1、关于高并发的几个重要概念
1.1 同步和异步
首先这里说的同步和异步是指函数/方法调用方面。

很明显,同步调用会等待方法的返回,异步调用会瞬间返回,但是异步调用瞬间返回并不代表你的任务就完成了,他会在后台起个线程继续进行任务。
1.2 并发和并行

并发和并行在外在表象来说,是差不多的。由图所示,并行则是两个任务同时进行,而并发呢,则是一会做一个任务一会又切换做另一个任务。所以单个cpu是不能做并行的,只能是并发。
1.3 临界区(重要:自己以前都不知道是这么叫)
临界区用来表示一种公共资源或者说是共享数据,可以被多个线程使用,但是每一次,只能有一个线程使用它,一旦临界区资源被占用,其他线程要想使用这个资源,就必须等待。

1.4 阻塞和非阻塞
- 阻塞和非阻塞通常形容多线程间的相互影响。比如一个线程占用了临界区资源,那么其它所有需要这个资源的线程就必须在这个临界区中进行等待,等待会导致线程挂起。这种情况就是阻塞。此时,如果占用资源的线程一直不愿意释放资源,那么其它所有阻塞在这个临界区上的线程都不能工作。
- 非阻塞允许多个线程同时进入临界区
所以阻塞的方式,一般性能不会太好。根据一般的统计,如果一个线程在操作系统层面被挂起,做了上下文切换了,通常情况需要8W个时间周期来做这个事情。
1.5 死锁、饥饿、活锁
所谓死锁:是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。就如同下图中的车都想前进,却谁都无法前进。
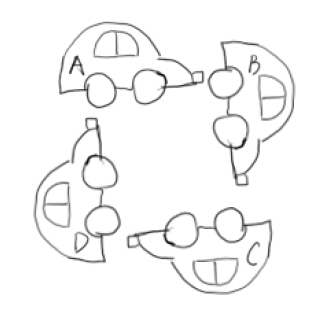
但是死锁虽说是不好的现象,但是它是一个静态的问题,一旦发生死锁,进程被卡死,cpu占有率也是0,它不会占用cpu,它会被调出去。相对来说还是比较好发现和分析的。
与死锁相对应的是活锁。
活锁,指事物1可以使用资源,但它让其他事物先使用资源;事物2可以使用资源,但它也让其他事物先使用资源,于是两者一直谦让,都无法使用资源。
举个例子,就如同你在街上遇到个人,刚好他朝着你的反方向走,与你正面碰到,你们都想让彼此过去。你往左边移,他也往左边移,两人还是无法过去。这时你往右边移,他也往右边移,如此循环下去。
一个线程在取得了一个资源时,发现其他线程也想到这个资源,因为没有得到所有的资源,为了避免死锁把自己持有的资源都放弃掉。如果另外一个线程也做了同样的事情,他们需要相同的资源,比如A持有a资源,B持有b资源,放弃了资源以后,A又获得了b资源,B又获得了a资源,如此反复,则发生了活锁。
活锁会比死锁更难发现,因为活锁是一个动态的过程。
饥饿是指某一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行。
1.6 并发级别
并发级别:阻塞和非阻塞(非阻塞分为无障碍、无锁、无等待)
1.6.1 阻塞
当一个线程进入临界区后,其他线程必须等待
1.6.2 无障碍
- 无障碍是一种最弱的非阻塞调度
- 自由出入临界区
- 无竞争时,有限步内完成操作
- 有竞争时,回滚数据
和非阻塞调度相比呢,阻塞调度是一种悲观的策略,它会认为说一起修改数据是很有可能把数据改坏的。而非阻塞调度呢,是一种乐观的策略,它认为大家修改数据未必把数据改坏。但是它是一种宽进严出的策略,当它发现一个进程在临界区内发生了数据竞争,产生了冲突,那么无障碍的调度方式则会回滚这条数据。
在这个无障碍的调度方式当中,所有的线程都相当于在拿去一个系统当前的一个快照。他们一直会尝试拿去的快照是有效的为止。
1.6.3 无锁
- 是无障碍的
- 保证有一个线程可以胜出
与无障碍相比,无障碍并不保证有竞争时一定能完成操作,因为如果它发现每次操作都会产生冲突,那它则会不停地尝试。如果临界区内的线程互相干扰,则会导致所有的线程会卡死在临界区,那么系统性能则会有很大的影响。
而无锁增加了一个新的条件,保证每次竞争有一个线程可以胜出,则解决了无障碍的问题。至少保证了所有线程都顺利执行下去。
下面代码是Java中典型的无锁计算代码
无锁在Java中很常见
while (!atomicVar.compareAndSet(localVar, localVar+1)) { localVar = atomicVar.get(); }
1.6.4 无等待
- 无锁的
- 要求所有的线程都必须在有限步内完成
- 无饥饿的
首先无等待的前提是无锁的基础上的,无锁它只保证了临界区肯定有进也有出,但是如果进的优先级都很高,那么临界区内的某些优先级低的线程可能发生饥饿,一直出不了临界区。那么无等待解决了这个问题,它保证所有的线程都必须在有限步内完成,自然是无饥饿的。
无等待是并行的最高级别,它能使这个系统达到最优状态。
无等待的典型案例:
如果只有读线程,没有线线程,那么这个则必然是无等待的。
如果既有读线程又有写线程,而每个写线程之前,都把数据拷贝一份副本,然后修改这个副本,而不是修改原始数据,因为修改副本,则没有冲突,那么这个修改的过程也是无等待的。最后需要做同步的只是将写完的数据覆盖原始数据。
由于无等待要求比较高,实现起来比较困难,所以无锁使用得会更加广泛一些。
2. 有关并行的两个重要定律
这两个定律都与加速比有关
2.1 Amdahl定律
定义了串行系统并行化后的加速比的计算公式和理论上限
加速比定义:加速比=优化前系统耗时/优化后系统耗时
举个例子:
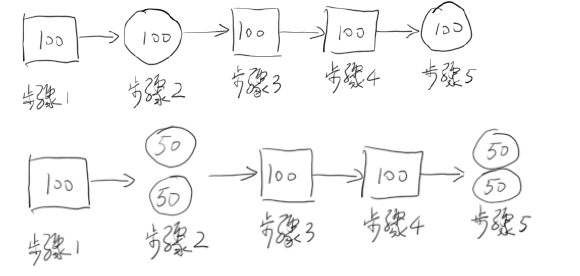
加速比=优化前系统耗时/优化后系统耗时=500/400=1.25

这个定理表明:增加CPU处理器的数量并不一定能起到有效的作用 提高系统内可并行化的模块比重,合理增加并行处理器数量,才能以最小的投入,得到最大的加速比。
2.2 Gustafson定律
说明处理器个数,串行比例和加速比之间的关系

则加速比=n-F(n-1) //推导过程略
只要有足够的并行化,那么加速比和CPU个数成正比
系列: