Summary
写完笔记之后最后填,概述文章的内容,以后查阅笔记的时候先看这一段。
Research Objective
现在的推荐系统虽然加入了很多的side information,但是他们的工作犹如一个黑盒子,不知道为什么要去推荐,作者通过利用基于树的方法提高推荐系统的可解释性
Problem Statement
问题陈述,要解决什么问题?
Method(s)
解决问题的方法/算法是什么?
作者提出了一个新奇的解决方法:Tree-enhanced Embedding Method,它结合了Tree-base和embedding-base的优点。我们首先利用tree-base方法从丰富的信息中获取决策规则,接下来我们设计了一个embedding模型,可以结合一些特征以及一些userID和itemID中不可见的特征。我们模型的核心部分是一个容易解释的注意力网络,让推荐系统透明,可解释。
预测模型
该预测模型的公式为
![模型预测公式]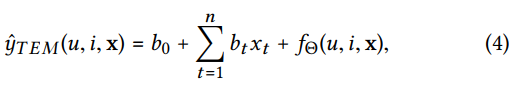
其中(u)表示用户,(i)表示item,(x)是他们的特征向量,即([x_u,x_i]=xinBbb{R}^n)
构造交叉特征
由于交叉后的特征数量巨大,连提取都很困难,更别说去学习了,在工业界常常是利用手工提取,然后再放到模型之中去学习。
作者利用GBDT来自动的提取有用的交叉特征,虽然GBDT不是用来提取交叉特征的,但是它的叶子节点是通过交叉特征来构造的,所以我们可以认为叶子节点是非常有用的交叉特征,并将其用来预测。
最终,利用一系列的决策树来表示一个GBDT,(Q=lbrace{Q_1,...Q_2
brace}),每个树的叶子节点都对应着一个特征向量。使用(L_s)来代表第s个树的叶子节点数量。与原始的GBDT不同的是,原来的都是将权值相加作为预测,我们将他的交叉特征输入到注意力模型之中,以便更有效的预测。
利用一个multi-hot向量q来表示交叉特征,它是由多个one-hot串联。
利用交叉特征进行预测
Facebook利用的是GDBT+LR模型,这个模型虽然能捕获重要的交叉特征,但是它给每一对(user,item)分配了相同的权重,这在真实的世界中是不可取的。
有时常常利用隐藏层的全连接来获取权重,虽然在性能上有很大的提升,但是全连接层中的权重无法解释。
为了让模型保持性能并可解释,作者解释了TEM模型模型中的2个基本要素,embedding和attention
Embedding
对于给定的交叉特征向量q,将每个交叉特征j放入到embendding向量(v_jinBbb{R}^k)中,其中k是embeding的大小,在进行了这一系列的操作后,我们得到了一系列的embedding向量(V=lbrace{q_1v_1,..,q_{L} v_L brace}),(q)是一个稀疏向量仅有少量的非0元素,我们只需要为预测包含非零特性的embedding。我们使用(p_u)和(q_i)表示用户和项目的embedding.
Evaluation
作者如何评估自己的方法,有没有问题或者可以借鉴的地方。
利用了 tourist attraction and restaurant recommendation,提高推荐系统的可解释性。
Conclusion
作者给了哪些strong conclusion, 又给了哪些weak conclusion?
Notes
在这些框架外额外需要记录的笔记。