谈谈你对浏览器内核的认识?
负责对网页语法的解释(如标准通用标记语言下的一个应用HTML、JavaScript)并渲染(显示)网页。 所以,通常所谓的浏览器内核也就是浏览器所采用的渲染引擎,渲染引擎决定了浏览器如何显示网页的内容以及页面的格式信息。不同的浏览器内核对网页编写语法的解释也有不同,因此同一网页在不同的内核的浏览器里的渲染(显示)效果也可能不同,这也是网页编写者需要在不同内核的浏览器中测试网页显示效果的原因。--摘自百度百科
-
Trident [ˈtraɪdnt] 三叉戟
IE内核,是一款开放的内核,其接口内核设计的非常成熟,所以才有因此才有许多采用IE内核而非IE的浏览器(壳浏览器)涌现。
因自身的”垄断性“导致有段时间没有更新,曾几乎与W3C标准脱节以及大量BUG等安全性问题没有得到及时解决,因此开始有了非Trident内核浏览器的兴起。
CSS兼容前缀: -ms-
-
Gecko [ˈgekəʊ] 壁虎
Mozilla Firefox内核,开源内核。CSS兼容前缀:-moz-
-
Presto [ˈprestəʊ] 急板
Opera前内核(已废弃),特点是渲染速度的优化达到了极致,然而代价是牺牲了网页的兼容性。属商业引擎。Opera现改为Google的Blink内核。CSS兼容前缀:-o-
-
Webkit
Google chrome和safari的开源内核,是苹果公司自己的内核,Webkit引擎包含WebCore排版引擎及JavaScriptCore解析引擎。CSS兼容前缀:-webkit-
-
Blink
Blink是一个由Google和Opera Software开发的浏览器排版引擎,此举欲降低Webkit即苹果在浏览器市场的影响力。
-
Servo
Mozilla与三星达成合作协议开发“下一代”浏览器渲染引擎Servo。
JS中的基本数据类型
JS 的 number 类型是浮点类型的,在使用中会遇到某些 Bug,比如 0.1 + 0.2 !== 0.3。
string 类型是不可变的,无论你在 string 类型上调用何种方法,都不会对值有改变。
对于 null 来说,很多人会认为他是个对象类型,其实这是错误的。虽然 typeof null 会输出 object,但是这只是 JS 存在的一个悠久 Bug。最直接的体现就是null === null。
NaN是属于number类型的,但是NaN !== NaN,所以在判断重复的时候需要用到isNaN函数。
基本数据类型和引用数据类型是如何存储的
基本数据类型存储的是值,引用数据类型存储的是指针,它指向这个类型值在内存里保存的地址。
它们的存储位置是不同的,先了解堆和栈这两个基本数据结构:
- 栈:只允许在一段进行插入或者删除操作的线性表,是一种先进后出的数据结构。
- 堆:基于散列算法的数据结构。
基本数据类型都是一些简单的数据段,它们是存储在栈内存中。
引用数据类型是保存在堆内存中的,然后再栈内存中保存一个对堆内存中实际对象的引用。所以,JavaScript中对引用数据类型的操作都是操作对象的引用而不是实际的对象。
这样设置的好处在于:
- 堆比栈大,栈比堆速度快。
- 基础数据类型比较稳定,而且相对来说占用的内存小。
- 引用数据类型大小是动态的,而且是无限的。
- 堆内存是无序存储,可以根据引用直接获取
函数参数是对象会发生什么问题
- 函数传参是传递对象指针的副本
- 在函数内部对于对象的属性的改变是能够反映到原对象上去的
- 在函数内部给参数重新分配对象不会反映到原指针上面去,这一点跟把全局变量作为参数传到函数中,无论函数内部对这个参数如何改变也不会反映到真实的全局变量上面去一个道理
如下题:
function test(person) {
person.age = 26
person = {
name: 'yyy',
age: 30
}
return person
}
const p1 = {
name: 'yck',
age: 25
}
const p2 = test(p1)
console.log(p1) // -> {name:'yck', age: 26}
console.log(p2) // -> {name:'yyy', age: 30}
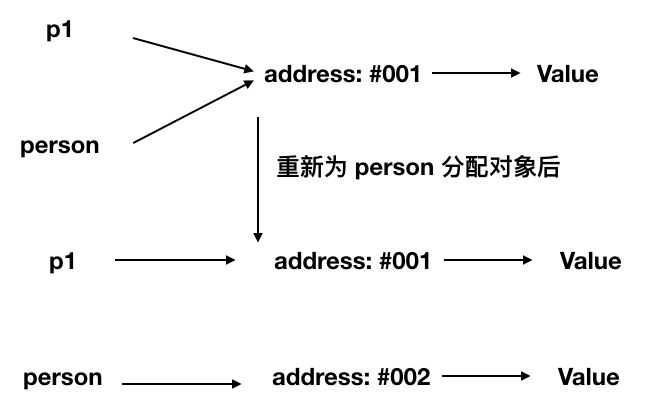
为什么基本数据类型会拥有toString()之类的方法?
ECMAScript提供了三个特殊的引用类型Boolean、String、Number,我们称这三个特殊的引用类型为基本包装类型,也叫包装对象。当调用基本数据类型的方法时JS会根据其类型构建一个相应的实例对象(例如let str = new String("hello world")),在这个实例对象上去调用对应方法,在调用完方法后就会销毁这个实例对象。因此这就能够解释为什么基本数据类型不能添加属性和方法,以及基本数据类型调用任何方法也不会改变它自身。
垃圾收集
垃圾收集机制的原理: 找出那些不再继续使用的变量,然后释放其占用的内存。垃圾收集器会按照固定的时间间隔,周期性地执行这一操作。具体到不同浏览器中的实现,通常有两个策略。
1.标记清除
当变量进入环境时候就将这个变量标记为“进入环境”(不能释放内存,环境中可能会用到它们),当变量离开环境时,则将其标记为“离开环境”(可释放内存)。
2.引用计数
跟踪记录每个值被引用的次数,每被引用一次次数+1,取消被引用次数-1。当这个值的引用次数为0的时候就将其占用的内存空间回收回来。
但是这种策略有个弊端,如果存在两个变量相互引用的情况下(循环引用),即使脱离了环境也不能被垃圾回收机制来清除。