字符串的知识点总结:#!/usr/bin/env python
字符串:
一个个字符组成的有序的 序列,是字符的集合
使用单引号,双引号,三引号引住的字符序列
字符串是不可变对象
pytnon3 起,字符串就是Unicode类型
字符串支持使用索引访问
有序的字符集合,字符序列
可迭代
python字符串格式化符号:
<tbody
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| <sp> | 在正数前面显示空格 |
| # | 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
| 0 | 显示的数字前面填充'0'而不是默认的空格 |
| % | '%%'输出一个单一的'%' |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |

# -*- coding:utf-8 -*-
# __author__:anxu.qi
# Date:2018/11/19
##################### 首字母大写(capitalize) ##############################################
# capitalize : 首字母大写,其他字符串中的字符全是小写
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.capitalize()) # 仅仅是整个字符串的首字母变大写,其他都变成小写。
# 结果:Beijing tami keji youxian gongsi
##################### 内容居中 (center)##############################################
# center :设置总长度,内容居中
# center(self, width, fillchar=None):
# 内容居中,width:总长度;fillchar:空白处填充内容,默认为空格,但是只能填写一个字符
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.center(50,'_')) # 内容居中,总长度为50,空白处填写'_'
# 结果: _________beijing Tami KEJI YouXian GongSi_________
注:print(aa.center(50, '99'))
结果报错:只能填写一个字符
print(aa.center(50, '99'))
TypeError: The fill character must be exactly one character long
##################### 左右 填充 (just 、ljust、rjust)##############################################
# ljust(self, width, fillchar=None): (left 左 ) (right 右)
# 内容左对齐,右侧填充。
aa = "beijing Tami KEJI YouXian GongSi"
# print(aa.ljust(50,'0000')) # TypeError: The fill character must be exactly one character long
# 以上是一个错误,原因是:填充字符必须正好是一个字符长
print(aa.ljust(50,'*'),1111111)
print(aa.rjust(50,'*'),1111111)
# 结果:beijing Tami KEJI YouXian GongSi****************** 1111111
# ljust(self, width, fillchar=None):
# 内容右对齐,右侧填充。
aa = "beijing Tami KEJI YouXian GongSi"
# print(aa.ljust(50,'0000')) # TypeError: The fill character must be exactly one character long
# 以上是一个错误,原因是:填充字符必须正好是一个字符长
print(aa.rjust(50,'*'),1111111)
# 结果:beijing Tami KEJI YouXian GongSi****************** 1111111
##################### 方法返回指定长度的字符串,原字符串右对齐,前面填充0 ##############################################
# zfill(self, width):
# 方法返回指定长度的字符串,原字符串右对齐,前面填充0。
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.zfill(50))
# 结果:000000000000000000beijing Tami KEJI YouXian GongSi
##################### 统计子序列个数(count) ##############################################
# count :统计子序列个数
# count(self, sub, start=None, end=None)
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.count('i')) # 只写统计的字符,就是统计全部出现的个数
# 结果:5
print(aa.count('i',4)) # 从下标4开始寻找,一直到结束
# 结果:4
print(aa.count('i',0,4)) # 从下标0找到下标4
# 结果:1
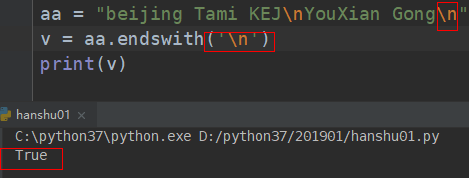
##################### 是否以什么字符结尾 (endswith)##############################################
# endswith :是否以 xxx 结束
# endswith(self, suffix, start=None, end=None)
aa = "beijing Tami KEJI YouXian GongSi"
# print(aa.endswith(suffix='ong''si'))
print(aa.endswith('Si'))
# 结果:True
print(aa.endswith('g',0,7),111111100000) # 获取字符串里大于等于0的位置,小于7的位置。
# 结果:True

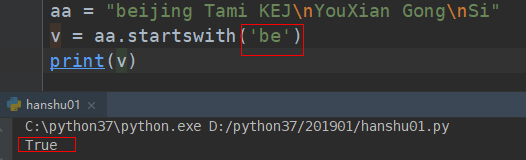
##################### 是否以什么字符串开始(startswith) ##############################################
# startswith(self, prefix, start=None, end=None):
# """ 是否起始 """
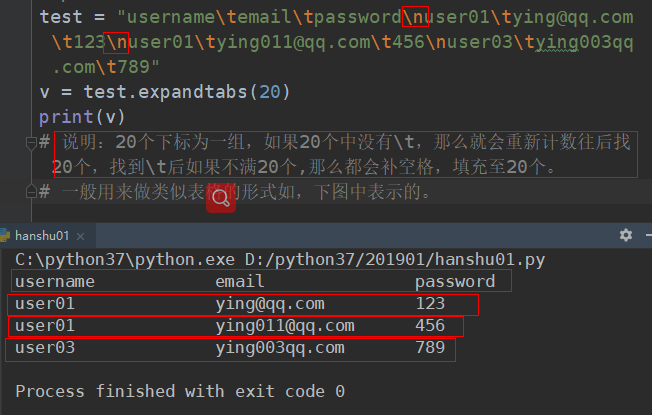
##################### tab键转换为空格 (expandtabs)##############################################
# expandtabs 默认将一个tab转换为4个空格
# expandtabs(self, tabsize=None)
aa = "beijing Tami KEJI YouXian GongSi"
print(aa)
print(aa.expandtabs()) # 默认为4个
# 结果:beijing Tami KEJI YouXian GongSi
print(aa.expandtabs(20))
# 结果:beijing Tami KEJI YouXian GongSi
##################### 左右寻找子序列 (find)##############################################

# find 寻找子序列位置,如果没找到,返回 -1 注:找到之后,只会反会第一个的下标值。
# find(self, sub, start=None, end=None)
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.find('on'))
# 结果:27 下标是27
print(aa.find('cc'))
# 结果:-1
print(aa.find('i',12)) # 从下标12 开始查找,直至结束
print(aa.find('i',0,10)) # 查找范围为下标0-10 ,只返回第一个的下标值。
# 结果:2
# rfind (self, sub, start=None, end=None):
# 从右往左查询 #找到最右边的值的下标返回,方法和find相同

s = "hello {0},age {1}"
print(s)
# 结果: hello {0},age {1}
new1 = s.format('alex',19)
print(new1)
# 结果:hello alex,age 19
# 方式二:
test = 'I am is {name},age = {age}'
v = test.format(name='xiaoming',age=19)
print(test)
print(v)
# 结果 :
I am is {name},age = {age}
I am is xiaoming,age = 19
# def format(self, *args, **kwargs):name = "my name is {name} and i am {year} old"
print(name.format(name='tami',year=30))
# my name is tami and i am 30 old
##################### 格式化(format)*** ##############################################
##################### 替换占用符 ##############################################
# 方式一:
# 格式化,将一个字符串中的占位符替换为指定的值
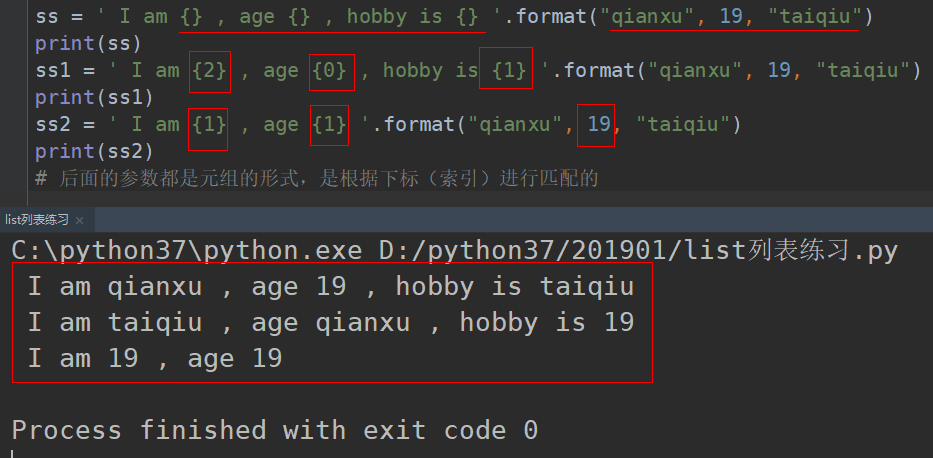
# format(*args, **kwargs) 替换符:替换的值要一 一对应才可以。
“{}{xxx}”.format(*agrs,**kwargs)
args 是位置参数,是一个元组
kwargs 是关键字参数,是一个字典
花括号表示占位符
{} 表示按照顺序匹配位置参数,{n} 表示取位置参数索引为n的值
{xxx} 表示在关键字参数中搜索名称一致的
{{}} 表示打印花括号
##### 最新整理的 format *** #########


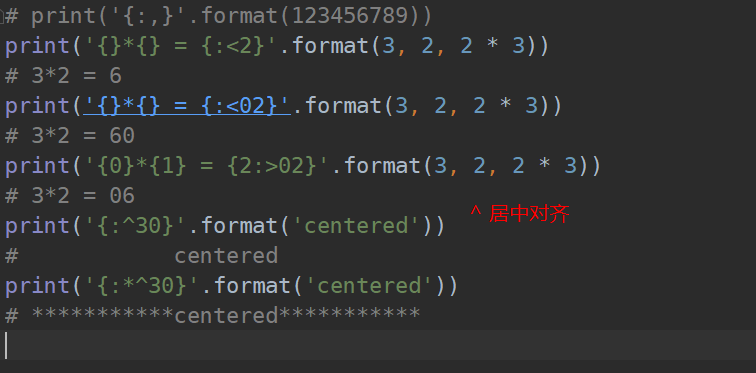
”
元组的形式:
字典的类型:

列表形式:format最终会将传入的内容都转换为元组的形式,给前面的参数对应起来。
##################### %s %d %f ########################
要么就是单个的值,要么就是元组,要么就是字典
参考地址:老男孩讲师alex博客链接
https://www.cnblogs.com/wupeiqi/articles/5484747.html
1、百分号方式
%[(name)][flags][width].[precision]typecode
- (name) 可选,用于选择指定的key
- flags 可选,可供选择的值有:
- + 右对齐;正数前加正好,负数前加负号;
- - 左对齐;正数前无符号,负数前加负号;
- 空格 右对齐;正数前加空格,负数前加负号;
- 0 右对齐;正数前无符号,负数前加负号;用0填充空白处
- width 可选,占有宽度
- .precision 可选,小数点后保留的位数
- typecode 必选
- s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置
- r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置
- c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置
- o,将整数转换成 八 进制表示,并将其格式化到指定位置
- x,将整数转换成十六进制表示,并将其格式化到指定位置
- d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
- e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)
- E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)
- f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
- F,同上
- g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)
- G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)
- %,当字符串中存在格式化标志时,需要用 %%表示一个百分号
注:Python中百分号格式化是不存在自动将整数转换成二进制表示的方式
常用格式化:
|
1
2
3
4
5
6
7
8
9
10
11
|
tpl = "i am %s" % "alex"tpl = "i am %s age %d" % ("alex", 18)tpl = "i am %(name)s age %(age)d" % {"name": "alex", "age": 18}tpl = "percent %.2f" % 99.97623tpl = "i am %(pp).2f" % {"pp": 123.425556, }tpl = "i am %.2f %%" % {"pp": 123.425556, } |
2、Format方式
[[fill]align][sign][#][0][width][,][.precision][type]
- fill 【可选】空白处填充的字符
- align 【可选】对齐方式(需配合width使用)
- <,内容左对齐
- >,内容右对齐(默认)
- =,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字
- ^,内容居中
- sign 【可选】有无符号数字
- +,正号加正,负号加负;
- -,正号不变,负号加负;
- 空格 ,正号空格,负号加负;
- # 【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示
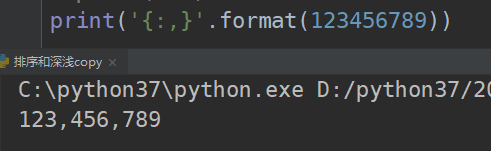
- , 【可选】为数字添加分隔符,如:1,000,000
- width 【可选】格式化位所占宽度
- .precision 【可选】小数位保留精度
- type 【可选】格式化类型
- 传入” 字符串类型 “的参数
- s,格式化字符串类型数据
- 空白,未指定类型,则默认是None,同s
- 传入“ 整数类型 ”的参数
- b,将10进制整数自动转换成2进制表示然后格式化
- c,将10进制整数自动转换为其对应的unicode字符
- d,十进制整数
- o,将10进制整数自动转换成8进制表示然后格式化;
- x,将10进制整数自动转换成16进制表示然后格式化(小写x)
- X,将10进制整数自动转换成16进制表示然后格式化(大写X)
- 传入“ 浮点型或小数类型 ”的参数
- e, 转换为科学计数法(小写e)表示,然后格式化;
- E, 转换为科学计数法(大写E)表示,然后格式化;
- f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- g, 自动在e和f中切换
- G, 自动在E和F中切换
- %,显示百分比(默认显示小数点后6位)
- 传入” 字符串类型 “的参数
常用格式化:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
tpl = "i am {}, age {}, {}".format("seven", 18, 'alex') tpl = "i am {}, age {}, {}".format(*["seven", 18, 'alex']) tpl = "i am {0}, age {1}, really {0}".format("seven", 18) tpl = "i am {0}, age {1}, really {0}".format(*["seven", 18]) tpl = "i am {name}, age {age}, really {name}".format(name="seven", age=18) tpl = "i am {name}, age {age}, really {name}".format(**{"name": "seven", "age": 18}) tpl = "i am {0[0]}, age {0[1]}, really {0[2]}".format([1, 2, 3], [11, 22, 33]) tpl = "i am {:s}, age {:d}, money {:f}".format("seven", 18, 88888.1) tpl = "i am {:s}, age {:d}".format(*["seven", 18]) tpl = "i am {name:s}, age {age:d}".format(name="seven", age=18) tpl = "i am {name:s}, age {age:d}".format(**{"name": "seven", "age": 18})tpl = "numbers: {:b},{:o},{:d},{:x},{:X}, {:%}".format(15, 15, 15, 15, 15, 15.87623, 2)tpl = "numbers: {:b},{:o},{:d},{:x},{:X}, {:%}".format(15, 15, 15, 15, 15, 15.87623, 2)tpl = "numbers: {0:b},{0:o},{0:d},{0:x},{0:X}, {0:%}".format(15)tpl = "numbers: {num:b},{num:o},{num:d},{num:x},{num:X}, {num:%}".format(num=15) |
更多格式化操作:https://docs.python.org/3/library/string.html
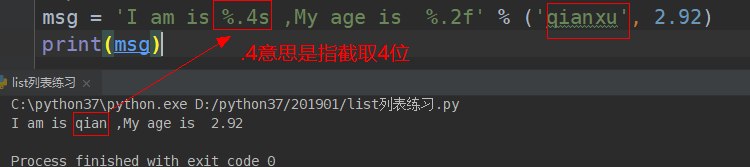
格式化另一种方式 %s %s : 是万能的
%d :只接受整型数字
%f: 浮点数
%s传一个参数时:

截取指定位数的字符:
%s传多个参数时: 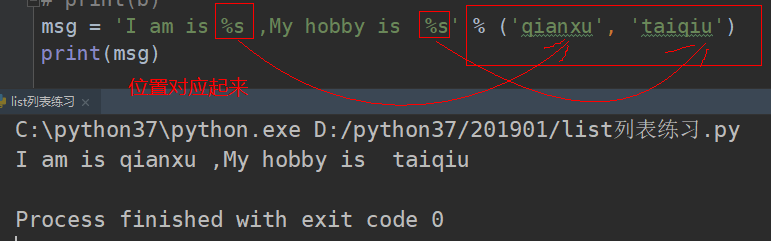
%d:只能是整型数字类型
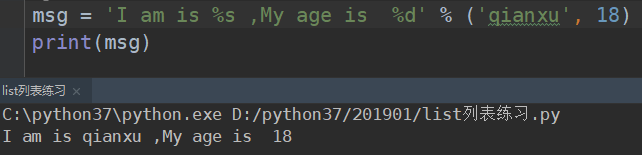
%d必须是数字填写其他类型会报错
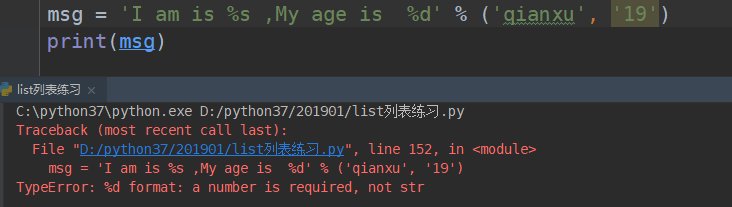
%f:浮点数(带小数点的)类型

要保留指定位数的小数:

# 打印百分比 使用两个%%,即可打印出来
注:linux中是用单引号,或者是 ,python中没有这功能,就使用2个%%
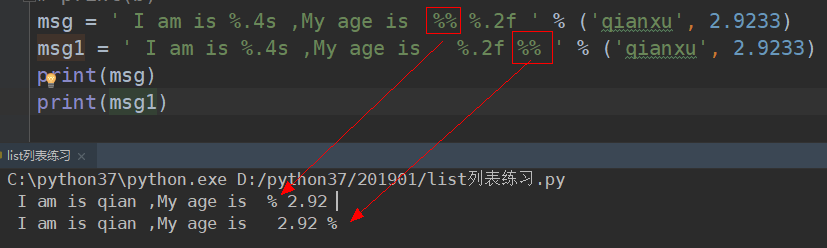
使用字典形式进行传参:
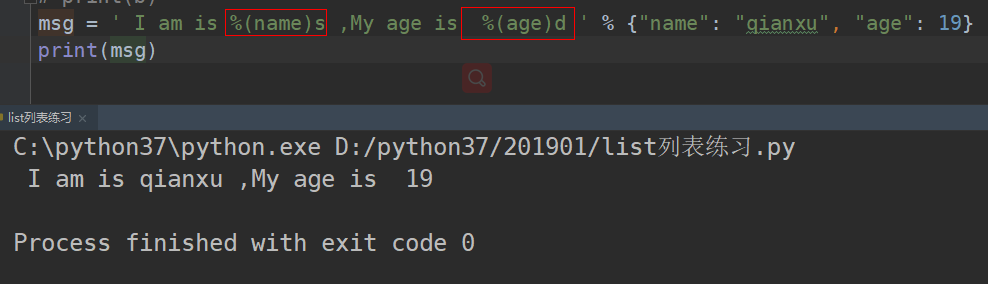
左对齐和右对齐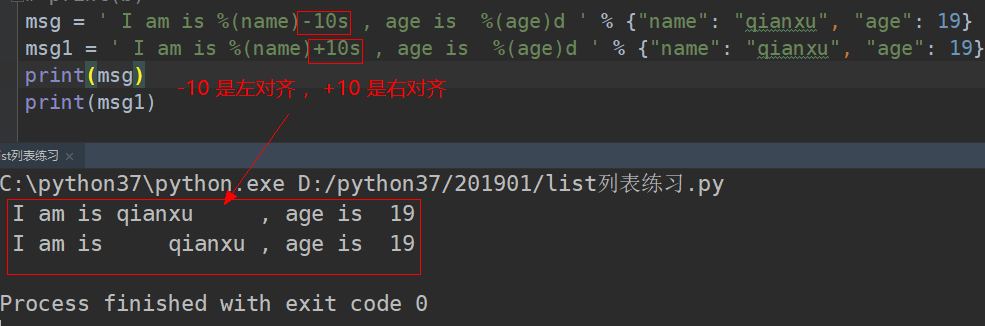
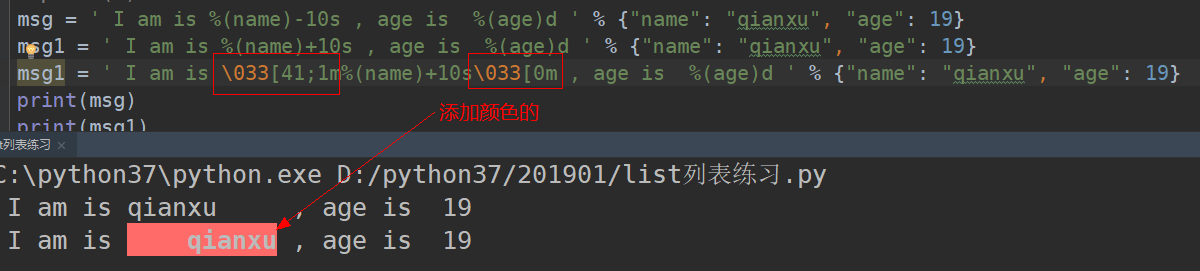
给字符串添加颜色的
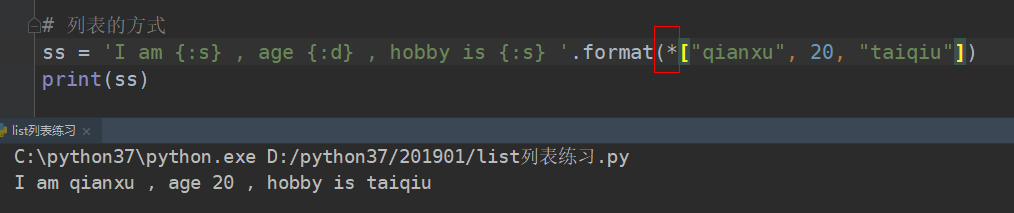
列表形式的:

直接传入列表:注意要加入一个*号
# 不同格式

##################### 格式化(format_map)##############################################
print(name.format_map({'name':"nginx",'year':33}))
# my name is nginx and i am 33 old
##################### index左右查找子序列 ##############################################
# index(self, sub, start=None, end=None)
# 子序列位置,如果没找到,报错,还是用find比较好,因为找不到返回-1
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.index('i'))
# 结果:2
print(aa.index('i',10),22222)
print(aa.index('i',7,15)) # 从下标7开始到下标15结束
# 结果:11
print('#####################################################')
# print(aa.index('adf'))
# 结果:ValueError: substring not found
# rindex(self, sub, start=None, end=None):
# 从右往左查询
##################### 判断是否是字母和数字(isalnum) ##############################################

判断字符串中 只能包含 字母和数字
# isalnum(self) # 判断是否是字母和数字
aa = "beijing Tami KEJI YouXian GongSi 111"
print(aa.isalnum())
# 结果是 False 因为字符串中有空格。
aa = "beijingamiKEJIYouXianGongSi111" #
print(aa.isalnum())
# 结果是 Ture 。
##################### 判断是否是英文或是汉字(isalpha) ##############################################
# isalpha(self)
# 判断是否是字母
aa = "beijing Tami KEJI YouXian GongSi" #中间有空格是不可以的
print(aa.isalpha())
# 结果为False
aa = "beijingTamiKEJIYouXianGongSi北京呵呵呵有限公司"
print(aa.isalpha())
# 结果为True
##################### 判断是否是十进制数字(isdecimal) ##############################################
print("1.23".isdecimal()) # 判断是否是十进制数
# Flase
print("111".isdecimal())
# True
##################### 判断是或否是数字(isdigit) ##############################################
纯数字时:
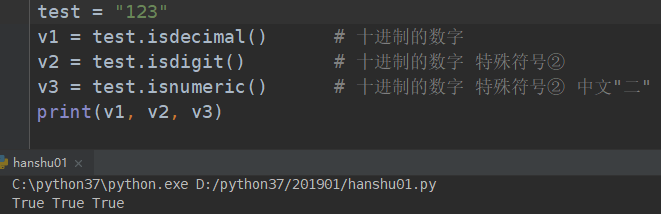
纯数字+特殊符号②时
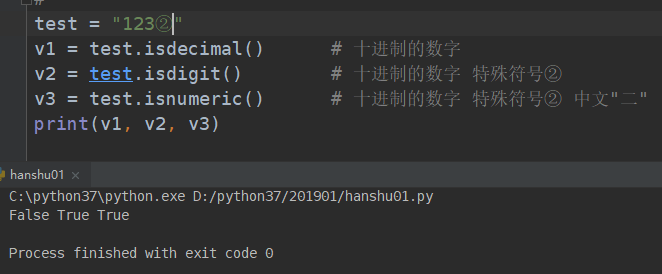
纯数字+特殊符号②时+中文二时

具体的判断范围:
经常用来判断数字的情况下,要用 isdecimal
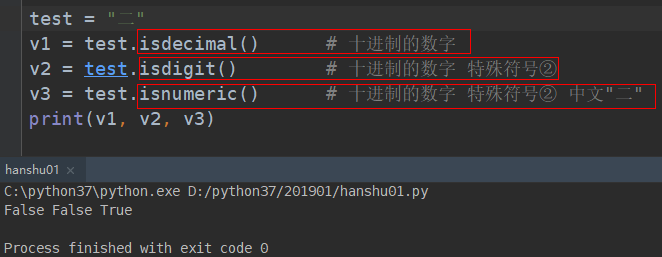
使用情况:

# isdigit(self): # 判断是否是数字digit
test = "②"
print(test.isdecimal())
# 结果为False
print(test.isdigit())
# 结果为True
##################### 判断是不是数字 (isnumeric)
# 功能好像是一样的
print("123".isnumeric())
# True
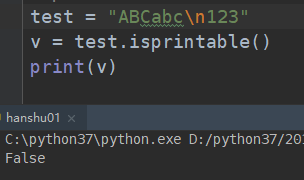
##################### 判断是否存在不可显示的字符(isprintable) ##############################################
如果字符串中含有不可见的字符的时候,会报错,一般指的就是 或者是
等等
: tab 制表符
: enter 回车换行符
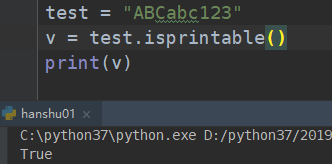
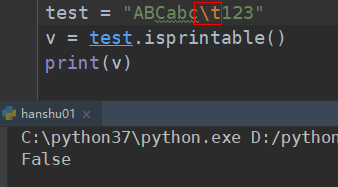
##################### 判断是不是一个合法的标识符(isidentfier) ##############################################
# def isidentifier(self): # real signature unknown; restored from __doc__
注:数字、下划线、字母 开头的都符合
print("-11".isidentifier())
# 结果:False
print("a1".isidentifier())
# 结果:True
a = "_abc123"
v = a.isidentifier()
print(v)
# 结果:True
##################### 判断字母是否全部小写(islower)或大写(isupper) ##############################################
# islower(self): # 判断全部是否小写
# isupper(self): # 判断全部是否大写
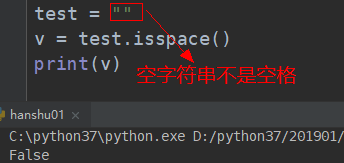
##################### 判断时候是空格(isspace)##############################################
# 判断字符串是或否全部都是空格
注:“” 空字符串不是空格
一个或者多个空格都是true

包括 或者是 也是true
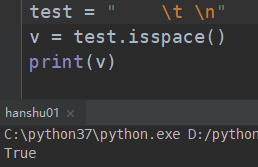
# isspace(self): # 是否空格
##################### 判断时候是标题 (istitle)##############################################
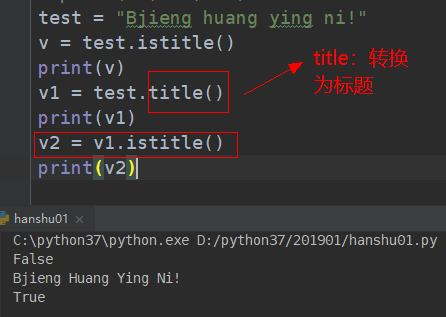
# istitle(self): # 是否是标题 注:标题必须是每个单词的首字母都要大写
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.istitle()) # False
aa = "Beijing Tami Keji Youxian Gongxi"
print(aa.istitle()) # True
##################### 连接 (join) ##############################################
# 将字符串中的每一个 元素 按照 指定分割符 进行拼接。
将可迭代对象连接起来,使用string作为分隔符
可迭代对象本身元素都是字符串
返回一个新的字符串


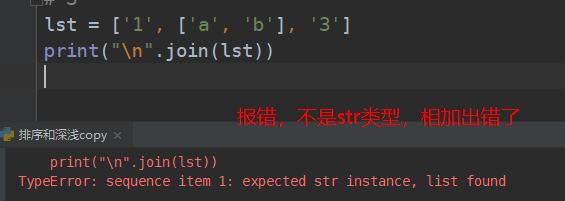
修改一下:就可以打印了。


# join 连接 列表或者是元组也是支持的。
li = ["alix","eric"]
# 变成"alix_eric"
# join(self, iterable): # iterable :表示可迭代的
lili = "_".join(li)
print(lili) # alix_eric
lili2 = "*****".join(li)
print(lili2)
# 结果: alix*****eric
# #################### 举li = "aa bb cc dd"li2 = "+".join(li)
print(li2)
# 结果:a+a+ +b+b+ +c+c+ +d+d
aa = "12345"
aa2 = "+-+".join(aa)
print(aa2)
# 结果: 1+-+2+-+3+-+4+-+5
##################### strip 移除左右空白(换行符)可指定字符进行移除
从字符串两端去除指定的字符集chars中的所有字符
如果chars没有指定,去除两端的空白字符
######################## lstrip(self, chars=None): # 移除左空白
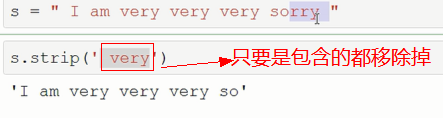
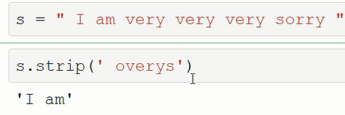
# rstrip(self, chars=None): #移除右空白
# strip(self, chars=None): #移除左右空白
aa = " beijing Tami KEJI YouXian GongSi "
print(aa.lstrip())
print(aa.rstrip())
print(aa.strip()) # strip 脱去的意思
注:默认strip()不加任何参数,是移除空白(空格、tab、 、 都可以),
加上参数以后:
trip("$") 就是移除两侧的$
移除指定字符串,优先最多匹配
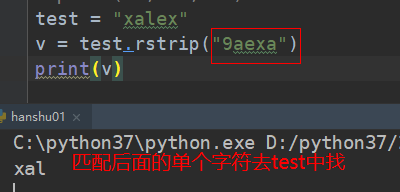
##################### 密码加密(maketrans) ##############################################
# maketrans(self, *args, **kwargs): # real signature unknown
# 可以配置随机密码,必须得一一对应
p = str.maketrans("abcdef","123456") # “”,“”数量要对应起来
print("alex li".translate(p))

##################### 字符分割(partition)从左或者是从右 ,只切一刀。##############################################
partition(sep)
从左至右,遇到分隔符就把字符串分隔成两部分,返回头,分隔符、尾三部分的三元组;如果没有找到分隔符,返回头,两个空元素的三元组。
sep 分隔字符串,必须指定
切一刀用partition ,切多刀就用split

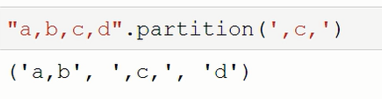
# partition(self, sep):
# 分隔、前,中,后,三部分 ,默认是从左往右
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.partition('i'))
# 结果:('be', 'i', 'jing Tami KEJI YouXian GongSi')
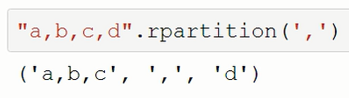
# rpartition(self, sep): # 从右往左
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.rpartition('i'))
# 结果:('beijing Tami KEJI YouXian GongS', 'i', '')
##################### 字符替换(replace) ** ##############################################
# replace(old, new, count=None):
字符串中找到匹配替换为新子串,返回新字符串。
count 表示替换几次,不指定就是全部替换。
print('www.tamiyun-wz.com'.replace('w', 'o'))
# ooo.tamiyun-oz.com
# 将w 替换为o,没有指定次数,就是全部替换
print('www.tamiyun-wz.com'.replace('w', 'o', 2))
# oow.tamiyun-wz.com
# 将w 替换为o,指定次数为2次
print('www.tamiyun-wz.com'.replace('w', 'o', 3))
# ooo.tamiyun-wz.com
# 将w 替换为o,替换3次
print('www.tamiyun-wz.com'.replace('ww', 'p', 2))
# pw.tamiyun-wz.com
# 将ww 替换为p ,替换2次
print('www.tamiyun.com'.replace('www', 'python', 2))
# python.tamiyun-wz.com
# 将www 替换为python 替换两次
# 替换 默认是替换全部
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.replace('i','0000'))
# 结果:beijing Tami KEJI YouXian gongsi
print(aa.replace('i','0000',2))
# 结果:be0000j0000ng Tami KEJI YouXian GongSi 2是从左往右替换俩
##################### 字符左右分隔 (split、rsplit)##############################################
split(sep = Nome,maxsplit=-1)
从左至右
sep指定分隔字符串,缺省情况下空白字符串作为分隔符
maxsplit 指定分隔的次数,-1 表示遍历整个字符串
默认是按照 尽可能多的 连成一起的空白字符 作为一个分隔符。空白字符+(一个或N个)

# rsplit(self, sep=None, maxsplit=None): # 默认是使用的空白字符进行分割的,立即返回一个列表。
# """ 分割, maxsplit最多分割几次 """
aa = "beijing Tami KEJI YouXian GongSi"
bb = aa.split('o') # 找到所有的o做分隔符
print(bb)
# 结果:['beijing Tami KEJI Y', 'uXian G', 'ngSi']
bb = aa.split('o',1) # 找到第一个o做分隔符,后面的o不生效
print(bb)
# 结果:['beijing Tami KEJI Y', 'uXian GongSi']



默认是按照 尽可能多的 连成一起的空白字符 作为一个分隔符。空白字符+(一个或N个)
##################### 根据换行符 分隔 (splitlines) ##############################################
# splitlines(self, keepends=False):
# """ 根据换行分割 """
aa = "beijing Tami KEJ YouXian GongSi"
print(aa.splitlines())
# 结果:['beijing Tami KEJ', 'YouXian GongSi']

##################### 大小写互转 (swapcase)##############################################
# swapcase(self):
# 大写变小写,小写变大写
aa = "beijing Tami KEJ YouXian GongSi"
print(aa.swapcase())
# 结果:BEIJING tAMI kej yOUxIAN gONGsI
##################### 变成大写(upper) ##############################################
一般用来是输入验证码的时候,统一变成小写或者是大写
# upper(self):
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.upper())
# 结果:BEIJING TAMI KEJI YOUXIAN GONGSI # 不管是大写还是小写都变成大写
##################### 变成小写(lower) ##############################################.
一般用来是输入验证码的时候,统一变成小写或者是大写
# upper(self):
aa = "beijing Tami KEJI YouXian GongSi"
print(aa.upper())
# 结果:beijing tami keji youxian gongsi # 不管是大写还是小写都变成小写
##################### 转换为标题(title) ##############################################
# title(self): # 单词的首字母大写
aa = "beijing Tami KEJ YouXian GongSi"
print(aa.title())
# 结果:Beijing Tami Kej Youxian Gongsi # 首字母不管是大写还是小写都变成大写
##################### 转换,需要先做一个对应表,最后一个表示删除字符集合 ##############################################
# translate(self, table, deletechars=None):
# 转换,需要先做一个对应表,最后一个表示删除字符集合
aa = "beijing Tami KEJI YouXian GongSi"
# 这个先不用理解
##################### 索引和切片 ##############################################
aa = "beijing Tami KEJI YouXian GongSi"
# 索引
print(aa[0])
# 结果:b
# (长度)
aa = "beijing Tami KEJI YouXian GongSi"
print(len(aa))
# 32
# 切片
aa = "beijing Tami KEJI YouXian GongSi"
print(aa[0:2])
# be
# #循环 遍历字符串中的所有元素
# start = 0
# while start < len(aa):
# temp = aa[start]
# print(aa[start])
# start += 1
# for 循环
for i in aa:
if i == "i":
continue
print(i)