最近一直在学习使用GLSL,国外有两个非常好的资源网站 shadertoy 和 glslsandbox。里面有很多关于glsl的案例,网站维护也都是一些圈里的大神在做着,如果有想法学习比较底层的shader可以看看这两个网站。
这里主要讲一讲通过在Houdini里面用grid做画板,通过编写VEX代码来实现GLSL中fragment shader的原理。所谓的fragment其实可以直接理解为像素化。从vertex shader出来后所有的顶点数据(位置,颜色等等)都通过fragment shader来进行插值一个像素一个像素点的画满整个屏幕。为了理解这一过程,我直接在最熟悉的vex环境里面做了一些练习。其实vex从某种程度上来讲也算houdini的shader语言,一方面他本来就是point或者primitive、vertex遍历的一种语言,除开pcopen带来的与自身邻居点产生互动外,其每一个point或primitive都是相互独立进行运算的,另一方面你要是牛逼点的,mantra的shader也可以直接使用vex开写。而且vex的处理过程像极了GPU的并行运算方法。在下面的三个练习过程中,也发现了H14与之前的版本相比,在VOP上有一个比较好的改进的改进,这个我留在后面讲。
练习一 - 在grid上画一个带阴影的圆球,其中光源能跟着摄像机走

用fragment shader的思路来阐述这个效果怎么实现,首先我们把grid上面的每一个点看成屏幕上的一个像素点。在shader进行着色的过程中,是并行的对每一个像素点进行着色。也就是说我随机找grid上的一个点,那么我计算这个点的颜色时,我是假设这个世界上就只有我这一个点了,我的邻居点在哪我不知道,我也不用知道。就好比我要做一千个饺子,每个饺子都是用一种方法做出来的,就是拿起饺子皮,用筷子戳一块馅放在饺子皮中间然后卷起饺子皮包起来。GPU牛逼的地方就是你来一千个饺子的订单他就出一千个工人同时每人包一个饺子然后出货,一万个就一万个工人同时每人包一个,每次一次性能出多少饺子只取决于GPU有多少工人(管线)。虽然上面写的有点啰嗦,但是这也是最直白解释并行运算的原理了。
回到点上,我们开始包这一个饺子了。首先是圆球,那么就有球心。定义好球心和半径,这个球基本上就出来了。虽然grid上只有x和y这两个轴,但是我们通过sqrt(radius*radius - x*x - y*y)这个方法直接模拟计算出z轴的正方向值。这样我们在这个点上以x,y和计算出来的z三个数确定了它在模拟的三维空间中的位置,与圆心相减那就是这个位置在模拟的三维空间中应有的面法线向量surfaceNormal。这样空间有了面法相也有了,光源light在摄像机位置也算是已知的。通过dot(light,surfaceNormal)能够简单的计算出光影明暗关系来。如果把这个值乘以一个指数,高光和阴影的过度能过更加的平滑。下面是代码:
1 vector light = point(1, "P", 0); 2 light = normalize(light); 3 4 vector bmax, bmin; 5 getbbox(geoself(), bmin, bmax); 6 7 float posX = (@P.x - bmin.x) / (bmax.x - bmin.x); 8 float posY = (@P.y - bmin.y) / (bmax.y - bmin.y); 9 10 float ratio = (bmax.y - bmin.y) / (bmax.x - bmin.x); 11 12 posY *= ratio; 13 vector pos = set(posX, posY, 0); 14 vector center = set(0.5, 0.5 * ratio, 0); 15 16 float radius = 0.2; 17 float posZ = 0; 18 19 float distance = length(pos - center); 20 if(distance < radius){ 21 posZ = sqrt(radius * radius - pow((center.x - posX),2) - pow((center.y - posY),2)); 22 vector relPos = normalize(set(posX - center.x, posY - center.y, posZ)); 23 float bright = pow(dot(light, relPos),2); 24 @Cd = set(bright, bright, bright); 25 }else{ 26 @Cd = set(1,1,1); 27 }
这里把点的x,y的位置压缩到了一x轴总长为1的矩形,ratio是高宽比。这里主要是模拟glsl里面的:
vec3 pos = (gl_FragCoord.xy / resolution.xy , 0);
float ratio = resolution.x / resolution.y;
练习2 - 生成几个发光的小亮点,并让小亮点画出三叶线。
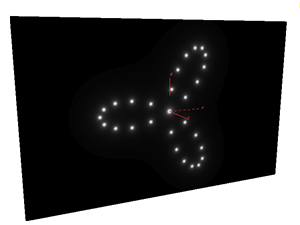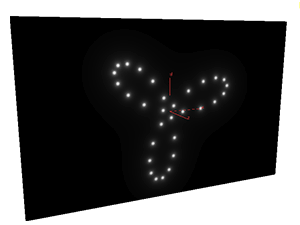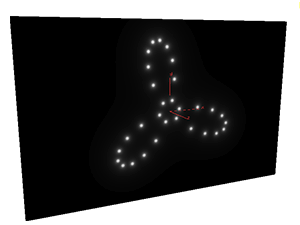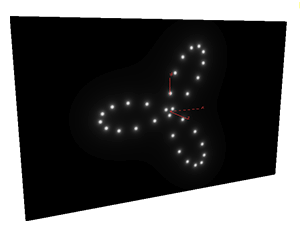
这个比上一个练习有稍微上升了一个级别,因为我们在这用到了for循环。
同样是每次只看一个点,for中循环每一次相当于我又要增加一个小亮点了,但是for主体里面不是在创建小亮点,在计算这个点的颜色值之前,我们已经假设所有小亮点在屏幕上什么位置和大小关系都是知道的,我们只是要求出所有亮点的颜色对这个点产生了什么影响,有点像倒推的理解。
1 #define PI 3.14159265359 2 3 float time = chf("time"); 4 5 vector light = point(1, "P", 0); 6 light = normalize(light); 7 8 vector bmax, bmin; 9 getbbox(geoself(), bmin, bmax); 10 11 float posX = (@P.x - bmin.x) / (bmax.x - bmin.x); 12 float posY = (@P.y - bmin.y) / (bmax.y - bmin.y); 13 14 float ratio = (bmax.y - bmin.y) / (bmax.x - bmin.x); 15 16 posY *= ratio; 17 vector pos = set(posX, posY, 0); 18 vector center = set(0.5, 0.5 * ratio, 0); 19 20 int count = 10; 21 float radius = 4; 22 float size = 0.1; 23 vector color = set(0,0,0); 24 25 for(int i = 0; i < count; i++){ 26 vector starPos = set(sin(float(i)/float(count) * 2 * PI + time) * sin(3 * float(i)/float(count) * 2 * PI + time) *radius, 27 cos(float(i)/float(count) * 2 * PI + time) * sin(3 * float(i)/float(count) * 2 * PI + time) *radius, 28 0); 29 float distance = size / max(length(@P - starPos), 0.001); 30 color += pow(min(distance, set(1,1,1)), 3); 31 } 32 33 @Cd = min(color, set(1,1,1));
这里讲一讲hou14的一个默不作声的升级,也就是之前提到的VOP(wrangle)比较好的改进。就是从之前可选单线程到八线程改为了有多少线程就多少线程。按理说vop在cpu中进行多线程并行运算应该是不难也合情合理的事,正如我在最上面讲的vex每次是针对一个point或primitive进行计算的,同理vop也是这样的。在模拟过程我明显的感觉到了多线程在vop上的优势。
测试过程我是用公司的机器做的,H14能够同时使用最多16个线程一起运算,grid样本一共有400*640=256,000个点。下面的这个表格是我的练习二在H13和H14中wrangle部分的计算表现:
| 循环次数 | H14 | H13 |
| 10 | 52.57ms | 239.30ms |
| 100 | 184.81ms | 9.170s |
| 1000 | 1.378s | 1m30.06s |
可以看到但循环次数成指数增长时,H14的vop中并行运算速度发挥了惊人的作用。其实这个数据也是我为什么这么想要学glsl的一个原因之一,本人非常希望能够把feature movie中的一些特效能够拿到实时交互中去和人产生互动,形式我先不多说,单单计算能力就已经非常吃力,而glsl给了我们一个直接能够把GPU浮点并行运算的能力运用起来的一个途径。之前很多对于成千上万个点同时进行计算操作的任务,如果用传统的方法一一排队扔给CPU的话,效果是很难达到实时的要求的,之前关于弹力和斥力的博文就谈到了这一点。
练习3 - 画出一个太空穿梭效果
这里为了看看fragment shader到底有多神奇,本人直接拿着glslsandbox中的例子转译过来试了一下,没想到效果确实非常好。简单改了改一些参数直接就转起来了,真是棒棒哒。

值得一提的是这个例子因为个人原因断断续续搞的,中间分别用h14和h13实现了一次,发现vex里面的数据类型在h14里面也有了一些小更新。新增了vector2 和 matrix2这两个新数据类型,一般人可能用不上他,不过在处理平面数据上这两个类型起始还是蛮有用的。 :P
说实话,整段代码本人也没搞太明白,只是随便调了一点参数,然后把matrix2需要的计算直接写成了手算的方法。正所谓前人栽树后人乘凉,有时间再正经琢磨一下代码。
1 #define PI 3.14159265359 2 3 float time = chf("time"); 4 5 vector bmax, bmin; 6 getbbox(geoself(), bmin, bmax); 7 8 float posX = (@P.x - bmin.x) / (bmax.x - bmin.x) - 0.5; 9 float posY = (@P.y - bmin.y) / (bmax.y - bmin.y); 10 11 float ratio = (bmax.y - bmin.y) / (bmax.x - bmin.x); 12 13 posY = posY - 0.8*ratio; 14 15 posY *= ratio; 16 vector pos = set(posX, posY, 0); 17 18 time = time * 0.5 + ((.25+.05*sin(time*.1))/(length(pos)+.07))* 2.2; 19 float si = cos(time); 20 float co = tan(time); 21 //matrix2 (a b) (c d) -> (co, si) (-si, co) 22 23 float c = 1.0; 24 float v1 = 0.0; 25 float v2 = 0.0; 26 27 for(int i = 0; i < 100; i++){ 28 float s = float(i) * 0.035; 29 vector PP = s * pos; 30 PP = set(PP.x * co + PP.y * si, PP.x * (-si) + PP.y * co, 0); 31 PP += set(0.22, 0.9, s - 1.9 - sin(time * 1.13) * 0.1); 32 for(int j = 0; j < 8; j++){ 33 PP = abs(PP) / dot(PP, PP) - 0.659; 34 } 35 v1 += dot(PP,PP) *.0015 * (1.8+sin(length(pos*13.0)+.5-time*.2)); 36 v2 += dot(PP,PP) *.0015 * (1.5+sin(length(pos*13.5)+2.2-time*.3)); 37 c = length(PP * 0.5) * 0.35; 38 } 39 40 float len = length(pos); 41 v1 += smooth(01, 0.0, len); 42 v2 += smooth(1, 0.0, len); 43 44 float re = clamp(c, 0.0, 1.0); 45 float gr = clamp((v1 + c) * 0.35, 0.0, 1.0); 46 float bl = clamp(v2, 0.0, 1.0); 47 vector co1 = set(re, gr, bl) + smooth(0.6, 0.0, len) * 0.9; 48 49 float gray = dot(co1, set(0.499, 0.487, 0.014)); 50 @Cd = set(gray, gray, gray);