一、特征选择方法分类
1、特征选择也是对数据进行预处理的一个步骤,在进行特征选择的时候我们有以下两个原则,即指导方向:
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除移除低方差法外,本文介绍的其他方法均从相关性考虑。
2、特征选择主要有两个目的:
- 减少特征数量、降维,避免维度灾难,这样能使模型泛化能力更强,减少过拟合,缩短模型训练时间。
- 增强对特征和特征值之间的理解
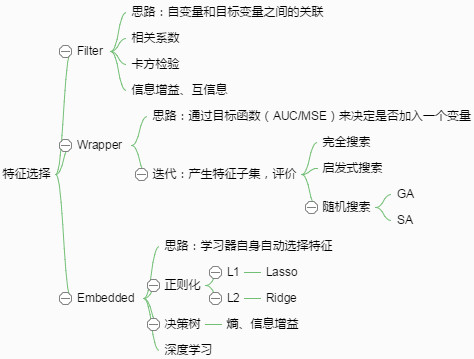
3、根据特征选择的形式又可以将特征选择方法分为3类:
1)Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。特征选择过程与后续学习器无关,先用特征选择过程对特征进行“过滤”,再用过滤后的特征来训练模型。根据相关性值排序
2)Wrapper:包装法,根据要使用的学习器性能评分,每次选择若干特征,或者排除若干特征。包装法特征选择的目的就是为给定的学习器“量身定做”的特征子集。贪心或者穷举搜索
3)Embedded:嵌入法,嵌入式特征选择是在学习器训练过程中自动进行了特征选择。根据特征权重系数排序
其中1不需要训练,直接计算某些可以反映相关性值排序即可,2和3需要进行模型训练,且2需要多次进行模型训练;1和2是特征选择过程与学习器训练过程分开,3是合二为一,在学习器训练过程中自动进行了特征选择。
二、递归特征消除(Recursive feature elimination)
RFE递归特征消除法:递归特征消除是包装法的一种,它的主要思想是反复构建模型,然后选出最好的(或者最差的)特征(根据系数来选),把选出来的特征放到一边,然后在剩余的特征上重复这个过程(如果是选取最好的,本轮选出的特征是否基于选定集,这是一个问题),直到遍历了所有的特征。在这个过程中被消除的次序就是特征的排序。
RFECV 交叉验证的方式递归特征消除法:是通过交叉验证的方式执行RFE,以此来选择最佳数量的特征:
- 穷举法:对于一个数量为d的feature的集合,他的所有的子集的个数是2的d次方减1(包含空集)。指定一个外部的学习算法,比如SVM之类的。通过该算法计算所有子集的validation error。选择error最小的那个子集作为所挑选的特征。——使用穷举法列举出属性子集的所有情况,使用指定算法求其得分,选择得分最高的子集。
- 贪心法:对于给定的特征集合{a1,a2,a3,...ad},首先可以将每一个特征看作一个候选子集,利用学习器对这d个候选子集进行评价,假设{a2}最优,于是将{a2}作为第一轮的选定集;然后,在上一轮的选定集中加入一个特征。构成包含两个特征的候选集,假定在这d-1个候选两特征集中{a2,a4}最优,且优于{a2},则{a2,a4}作为本轮的选定集;...假设在第k+1轮时,最优候选(k+1)特征集不如上一轮的选定集,则停止生成候选子集,并将上一轮选定的k特征集作为特征选择的结果。这种叫向前(forward)搜索。 类似,若从完整的特征集开始,每次尝试去掉一个无关特征,这样主键减少特征的策略叫向后(backward)搜索。还可将向前和向后搜索结合起来,每轮逐渐增加选定集特征个数(这些特征在后续轮中确定不会被移除),同时减少无关特征,这种策略叫“双向”(bidirectional)搜索。