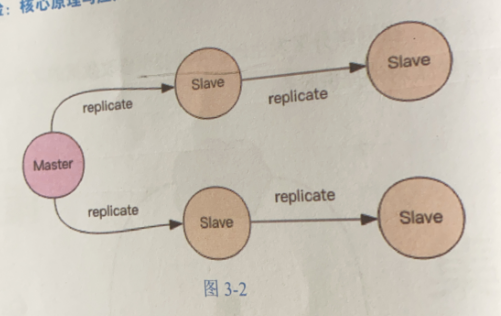
主从同步
当主节点(Master)挂掉的时候,运维让从节点(slave)过来接管,服务就可以继续,否则主节点需要经过数据恢复和重启的过程。
CAP原理
分布式存储的理论基石
- C:Consistent,一致性
- A:Availability,可用性
- P:Partition tolerance,分区容忍性
分布式系统的节点往往都是分布在不同的机器上进行网络隔离的,网络分区。
网络分区:两个节点之间不能通信
网络分区发生时,一致性和可用性两难全
最终一致
Redis的主从数据是异步同步的,所以分布式系统并不满足一致性,但是满足可用性
但是满足最终一致性,因为网络恢复后,从节点会采用各种策略努力追赶恢复的。
Redis同步支持主从同步和从从同步
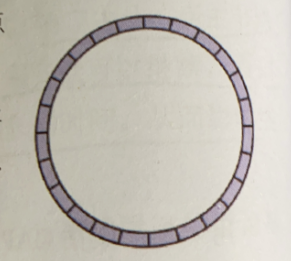
增量同步
主节点将修改主节点状态的指令 写入 下图环状的buffer数组当中,循环一直覆盖写。
从节点一直从上面读指令,达到和主节点一致的状态、、、并且返回自己复制到哪儿了
但是遇到网络问题,那么指令就会被覆盖掉
这个时候就需要快照同步。
快照同步
在主节点上来一次bgsave,将当前内存的数据全部快照到磁盘文件中
然后,再将快照文件发送给从节点。从节点来一个全量加载
加载之前先要将当前内存的数据清空,加载完毕后通知主节点继续进行增量同步
但是!!!!这个时候,主节点的buffer还是在一直复制的,如果快照时间过长或者buffer的太小,那么就会造成快照死循环。
增加从节点
当从节点刚刚加到集群中,必须来一次快照同步,才能进行增量同步
无盘复制
主要指快照同步
主节点直接通过套接字将快照内容发送到从节点
主节点会一边遍历内存,一边将序列化的内容发送到从节点,从节点将收到的内容加载到磁盘,最后再进行一次加载。
wait指令
Redis的复制是异步的,wait指令可以让异步复制变身同步复制,确保系统的强一致性
set key value
wait 1 0
两个参数:第一个参数从节点的数量;第二个参数是时间t。
等待wait指令之前的所有写操作同步到N个从节点,最多等待时间t,等待从节点同步。如果t=0,表示无限等待直到N个从节点同步完成。
假设此时出现了网络分区,wait指令第二个参数为0,那么redis服务器就失去了可用性
Sentinel
哨兵系统,主节点坏了,自动将从节点升级为主节点,不用手动
Sentinel负责持续监控主从节点的健康,当主节点挂了,自动选择一个最优的从节点切换为主节点。
客户端连接集群,会首先连接Sentinel,通过Sentinel来查询主节点的地址,然后再连接主节点进行数据交互。
当主节点故障了,客户端会重新想Senatinel要地址,Sentinel会将最新的主节点告诉客户端。
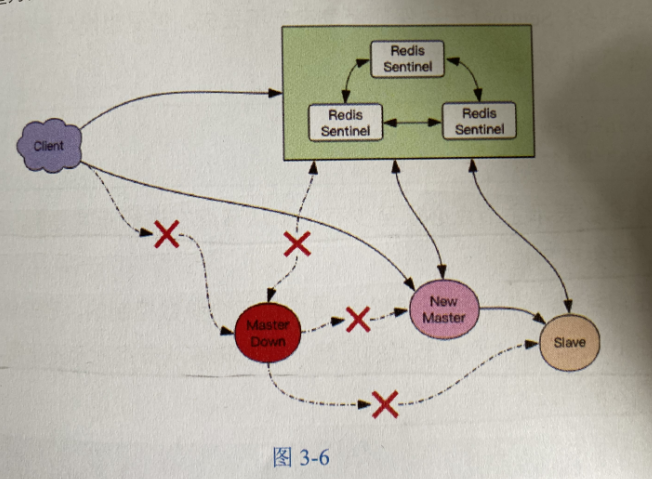
当主节点恢复之后,自动称为从节点。
消息丢失
Sentinel无法保证数据不丢失,但是尽量保证信息少丢失
限制主从延迟不要太大
# 保证至少一个从节点正常复制 min-slave-to-write 1 #什么是正常复制,那就是每过10s收到从节点的反馈 min-slaves-max-lag 10
Sentinel基本用法
客户端通过Sentinel来发现从节点的地址,然后再通过地址建立相应的连接。
Sentinel默认端口为26379
客户端如何知道地址发生改变?
------建立连接的时候进行主节点地址变更判断
连接池建立新连接时,会去查询主节点地址,然后跟内存中的主节点地址进行比对,如果变更了,就断开所有连接,重新使用新地址进行连接。如果旧的主节点挂掉了,那么所有正在使用的连接都会关闭,然后在重连时就会用上新地址
Codis分而治之
单个Redis内存不宜过大,内存太大导致rdb文件过大,进一步导致主从同步时全量同步时间过长,在实例重启恢复时也会消耗很长的数据加载时间。
Codis:将众多小内存的Redis实例整合起来,将分布在多台机器上的众多CPU核心的计算能力聚集在一起,完成海量数据存储和高并发读写操作
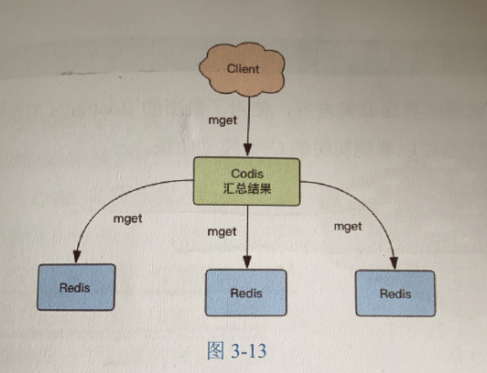
当客户端向Codis发送指令时,Codis负责将指令转发到后面的Redis实例来致性,并且将结果返回给客户端。
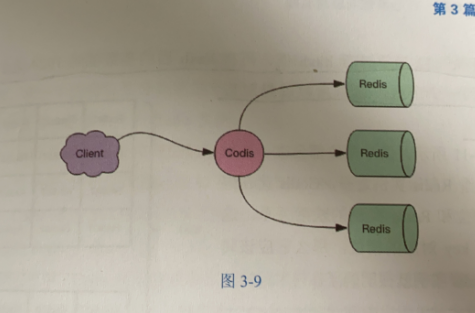
Codis是一个转发代理中间件,可以启动多个Codis实例,供客户端使用,每个Codis节点都是对等的。
还可以起到容灾功能
Codis分片原理
Codis负责将特定的key转发到特定的Redis实例中
Codis默认将所有的key划分为1024个槽位,将key进行hash,然后得到槽位。然后到相应的redis实例当中查询
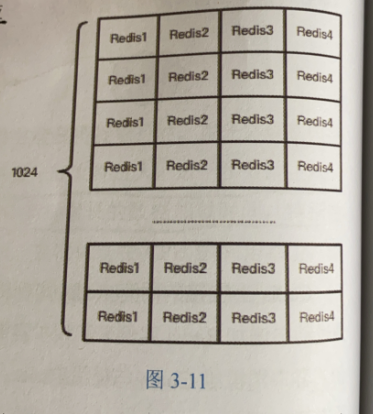
不同的Codis实例之间槽位关系如何同步?
利用zookeeper,存储Codis实例和槽位之间的通信,多个Codis之间同步。
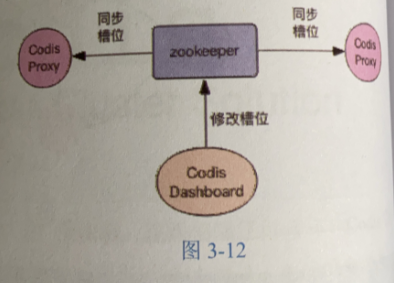
扩容
Codis本来只有一个Redis实例,接下来新加了一个,那么就会将一半的槽位分给新的节点。
利用SLOTSSCAN指令扫描一个槽下的所有key,然后挨个迁移。
迁移的时候,Codis的槽有可能还在接收新的key-----------------------那么,COdis接收到位于正在迁移槽位中的key后,会立即强制对当前的单个key进行迁移,迁移完成后,再将请求转发到新的Redis实例中
自动均衡
Codis会查看每个Redis对应的槽位,然后自动均衡负载
Codis的代价
- 不支持事务
- 迁移会变得困难
- 网络开销变大,毕竟多走了一个网络节点
Codis的优点
简单
mget指令的操作过程
架构变迁
毕竟不是官方的,老是随着官方的redis改变
Codis尴尬
不是亲生的
Codis后台管理
一个很友好的后台web界面
Cluster
redis Cluster去中心化的集群方案
集群由三个Redis节点组成,每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样。二进制协议通信
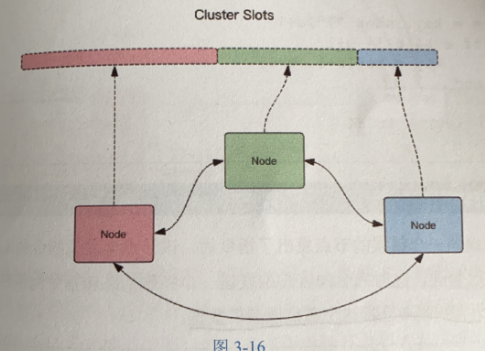
将数据划分为16384个槽位,每个节点负责其中一部分槽位。
客户端来连接集群,会得到一份集群的槽位配置信息,然后通过这个配置信息去查询完事了。
客户端需要缓存槽位的信息,可能客户端和服务器存储槽位的信息不一致的情况,这个时候还需要校准。
Redis Cluster的每个节点会将集群的配置信息持久化到配置文件中,所以必须保证配置文件时可写的,而且尽量不要依靠人工修改配置文件
槽位定位方法
将key进行hash,然后将哈希值与槽位进行哈希
Redis Cluster允许将用户强制把某个key挂在特定的槽位上
跳转
当节点发现客户端的请求中的槽位并不归属自己管,就会给客户端发送一个带跳转地址的信息,让客户端去连接这个节点获取数据
迁移
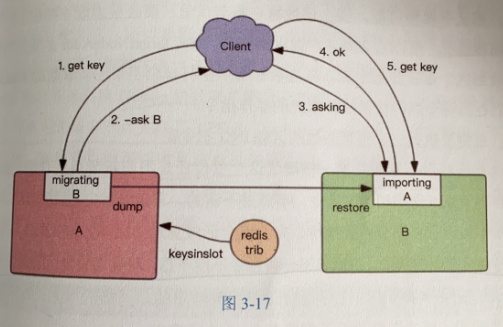
从源节点获取内容---存区目标节点------从源节点中删除
整个转移过程中,转移是一步一步的,假如单个key过大,那会引起卡顿的。
客户端首先会访问旧节点,找到了还好,找不到旧节点会重定向;----客户端向新节点询问下Asking,然后再致性原先的操作指令。Asking指令避免重定向循环。
容错
每个节点设置几个从节点,当主节点发生故障时,集群就会自动升级从节点;同时允许若干个主节点发生故障
网络抖动
有时候,有些节点突然失联,突然又连接上了,Redis Cluster给一个失联的时间,超过这个时间就表示失联了;主从切换。
cluster-node-timeout
可能下线和确定下线
Redis cluster是去中心化的,一个节点认为某个节点失联了,并不管用,只有大多数节点都认定某个节点失联了,集群才认识该节点需要进行主从切换来容错。
比如:某个节点发现某个节点失联了(PFail),它会将这条信息向整个集群广播,其它节点就可以收到这点的失恋信息。如果收到了某个节点失联的数量已经达到了集群的大多数,就可以标记这个节点失联。Fail
Cluster基本用法
导入redis-py-cluster模块才可以使用
cluster不支持事务:Cluster的mget方法比redis要慢很多,被拆分成了多个get指令;Cluster的rename方法不再是原子的,它需要将数据从源节点转移到目标节点。
槽位迁移感知
客户端保存了槽位和节点的映射关系表,它需要及时得到更新。
moved指令:客户端请求了错误的节点,节点指挥客户端重定向到正确的节点上。并且刷新客户端的配置信息
asking指令:再迁移时发送的指令。
不过上述的两个指令都是重试指令,需要限制重试的次数。高于这个次数就报错
集群变更感知
当服务节点变更时,客户端应该立即得到通知以实时刷新自己的节点关系表。那么客户端是如何知道的
- 目标节点挂掉了,客户端抛出ConnectionError指令,紧接着随机挑一个节点来重试,然后提供moved指令进行重试
- 运维手动修改集群信息,将主节点切换到其它节点,并将旧的主节点移除出集群,这时打在旧节点上的指令会受到ClusterDown错误,然后客户端关闭所有的连接,清空槽位映射关系表,重新尝试初始化节点信息