,至少需要一个进程,一个进程至少需要一个线程。
多个进程之间有独立的内存单元,互不干扰,而线程之间共享内存。所以就会有经常遇到的线程安全,同步等问题。
进程是系统进行资源分配和资源调度的一个独立单位。
线程是CPU进行调度和分配的单位。
线程同步的方式有哪些?
事务的四大特性ACID
A:原子性。事务中所有的操作要么成功,要么全部失败回滚到操作之前。
C:一致性。事务必须要使数据库从一个一致性状态转到另一个一致性状态。怎么理解这个一致性?比如说转账,两个人的总额是10000,不管怎么来回转,最终的操作结果必定满足总额还是10000.
I:isolation隔离性。事务的操作不会被外界操作或者别的事务操作所影响。特别是在遭遇并发的时候,事务的隔离级别参考下面。
D:持久性。事务一旦提交,作出的更改就是永久性的。
事务的隔离级别
如果没有事务隔离性,会发生以下情况:
脏读:举个例子,A向B转账。A的所有操作都在一个事务中,事务中包含两个操作+100和-100。在+100之后,事务暂未提交,此时B那边查账会发现确实有100转进来,而当A提交事务之后,-100执行。B再查账会发现余额为0。所谓脏读,就是一个事务中读取了另一个未提交的事务的数据。
不可重复读:见下面一段话。
幻读:见下。
幻读和不可重复读都是读取了已经提交的事务数据。脏读读取的是未提交的事务数据。不可重复读针对的hi同一个数据项,两次读取的结果不一样。幻读是针对一批数据,事务A提交了修改,同时事务B也提交了修改,但是如果此时A再查询的话,会发现,“咦,我明明已经完成修改了,怎么还有不符合我修改之后的数据项啊?”实际上这是事务B在捣鬼。
Serializable串行化:隔离最高。同时避免三种错误。
Repeatable read可重复读:可以避免脏读和不可重复读。
Read committed读已提交(读取的数据是已经提交的):可以避免脏读。(常见的默认隔离级别)
Read unconmmited读未提交(会发生读取未提交的数据):隔离最低
请在事务开启之前,设置隔离级别
mysql>set transaction isolation level repeatable read;//设置隔离级别
mysql>select @@tx_isolation;//查询当前隔离级别
Hive的特点说一下
Hive是基于hdfs建立的数据仓库, 将数据文件存成一张表,称为元数据, 记录表的所属的数据库, 表的字段等信息。 具有类似sql的查询功能,面对较大的数据查询,其将sql自动转为MR的操作可以充分利用集群的计算资源进行查询,自动转化,不用另行编写MR代码。
JVM研究
GC部分
类加载部分
java类装载到JVM中有两种方式,隐式装载(比如new对象的时候),显式装载。
常用以下有四种classLoader
- BootStrap ClassLoader 引导类加载器 主要用于加载 /jre/lib、/jre/classes目录下的核心类库。这是最顶层的一个加载器,使用C++编写的。
- Extention ClassLoader 扩展类加载器 负责加载/JAVA_HOME/lib/ext/类库
- Application ClassLoader 应用类加载器 主要负责加载CLASSPATH下的类库和我们自己的java代码编译出来的class文件。
除了引导加载器获取不到外(因为是用C++写的),其他的加载器我们都能通过代码查询到。 - 自定义加载器 需要继承classloader类
public class Test_ClassLoader {
public static void main(String[] args){
System.out.println(Test_ClassLoader.class.getClassLoader());
System.out.println(Test_ClassLoader.class.getClassLoader().getParent());
System.out.println(Test_ClassLoader.class.getClassLoader().getParent().getParent());
}
}
outout:
sun.misc.Launcher$AppClassLoader@58644d46
sun.misc.Launcher$ExtClassLoader@4554617c
null
Process finished with exit code 0
一份java源码从产生到被运行的流程
0. 首先.java文件只有编译成class字节码文件之后才能被类加载器读取,加载到JVM中。
- 检查类是否被加载,从上往下找。
- 装载:导入class文件
- 检查文件的是否有错,分析文件,给静态变量分配空间。
- 初始化,主要是静态变量,静态代码块的初始化
=====================
我的其他相关文章:
欢迎关注微信公众号“IT客“
