注:此代码仅用于个人爱好学习使用,不涉及任何商业行为!
话不多说,直接上代码:


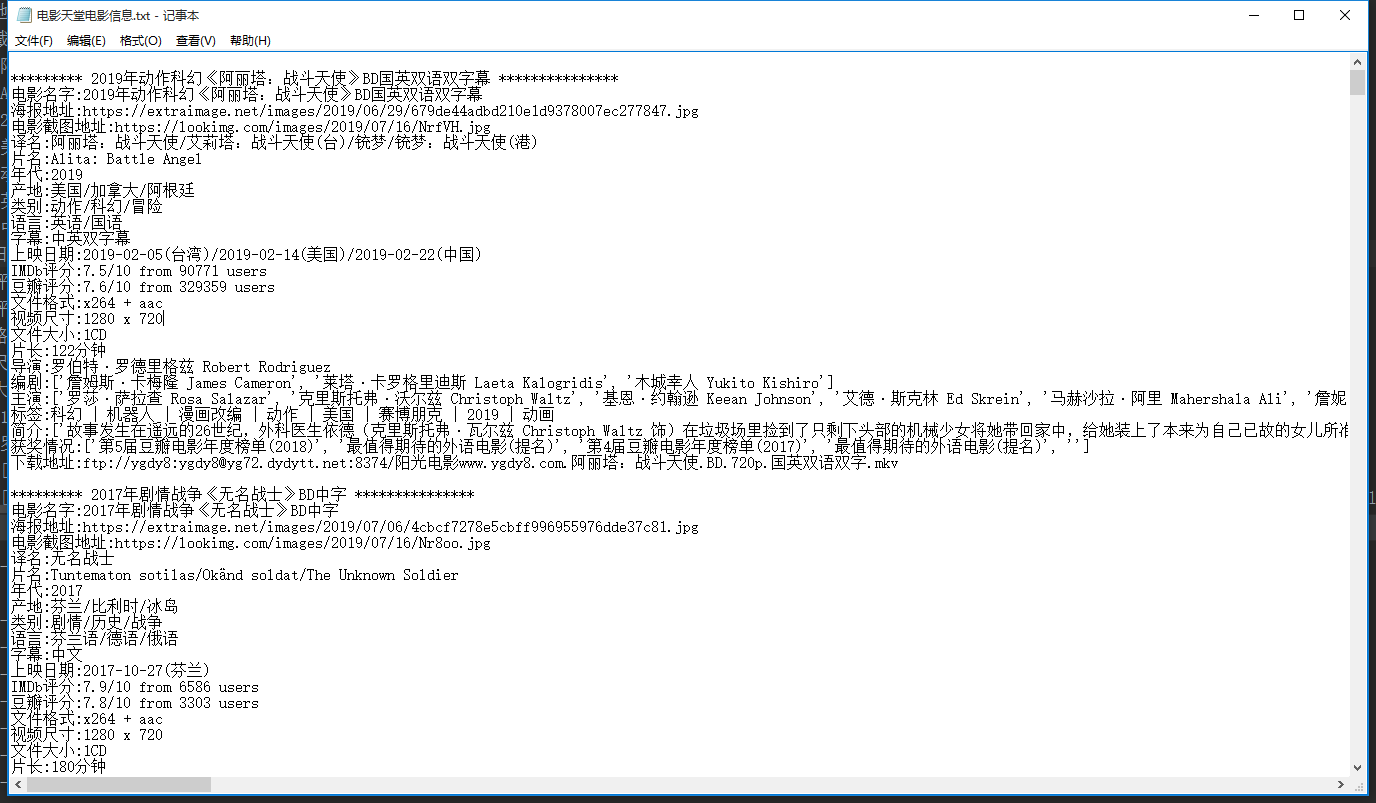
1 #!/user/bin env python 2 # author:Simple-Sir 3 # time:2019/7/20 20:36 4 # 获取电影天堂详细信息 5 import requests 6 from lxml import etree 7 8 # 伪装浏览器 9 HEADERS ={ 10 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 11 } 12 # 定义全局变量 13 BASE_DOMAIN = 'https://www.dytt8.net' 14 # 获取首页网页信息并解析 15 def getUrlText(url,coding): 16 respons = requests.get(url,headers=HEADERS) # 获取网页信息 17 # enc = respons.encoding 18 # urlText = respons.content.decode('gbk') 19 if(coding=='c'): 20 urlText = respons.content.decode('gbk') 21 html = etree.HTML(urlText) # 使用lxml解析网页 22 else: 23 urlText = respons.text 24 html = etree.HTML(urlText) # 使用lxml解析网页 25 return html 26 27 # 获取电影详情页的href,text解析 28 def getHref(url): 29 html = getUrlText(url,'t') 30 aHref = html.xpath('//table[@class="tbspan"]//a/@href') 31 htmlAll = map(lambda url:BASE_DOMAIN+url,aHref) # 给每个href补充BASE_DOMAIN 32 return htmlAll 33 34 # 使用content解析电影详情页,并获取详细信息数据 35 def getPage(url): 36 html = getUrlText(url,'c') 37 moveInfo = {} # 定义电影信息字典 38 mName = html.xpath('//div[@class="title_all"]//font[@color="#07519a"]/text()')[0] 39 moveInfo['电影名字'] = mName 40 mDiv = html.xpath('//div[@id="Zoom"]')[0] 41 mImgSrc = mDiv.xpath('.//img/@src') 42 moveInfo['海报地址'] = mImgSrc[0] # 获取海报src地址 43 if len(mImgSrc) >= 2: 44 moveInfo['电影截图地址'] = mImgSrc[1] # 获取电影截图src地址 45 mContnent = mDiv.xpath('.//text()') 46 def pares_info(info,rule): 47 ''' 48 :param info: 字符串 49 :param rule: 替换字串 50 :return: 指定字符串替换为空,并剔除左右空格 51 ''' 52 return info.replace(rule,'').strip() 53 for index,t in enumerate(mContnent): 54 if t.startswith('◎译 名'): 55 name = pares_info(t,'◎译 名') 56 moveInfo['译名']=name 57 elif t.startswith('◎片 名'): 58 name = pares_info(t,'◎片 名') 59 moveInfo['片名']=name 60 elif t.startswith('◎年 代'): 61 name = pares_info(t,'◎年 代') 62 moveInfo['年代']=name 63 elif t.startswith('◎产 地'): 64 name = pares_info(t,'◎产 地') 65 moveInfo['产地']=name 66 elif t.startswith('◎类 别'): 67 name = pares_info(t,'◎类 别') 68 moveInfo['类别']=name 69 elif t.startswith('◎语 言'): 70 name = pares_info(t,'◎语 言') 71 moveInfo['语言']=name 72 elif t.startswith('◎字 幕'): 73 name = pares_info(t,'◎字 幕') 74 moveInfo['字幕']=name 75 elif t.startswith('◎上映日期'): 76 name = pares_info(t,'◎上映日期') 77 moveInfo['上映日期']=name 78 elif t.startswith('◎IMDb评分'): 79 name = pares_info(t,'◎IMDb评分') 80 moveInfo['IMDb评分']=name 81 elif t.startswith('◎豆瓣评分'): 82 name = pares_info(t,'◎豆瓣评分') 83 moveInfo['豆瓣评分']=name 84 elif t.startswith('◎文件格式'): 85 name = pares_info(t,'◎文件格式') 86 moveInfo['文件格式']=name 87 elif t.startswith('◎视频尺寸'): 88 name = pares_info(t,'◎视频尺寸') 89 moveInfo['视频尺寸']=name 90 elif t.startswith('◎文件大小'): 91 name = pares_info(t,'◎文件大小') 92 moveInfo['文件大小']=name 93 elif t.startswith('◎片 长'): 94 name = pares_info(t,'◎片 长') 95 moveInfo['片长']=name 96 elif t.startswith('◎导 演'): 97 name = pares_info(t,'◎导 演') 98 moveInfo['导演']=name 99 elif t.startswith('◎编 剧'): 100 name = pares_info(t, '◎编 剧') 101 writers = [name] 102 for i in range(index + 1, len(mContnent)): 103 writer = mContnent[i].strip() 104 if writer.startswith('◎'): 105 break 106 writers.append(writer) 107 moveInfo['编剧'] = writers 108 elif t.startswith('◎主 演'): 109 name = pares_info(t, '◎主 演') 110 actors = [name] 111 for i in range(index+1,len(mContnent)): 112 actor = mContnent[i].strip() 113 if actor.startswith('◎'): 114 break 115 actors.append(actor) 116 moveInfo['主演'] = actors 117 elif t.startswith('◎标 签'): 118 name = pares_info(t,'◎标 签') 119 moveInfo['标签']=name 120 elif t.startswith('◎简 介'): 121 name = pares_info(t,'◎简 介') 122 profiles = [] 123 for i in range(index + 1, len(mContnent)): 124 profile = mContnent[i].strip() 125 if profile.startswith('◎获奖情况') or '【下载地址】' in profile: 126 break 127 profiles.append(profile) 128 moveInfo['简介']=profiles 129 elif t.startswith('◎获奖情况'): 130 name = pares_info(t,'◎获奖情况') 131 awards = [] 132 for i in range(index + 1, len(mContnent)): 133 award = mContnent[i].strip() 134 if '【下载地址】' in award: 135 break 136 awards.append(award) 137 moveInfo['获奖情况']=awards 138 downUrl = html.xpath('//td[@bgcolor="#fdfddf"]/a/@href')[0] 139 moveInfo['下载地址'] = downUrl 140 return moveInfo 141 142 # 获取前n页所有电影的详情页href 143 def spider(): 144 base_url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html' 145 moves = [] 146 m = int(input('请输入您要获取的开始页:')) 147 n = int(input('请输入您要获取的结束页:')) 148 print('即将写入第{}页到第{}页的电影信息,请稍后...'.format(m, n)) 149 for i in range(m,n+1): 150 print('******* 第{}页电影 正在写入 ********'.format(i)) 151 url = base_url.format(i) 152 moveHref = getHref(url) 153 for index,mhref in enumerate(moveHref): 154 print('---- 第{}部电影 正在写入----'.format(index+1)) 155 move = getPage(mhref) 156 moves.append(move) 157 # 将电影信息写入本地本件 158 for i in moves: 159 with open('电影天堂电影信息.txt', 'a+', encoding='utf-8') as f: 160 f.write(' ********* {} *************** '.format(i['电影名字'])) 161 for info in i: 162 with open('电影天堂电影信息.txt','a+',encoding='utf-8') as f: 163 f.write('{}:{} '.format(info,i[info])) 164 print('写入完成!') 165 166 if __name__ == '__main__': 167 spider()
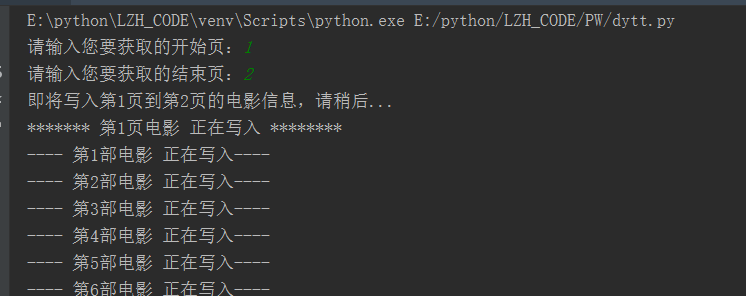
执行情况:

结果文件: