摘要
代码克隆(code clone)是指那些具有相似语义但语法上可能不同代码片段。检测代码克隆可以减少软件维护的花费,防止在未来出现过多的错误。但是在过去的二十年里,大多数的检测方法没有检测语义克隆。最近的研究都是在尝试利用抽象语法树,在树上做LSTM。但是它没有充分利用代码片段的结构信息,因此限制了检测能力。
本文
- 提出了一个新方法,基于树卷积来检测语义克隆,即利用AST捕获结构信息,从代码标记获取词法信息。
- 提出了一个新的embeddng技术,位置感应的embedding技术,本质上,将任何标记视为字符one-hot embeddings的位置加权组合???没看懂??需要看原
介绍
代码克隆的出现,主要来自于程序员的复制粘贴行为或者不同的开发者实现了相同的函数。
通常代码克隆被认为有4种类型,前3种认为与文本相似度有关,第4种是功能相似。第4种的克隆是最难检测的,因为它们包括在语法上高度不同但仍然执行相同功能的克隆。比如排序算法,冒泡排序和快排。一般分为:: Very-Strong Type-3, Strong Type3, Moderately Type-3, and Weak Type-3/Type-4。在本文的其余部种,我们将两个最难于检测的克隆类别称为semantic clones语义克隆。
Wei and Li提出了一个基于深度学习的检测方法,CDLH,该方法利用word2vec来捕获文本信息,然后利用LSTM训练AST。
但是作者认为:该方法虽然利用AST得到了结构信息,但是没有考虑节点的类型信息。
依然存在的问题,对高度不同的代码片段缺乏泛化能力,很同意!
作者将高度不同的代码片段称为 unseen data。
模型
总体流程

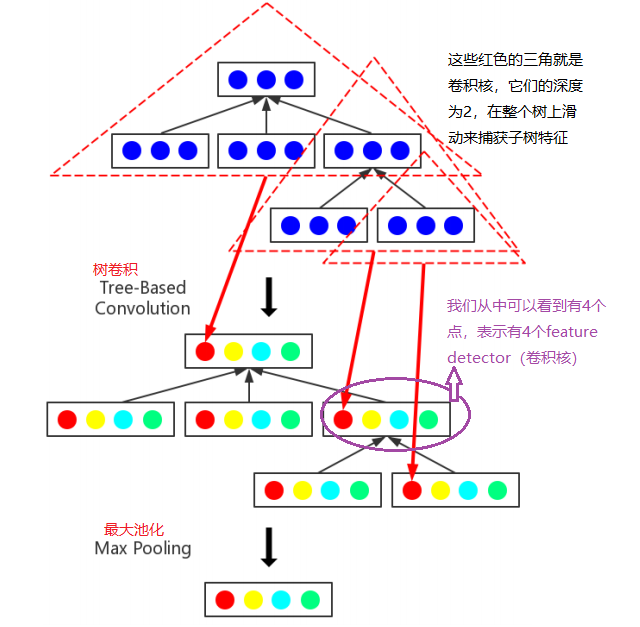
Tree-Based Convolution and Max Pooling
常见的卷积核都是正方形的,但是基于树的卷积是三角形的。基于树的卷积输出为
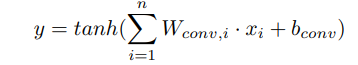
Continuous Binary Tree
此时,基于树的卷积有一个问题,自然语言中的语法树子节点的限制为2,但是AST是没有这种限制的,这会导致上式中的$W_{conv,i}$的数量无法确定。一种通用的做法是根据某种规则将其转换成满二叉树,然而,在这个过程很多的结构信息将会丢失。作者想出了"binary" tree,它可以忽略树的大小和形状。
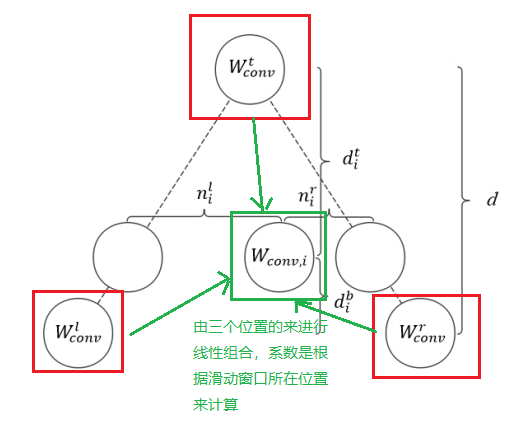
下面就是系数的线性组合公式

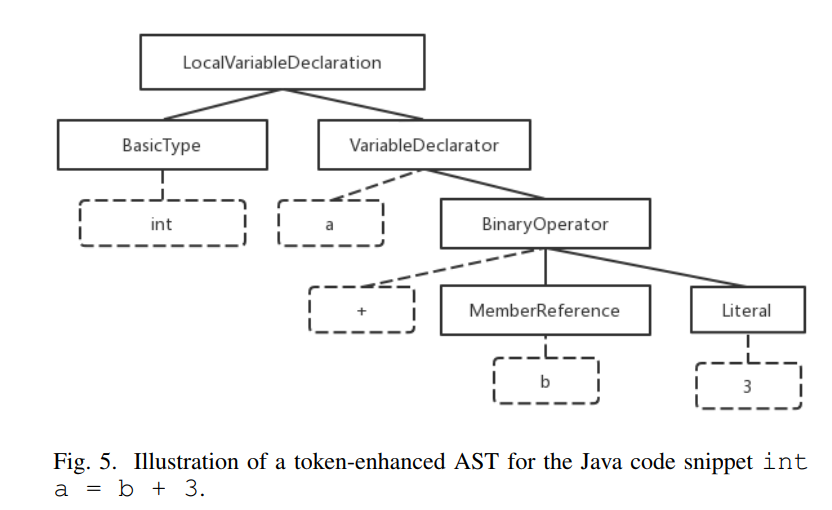
Token-Enhanced AST (AST+)
利用语义信息补充AST。
token增强的部分用虚线表示出来,具体来说,我们将代码片段中的每个标记作为子节点添加到原始AST中相应的AST节点,并为子节点分配一个与AST节点的向量维数相同的向量,然后在这个AST+上做树卷积,利用word2vec初始化the token embedding
Position-Aware Character Embedding (PACE)
在自然语言处理中,词表的大小虽然很大,但是选取的全部都是常用词汇,不常用的用"<UNK>"来替代,但是程序语言的标识符是无限的,如果按照常规的词表大小就会有太多的"<UNK>",于是存在了一个两难的问题,即增加词表的大小,避免"<UNK>",但会使网络训练困难。即使标记的词汇表非常大,模型仍然可能不能推广到使用词汇表外标记的源代码
提出一种新的embedding技术,可以有位置感应。
首先,我们资源代码中所有的token拿出来,然后得到一个token集合,这个集合的charactor是独特的,唯一的。将这些characters 进行one-hot编码。
对于一个token,假设它包含k个字符,分别为$c_1,c_2,c_3,...c_k$
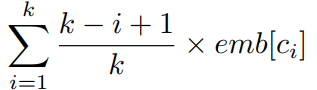
![]()
$emb[c_i]$是$c_i$的one-hot编码.
作者认为在Java代码中LinkedList and ArrayList ,是不需要训练一个语言模型来知道它们具有相同的语义,因为我们可以看到,它们有相同的字符,并且以相同的顺序出现。