目的:把腾讯社招的每个分页的职位名称及链接、类型、人数、工作地点、发布日期爬取下来,然后存储到json文件里面
思路:
- 新建爬虫项目
- 在items.py文件里面设置存储的字段名称及类型
- 在spiders文件夹里面设置爬虫文件
- 设置管道文件
- 设置settings.py文件
- 测试运行
实际操作流程如下:
-
新建爬虫项目tencent
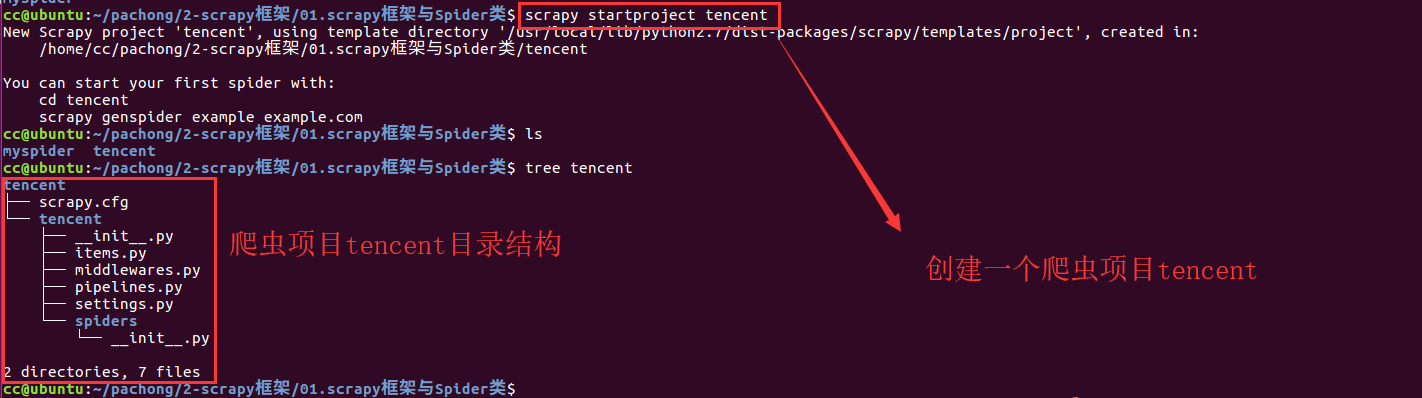
-
在items.py文件里面设置存储的字段名称及类型

-
在spiders文件夹里面设置爬虫文件 tencent_job.py

-
设置管道文件pipelines.py

-
设置settings.py文件

-
测试运行

-
爬取的数据结果tencent.json内容,共373页,3733条数据。
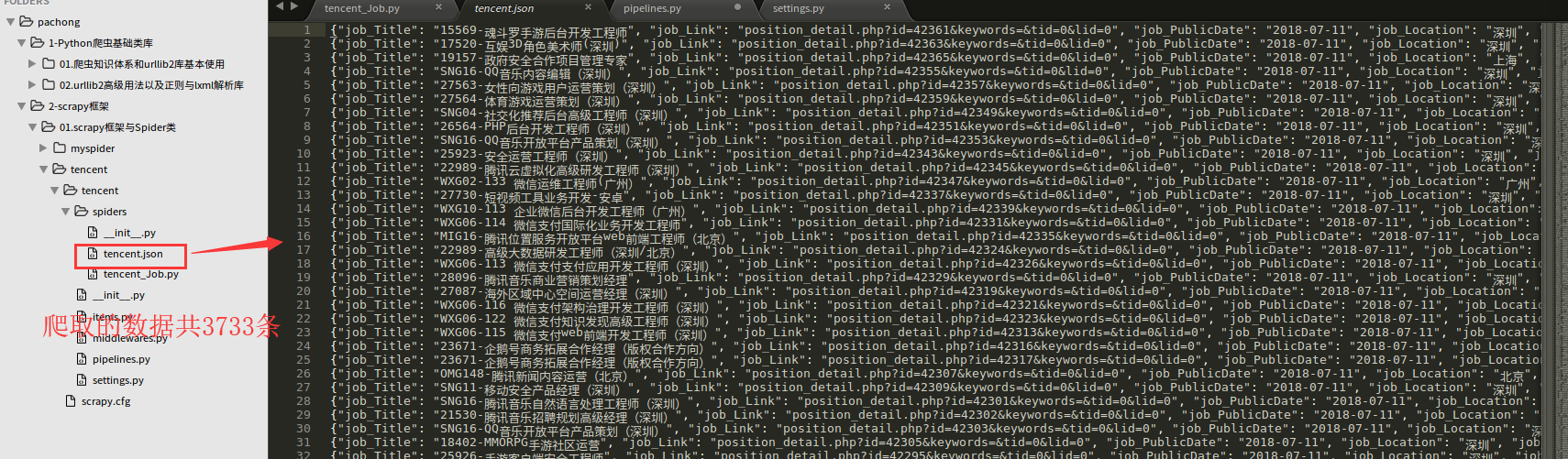
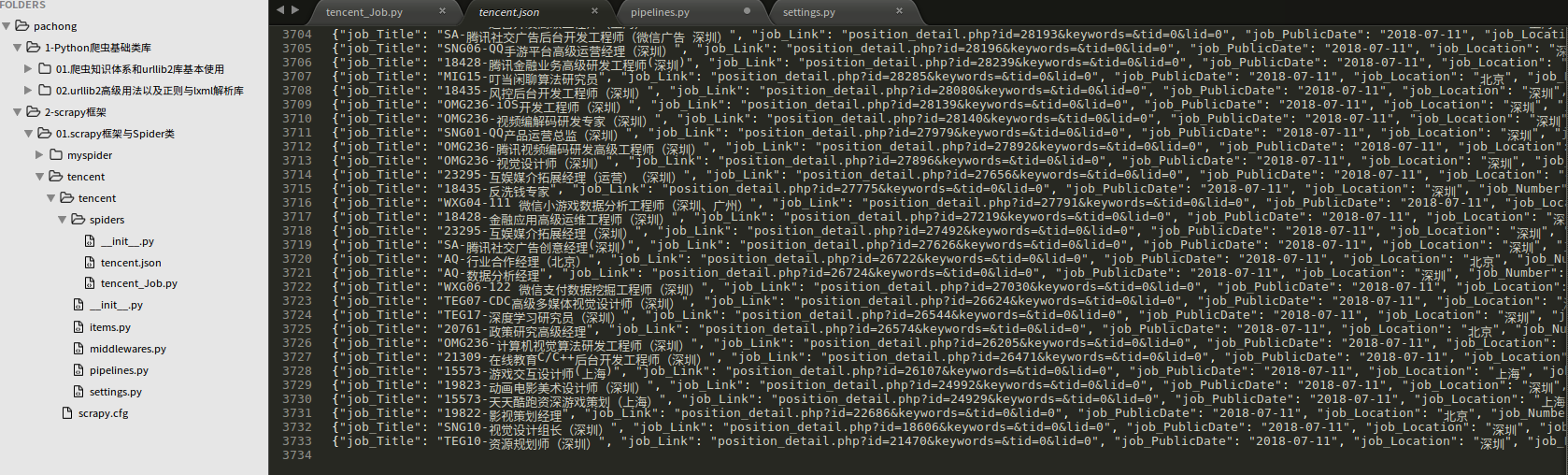
备注:博客园的图片,不支持像csdn那样可以放大缩小,所以爬虫文件和管道文件的代码如下。
items.py文件如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
# 要存储的字段名称及类型
class TencentItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
# 职位名称
job_Title = scrapy.Field()
# 详细链接
job_Link = scrapy.Field()
# 职位类型
job_Type = scrapy.Field()
# 职位人数
job_Number = scrapy.Field()
# 工作位置
job_Location = scrapy.Field()
# 发布日期
job_PublicDate = scrapy.Field()
爬虫文件tencent_job.py代码:
# -*- coding: utf-8 -*-
import scrapy
from tencent.items import TencentItem
class TencentJobSpider(scrapy.Spider):
# 爬虫名字
name = 'tencent'
# 爬取的域范围
allowed_domains = ['tencent.com']
url = 'https://hr.tencent.com/position.php?&start='
offset = 0
# 爬取的url列表
start_urls = [url + str( offset)]
# start_urls = ['https://hr.tencent.com/position.php?&start=0']
# 解析生成器,由于含有yield关键字,所以不是普通函数,而是生成器。根据返回的类型,如果是返回的数据,则把爬取的请求队列里面所有请求都执行完,才交给管道文件存储;如果是请求,则发送请求,放入请求队列,再下载调用parse
def parse(self, response):
# 使用xpath获取类名为odd和even的tr标签
job_list = response.xpath('//tr[@class="odd"] | //tr[@class="even"]')
# print(job_list)
for each in job_list:
# 实例化一个模型对象
item = TencentItem()
# 把匹配到的内容分别存储到模型对象的字段
# 注意:xpath匹配后的结果为列表,在进行xpath语法匹配时,下标是从1开始计数,python列表下标从0开始,extract是把xpath匹配的对象转换为unicode字符串
item['job_Title'] = each.xpath('./td[1]/a/text()')[0].extract()
item['job_Link'] = each.xpath('./td[1]/a/@href')[0].extract()
item['job_Type'] = each.xpath('./td[2]/text()').extract()
item['job_Number'] = each.xpath('./td[3]/text()')[0].extract()
item['job_Location'] = each.xpath('./td[4]/text()')[0].extract()
item['job_PublicDate'] = each.xpath('./td[5]/text()')[0].extract()
# print(item)
# 把数据返回给piplines.py管道文件
yield item
if self.offset <= 3730:
self.offset += 10
# 发送请求,把请求返回给调度器,如果请求有响应,则调用回调函数parse来解析处理
yield scrapy.Request(self.url + str(self.offset), callback = self.parse)
管道文件pipelines.py文件如下:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class TencentPipeline(object):
# 该方法名字固定不可修改,参数名字可修改。该方法必须有
def process_item(self, item, spider):
self.filename = open('tencent.json','a')
jsontext = json.dumps(dict(item),ensure_ascii = False).encode('utf-8') + '
'
self.filename.write(jsontext)
self.filename.close()
return item