EAST是旷视科技在2017年论文East: An Efficient and Accurate Scene Text Detector中提出,能检测任意角度的文字,速度和准确度都很有优势。
East算是一篇很有特色的文章,还是从网络设计,GroundTruth生成,loss函数和Locality-Aware NMS(后处理)四部分来学习下。
1.网络设计
East论文中网络结构如下图所示,采用PVANet提取特征,将不同层的特征进行上采样合并,随后预测最后的score和box。关于box的表示方式,论文中提出了两种方法,即RBOX和QUAD,若box数据采用RBOX形式标注,模型最后预测1个chanel的score_map和4个channel的box_map; 若box数据采用QUAD的形式标注,模型最后预测1个chanel的score_map和8个channel的box_map.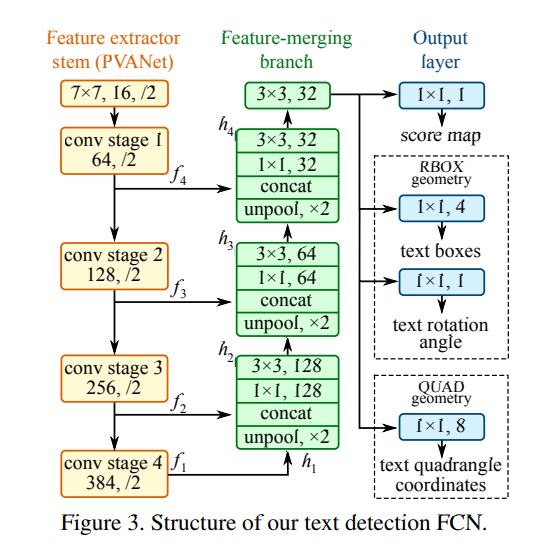
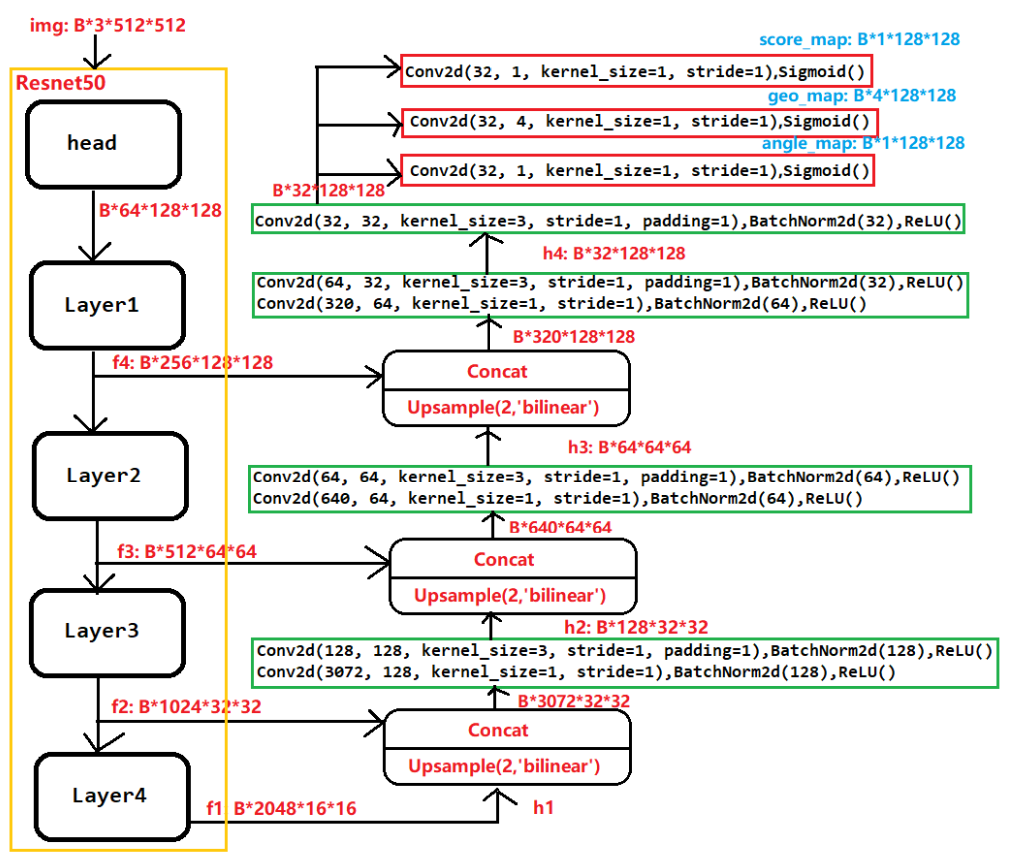
实际工作中,我主要用到Resnet作为backbone的East网络,并使用RBOX形式的标注框,下面是具体的网络结构如下图所示,训练过程中网络的数据流总结如下:
-
-
f1上采样后和f2进行concat,随后经过1x1,3x3的卷积得到h2(1x128x32x32), 同样的h2上采样,和f3进行concat,卷积得到h3(1x64x64x64), 最后h3上采样,和f4进行concat,卷积得到h4(1x32x128x128)
-
geo_map = self.sigmoid2(geo_map) * 512 (输入图片尺寸为512,变化到像素值) angle_map = (angle_map - 0.5) * math.pi / 2 (变化到[-Π/2, Π/2]之间)
2. GroundTruth生成
2.1 GroundTruth含义理解
上述提到了box的标注有两种形式RBOX和QUAD,其GroundTruth也不一样
RBOX
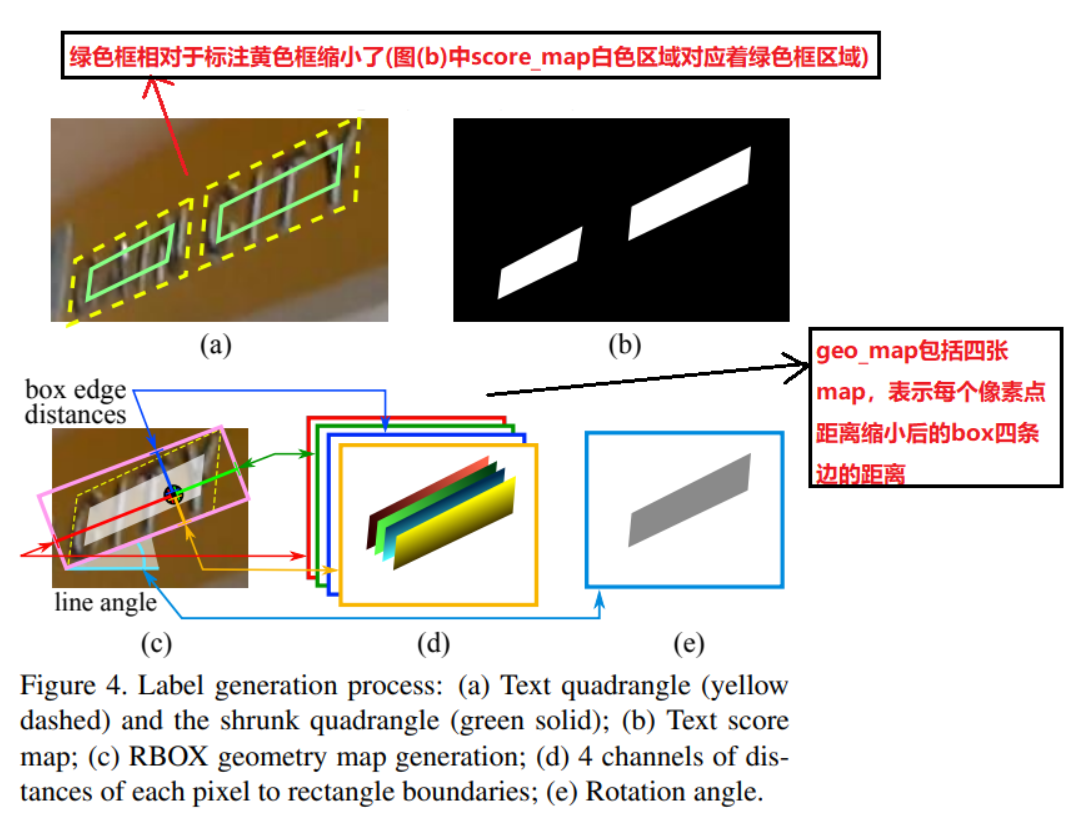
RBOX的GroundTruth包括score_map,geo_map和angle_map。score map文字框区域的像素值为1,其他非文本框区域值为0,如下图中(b)所示。geo_map的文本区域中每个像素点都包含4个值,即像素点到文本框上,下,左,右的距离,如下面示意图中,图(d)中深蓝/黄/红/绿分别表示这个像素点到上,下,左,右的距离。图(e)是angle_map ,表示文本框的旋转角度angle。特别注意,这里考虑文本区域中每个像素点到文本框的距离,其他非文本框区域的像素点的这5个值置为0,最后得到的是WxHx4大小的geo_map和WxHx1的angle_map),W和H分别表示原始图片的宽和高。(注意的是,这里的文本框都是实际文本框的缩小版)
QUAD
QUAD的GroundTruth包括score_map和geo_map,其score_map和RBOX一样,box标记出文本所在框的四个角点坐标 ,这个无需做额外处理,geo_ma的文本区域中每个像素点包含8个值,为四个角点坐标的集合。
2.2 GroundTruth相关代码理解
在产生geo_map和angle_map时,有很多代码不是很好理解,值得说明下。
polygon_area()函数
主要是用来验证box四个坐标是否按顺时针排序,若按逆时针排序,需要转换为顺时针排序,其原理是利用了鞋带定理。鞋带定理(Shoelace Theorem)能根据多边形的顶点坐标,计算任意多边形的面积,坐标顺时针排列时为负数,逆时针排列时为正数。(鞋带定理:https://zhuanlan.zhihu.com/p/110025234)


def polygon_area(poly): ''' compute area of a polygon :param poly: :return: ''' edge = [ (poly[1][0] - poly[0][0]) * (poly[1][1] + poly[0][1]), (poly[2][0] - poly[1][0]) * (poly[2][1] + poly[1][1]), (poly[3][0] - poly[2][0]) * (poly[3][1] + poly[2][1]), (poly[0][0] - poly[3][0]) * (poly[0][1] + poly[3][1]) ] return np.sum(edge)/2. def check_and_validate_polys(polys, tags, size): ''' check so that the text poly is in the same direction, and also filter some invalid polygons :param polys: :param tags: :return: ''' (h, w) = size if polys.shape[0] == 0: return polys polys[:, :, 0] = np.clip(polys[:, :, 0], 0, w-1) polys[:, :, 1] = np.clip(polys[:, :, 1], 0, h-1) validated_polys = [] validated_tags = [] for poly, tag in zip(polys, tags): p_area = polygon_area(poly) if abs(p_area) < 1: # print poly print('invalid poly') continue if p_area > 0: print('poly in wrong direction') poly = poly[(0, 3, 2, 1), :] validated_polys.append(poly) validated_tags.append(tag) return np.array(validated_polys), np.array(validated_tags)
判断多边形排序应用:
#鞋带定理(Shoelace Theorem)能根据多边形的顶点坐标,计算任意多边形的面积,坐标顺时针排列时为负数,逆时针排列时为正数 def validate_clockwise_points(points): #顺时针排序时报错 """ Validates that the points that the 4 points that dlimite a polygon are in counter_clockwise order. """ if len(points) != 8: raise Exception("Points list not valid." + str(len(points))) point = [ [int(points[0]), int(points[1])], [int(points[2]), int(points[3])], [int(points[4]), int(points[5])], [int(points[6]), int(points[7])] ] edge = [ (point[1][0] - point[0][0]) * (point[1][1] + point[0][1]), (point[2][0] - point[1][0]) * (point[2][1] + point[1][1]), (point[3][0] - point[2][0]) * (point[3][1] + point[2][1]), (point[0][0] - point[3][0]) * (point[0][1] + point[3][1]) ] summatory = edge[0] + edge[1] + edge[2] + edge[3] if summatory < 0: raise Exception("Points are not counter_clockwise.")
point_dist_to_line()函数
np.cross表示向量的叉积,而向量的叉积表示这两个向量形成的平行四边形的面积,面积除以底边得到高,即p3到p1p2边的距离
def point_dist_to_line(p1, p2, p3): # compute the distance from p3 to p1-p2 return np.linalg.norm(np.cross(p2 - p1, p1 - p3)) / np.linalg.norm(p2 - p1)
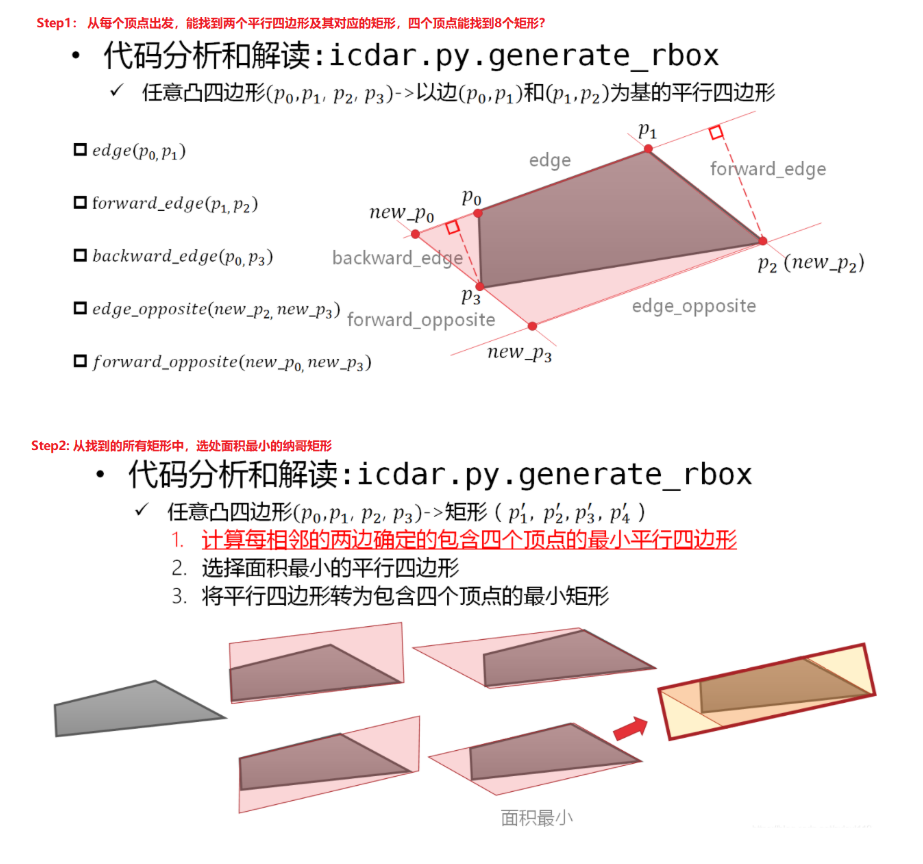
generate_rbox()函数
这个函数最复杂,其中计算包围box最小矩形的代码比较难理解,大致流程就是从每个顶点出发,找到对应的平行四边形及其矩形,然后比较所有矩形的面积,取面积最小的矩形,如下图所示:
generate_rbox的代码如下:
def generate_rbox(im_size, polys, tags): h, w = im_size poly_mask = np.zeros((h, w), dtype=np.uint8) score_map = np.zeros((h, w), dtype=np.uint8) geo_map = np.zeros((h, w, 5), dtype=np.float32) # mask used during traning, to ignore some hard areas training_mask = np.ones((h, w), dtype=np.uint8) for poly_idx, poly_tag in enumerate(zip(polys, tags)): poly = poly_tag[0] tag = poly_tag[1] r = [None, None, None, None] for i in range(4): r[i] = min(np.linalg.norm(poly[i] - poly[(i + 1) % 4]), np.linalg.norm(poly[i] - poly[(i - 1) % 4])) # score map shrinked_poly = shrink_poly(poly.copy(), r).astype(np.int32)[np.newaxis, :, :] cv2.fillPoly(score_map, shrinked_poly, 1) cv2.fillPoly(poly_mask, shrinked_poly, poly_idx + 1) # if the poly is too small, then ignore it during training poly_h = min(np.linalg.norm(poly[0] - poly[3]), np.linalg.norm(poly[1] - poly[2])) poly_w = min(np.linalg.norm(poly[0] - poly[1]), np.linalg.norm(poly[2] - poly[3])) if min(poly_h, poly_w) < FLAGS.min_text_size: cv2.fillPoly(training_mask, poly.astype(np.int32)[np.newaxis, :, :], 0) if tag: cv2.fillPoly(training_mask, poly.astype(np.int32)[np.newaxis, :, :], 0) xy_in_poly = np.argwhere(poly_mask == (poly_idx + 1)) # if geometry == 'RBOX': # 对任意两个顶点的组合生成一个平行四边形 - generate a parallelogram for any combination of two vertices fitted_parallelograms = [] for i in range(4): p0 = poly[i] p1 = poly[(i + 1) % 4] p2 = poly[(i + 2) % 4] p3 = poly[(i + 3) % 4] edge = fit_line([p0[0], p1[0]], [p0[1], p1[1]]) #直线p0p1 backward_edge = fit_line([p0[0], p3[0]], [p0[1], p3[1]]) #直线p0p3 forward_edge = fit_line([p1[0], p2[0]], [p1[1], p2[1]]) #直线p1p2 if point_dist_to_line(p0, p1, p2) > point_dist_to_line(p0, p1, p3): #p2到直线p0p1的距离大于p3到p0p1的距离 # 平行线经过p2 - parallel lines through p2 if edge[1] == 0: #经过p2平行于p0p1的直线 edge_opposite = [1, 0, -p2[0]] else: edge_opposite = [edge[0], -1, p2[1] - edge[0] * p2[0]] else: # 经过p3 - after p3 if edge[1] == 0: #经过p3平行于p0p1的直线 edge_opposite = [1, 0, -p3[0]] else: edge_opposite = [edge[0], -1, p3[1] - edge[0] * p3[0]] # move forward edge new_p0 = p0 new_p1 = p1 new_p2 = p2 new_p3 = p3 new_p2 = line_cross_point(forward_edge, edge_opposite) #直线forward_edge和直线edge_opposite的交点 if point_dist_to_line(p1, new_p2, p0) > point_dist_to_line(p1, new_p2, p3): # across p0 if forward_edge[1] == 0: #经过p0,平行于forward_edge的直线 forward_opposite = [1, 0, -p0[0]] else: forward_opposite = [forward_edge[0], -1, p0[1] - forward_edge[0] * p0[0]] else: # across p3 if forward_edge[1] == 0: #经过p3,平行于forward_edge的直线 forward_opposite = [1, 0, -p3[0]] else: forward_opposite = [forward_edge[0], -1, p3[1] - forward_edge[0] * p3[0]] new_p0 = line_cross_point(forward_opposite, edge) #直线forward_opposite和直线edge的交点 new_p3 = line_cross_point(forward_opposite, edge_opposite) #直线forward_opposite和直线edge_opposite的交点 fitted_parallelograms.append([new_p0, new_p1, new_p2, new_p3, new_p0]) # or move backward edge new_p0 = p0 new_p1 = p1 new_p2 = p2 new_p3 = p3 new_p3 = line_cross_point(backward_edge, edge_opposite) if point_dist_to_line(p0, p3, p1) > point_dist_to_line(p0, p3, p2): # across p1 if backward_edge[1] == 0: backward_opposite = [1, 0, -p1[0]] else: backward_opposite = [backward_edge[0], -1, p1[1] - backward_edge[0] * p1[0]] else: # across p2 if backward_edge[1] == 0: backward_opposite = [1, 0, -p2[0]] else: backward_opposite = [backward_edge[0], -1, p2[1] - backward_edge[0] * p2[0]] new_p1 = line_cross_point(backward_opposite, edge) new_p2 = line_cross_point(backward_opposite, edge_opposite) fitted_parallelograms.append([new_p0, new_p1, new_p2, new_p3, new_p0]) areas = [Polygon(t).area for t in fitted_parallelograms] parallelogram = np.array(fitted_parallelograms[np.argmin(areas)][:-1], dtype=np.float32) # sort thie polygon parallelogram_coord_sum = np.sum(parallelogram, axis=1) min_coord_idx = np.argmin(parallelogram_coord_sum) parallelogram = parallelogram[ [min_coord_idx, (min_coord_idx + 1) % 4, (min_coord_idx + 2) % 4, (min_coord_idx + 3) % 4]] rectange = rectangle_from_parallelogram(parallelogram) rectange, rotate_angle = sort_rectangle(rectange) p0_rect, p1_rect, p2_rect, p3_rect = rectange for y, x in xy_in_poly: point = np.array([x, y], dtype=np.float32) # top geo_map[y, x, 0] = point_dist_to_line(p0_rect, p1_rect, point) # right geo_map[y, x, 1] = point_dist_to_line(p1_rect, p2_rect, point) # down geo_map[y, x, 2] = point_dist_to_line(p2_rect, p3_rect, point) # left geo_map[y, x, 3] = point_dist_to_line(p3_rect, p0_rect, point) # angle geo_map[y, x, 4] = rotate_angle return score_map, geo_map, training_mask
3. loss函数
损失函数包括两部分,score_map的的分类任务损失和geo_map,angle_map的回归损失,论文中总损失计算如下:

分类损失
score_map中文本所在区域的像素点值为1,背景区域的像素点值为0,是一个二分类问题,由于类别平衡,论文中使用类平衡的交叉熵损失(class-balanced cross-entropy)

很多实现代码中都使用dice loss代替了类平衡损失,dice loss的实现代码如下:
def dice_coefficient(y_true_cls, y_pred_cls, training_mask): ''' dice loss :param y_true_cls: :param y_pred_cls: :param training_mask: :return: ''' eps = 1e-5 intersection =torch.sum(y_true_cls * y_pred_cls * training_mask) union = torch.sum(y_true_cls * training_mask) + torch.sum(y_pred_cls * training_mask) + eps loss = 1. - (2 * intersection / union)
回归损失
RBOX损失的计算,包括box位置geo_map损失和box角度angle_map的损失,box位置采用了比较有特色的IOU Loss, 即gt框和预测框的交并比,如下面等式
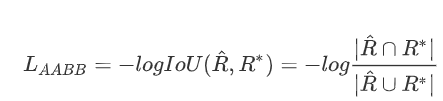
box的角度损失采用了余弦角度差损失,如下面等式
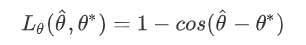
总的RBOX损失值如下
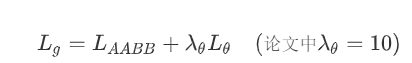
总的loss函数的实现代码如下:
import torch import torch.nn as nn def dice_coefficient(y_true_cls, y_pred_cls, training_mask): ''' dice loss :param y_true_cls: :param y_pred_cls: :param training_mask: :return: ''' eps = 1e-5 intersection =torch.sum(y_true_cls * y_pred_cls * training_mask) union = torch.sum(y_true_cls * training_mask) + torch.sum(y_pred_cls * training_mask) + eps loss = 1. - (2 * intersection / union) return loss class LossFunc(nn.Module): def __init__(self): super(LossFunc, self).__init__() return def forward(self, y_true_cls, y_pred_cls, y_true_geo, y_pred_geo, training_mask): classification_loss = dice_coefficient(y_true_cls, y_pred_cls, training_mask) # scale classification loss to match the iou loss part classification_loss *= 0.01 # d1 -> top, d2->right, d3->bottom, d4->left # d1_gt, d2_gt, d3_gt, d4_gt, theta_gt = tf.split(value=y_true_geo, num_or_size_splits=5, axis=3) d1_gt, d2_gt, d3_gt, d4_gt, theta_gt = torch.split(y_true_geo, 1, 1) # d1_pred, d2_pred, d3_pred, d4_pred, theta_pred = tf.split(value=y_pred_geo, num_or_size_splits=5, axis=3) d1_pred, d2_pred, d3_pred, d4_pred, theta_pred = torch.split(y_pred_geo, 1, 1) area_gt = (d1_gt + d3_gt) * (d2_gt + d4_gt) area_pred = (d1_pred + d3_pred) * (d2_pred + d4_pred) w_union = torch.min(d2_gt, d2_pred) + torch.min(d4_gt, d4_pred) h_union = torch.min(d1_gt, d1_pred) + torch.min(d3_gt, d3_pred) area_intersect = w_union * h_union area_union = area_gt + area_pred - area_intersect L_AABB = -torch.log((area_intersect + 1.0)/(area_union + 1.0)) L_theta = 1 - torch.cos(theta_pred - theta_gt) L_g = L_AABB + 20 * L_theta return torch.mean(L_g * y_true_cls * training_mask) + classification_loss
4. Locality-Aware NMS(后处理)
在测试阶段,需要根据score_map和geo_map得到最后的检测框box,流程如下:
-
选取score_map中预测分数大于score_map_thresh的区域,作为可能的文本检测区域
-
根据筛选后的score_map和geo_map, 将RBOXA,A,B,B,angle)的文本框表示形式转成QUAD的形式
-
所有坐标点按照y坐标,对于y坐标相邻两个box进行weighted_merge(以分数为权重进行合并)
-
根据score排序,并做NMS,过滤多余文本框。
将RBOX形式转换为QUAD的逻辑,代码中采用函数restore_rectangle_rbox()实现,其逻辑是:对于文本区域中的每一个像素点,先旋转矩阵计算得到旋转后的坐标,再平移到该像素点即可,如下图所示:
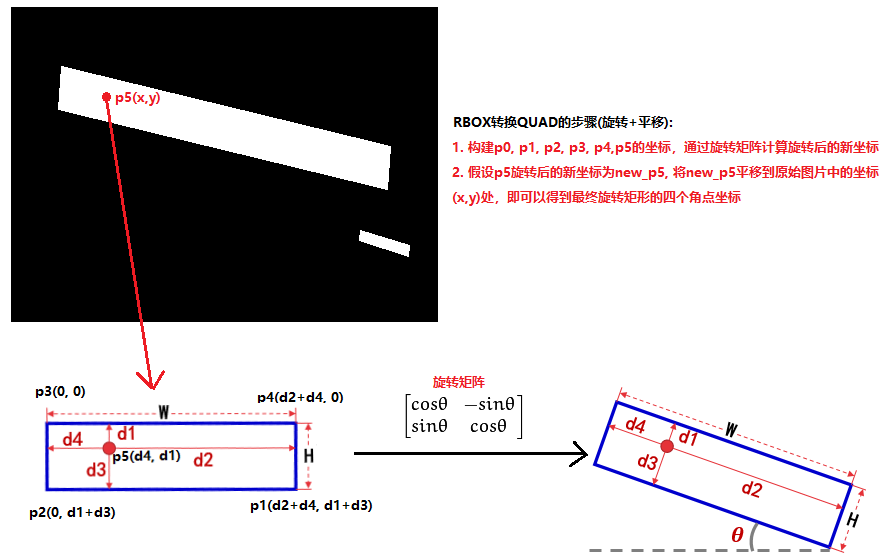
restore_rectangle_rbox()代码如下:
def restore_rectangle_rbox(origin, geometry): # origin:是所有文本区域点的坐标,(x, y)形式 # geometry:是origin中每个点对应四边的距离和角度[A, A, B, B, angle] d = geometry[:, :4] # 四边距离[A, A, B, B] angle = geometry[:, 4] # 角度angle # for angle > 0 origin_0 = origin[angle >= 0] d_0 = d[angle >= 0] angle_0 = angle[angle >= 0] if origin_0.shape[0] > 0: p = np.array([np.zeros(d_0.shape[0]), -d_0[:, 0] - d_0[:, 2], d_0[:, 1] + d_0[:, 3], -d_0[:, 0] - d_0[:, 2], d_0[:, 1] + d_0[:, 3], np.zeros(d_0.shape[0]), np.zeros(d_0.shape[0]), np.zeros(d_0.shape[0]), d_0[:, 3], -d_0[:, 2]]) p = p.transpose((1, 0)).reshape((-1, 5, 2)) # N*5*2 rotate_matrix_x = np.array([np.cos(angle_0), np.sin(angle_0)]).transpose((1, 0)) rotate_matrix_x = np.repeat(rotate_matrix_x, 5, axis=1).reshape(-1, 2, 5).transpose((0, 2, 1)) # N*5*2 rotate_matrix_y = np.array([-np.sin(angle_0), np.cos(angle_0)]).transpose((1, 0)) rotate_matrix_y = np.repeat(rotate_matrix_y, 5, axis=1).reshape(-1, 2, 5).transpose((0, 2, 1)) p_rotate_x = np.sum(rotate_matrix_x * p, axis=2)[:, :, np.newaxis] # N*5*1 p_rotate_y = np.sum(rotate_matrix_y * p, axis=2)[:, :, np.newaxis] # N*5*1 p_rotate = np.concatenate([p_rotate_x, p_rotate_y], axis=2) # N*5*2 p3_in_origin = origin_0 - p_rotate[:, 4, :] new_p0 = p_rotate[:, 0, :] + p3_in_origin # N*2 new_p1 = p_rotate[:, 1, :] + p3_in_origin new_p2 = p_rotate[:, 2, :] + p3_in_origin new_p3 = p_rotate[:, 3, :] + p3_in_origin new_p_0 = np.concatenate([new_p0[:, np.newaxis, :], new_p1[:, np.newaxis, :], new_p2[:, np.newaxis, :], new_p3[:, np.newaxis, :]], axis=1) # N*4*2 else: new_p_0 = np.zeros((0, 4, 2)) # for angle < 0 origin_1 = origin[angle < 0] d_1 = d[angle < 0] angle_1 = angle[angle < 0] if origin_1.shape[0] > 0: p = np.array([-d_1[:, 1] - d_1[:, 3], -d_1[:, 0] - d_1[:, 2], np.zeros(d_1.shape[0]), -d_1[:, 0] - d_1[:, 2], np.zeros(d_1.shape[0]), np.zeros(d_1.shape[0]), -d_1[:, 1] - d_1[:, 3], np.zeros(d_1.shape[0]), -d_1[:, 1], -d_1[:, 2]]) p = p.transpose((1, 0)).reshape((-1, 5, 2)) # N*5*2 rotate_matrix_x = np.array([np.cos(-angle_1), -np.sin(-angle_1)]).transpose((1, 0)) rotate_matrix_x = np.repeat(rotate_matrix_x, 5, axis=1).reshape(-1, 2, 5).transpose((0, 2, 1)) # N*5*2 rotate_matrix_y = np.array([np.sin(-angle_1), np.cos(-angle_1)]).transpose((1, 0)) rotate_matrix_y = np.repeat(rotate_matrix_y, 5, axis=1).reshape(-1, 2, 5).transpose((0, 2, 1)) p_rotate_x = np.sum(rotate_matrix_x * p, axis=2)[:, :, np.newaxis] # N*5*1 p_rotate_y = np.sum(rotate_matrix_y * p, axis=2)[:, :, np.newaxis] # N*5*1 p_rotate = np.concatenate([p_rotate_x, p_rotate_y], axis=2) # N*5*2 p3_in_origin = origin_1 - p_rotate[:, 4, :] new_p0 = p_rotate[:, 0, :] + p3_in_origin # N*2 new_p1 = p_rotate[:, 1, :] + p3_in_origin new_p2 = p_rotate[:, 2, :] + p3_in_origin new_p3 = p_rotate[:, 3, :] + p3_in_origin new_p_1 = np.concatenate([new_p0[:, np.newaxis, :], new_p1[:, np.newaxis, :], new_p2[:, np.newaxis, :], new_p3[:, np.newaxis, :]], axis=1) # N*4*2 else: new_p_1 = np.zeros((0, 4, 2)) return np.concatenate([new_p_0, new_p_1])
locality-aware NMS就是在NMS之前,对于y坐标相邻很近的box先进行一次合并,然后再进行NMS,其中合并采用了weigthed_merge方法,需要注意下,python示例代码如下:
import numpy as np from shapely.geometry import Polygon def intersection(g, p): g = Polygon(g[:8].reshape((4, 2))) p = Polygon(p[:8].reshape((4, 2))) if not g.is_valid or not p.is_valid: return 0 inter = Polygon(g).intersection(Polygon(p)).area union = g.area + p.area - inter if union == 0: return 0 else: return inter/union def weighted_merge(g, p): g[:8] = (g[8] * g[:8] + p[8] * p[:8])/(g[8] + p[8]) g[8] = (g[8] + p[8]) return g def standard_nms(S, thres): order = np.argsort(S[:, 8])[::-1] keep = [] while order.size > 0: i = order[0] keep.append(i) ovr = np.array([intersection(S[i], S[t]) for t in order[1:]]) inds = np.where(ovr <= thres)[0] order = order[inds+1] return S[keep] def nms_locality(polys, thres=0.3): ''' locality aware nms of EAST :param polys: a N*9 numpy array. first 8 coordinates, then prob :return: boxes after nms ''' S = [] p = None for g in polys: if p is not None and intersection(g, p) > thres: p = weighted_merge(g, p) else: if p is not None: S.append(p) p = g if p is not None: S.append(p) if len(S) == 0: return np.array([]) return standard_nms(np.array(S), thres) if __name__ == '__main__': # 343,350,448,135,474,143,369,359 print(Polygon(np.array([[343, 350], [448, 135], [474, 143], [369, 359]])).area)
参考文章:
https://www.cnblogs.com/lillylin/p/9954981.html
https://zhuanlan.zhihu.com/p/71182747
https://blog.csdn.net/sxlsxl119/article/details/103934957