sql基础

--单表查询
select * from student;
select * from score;
--投影查询
select * from student;
--条件查询
select * from student
where sno=001 or sno=004 ;
--查询001 和004两条记录
select * from student
where sno in (001,004);
--查询001~004之间的记录
select * from student
where sno between 001 and 004;
注意in 和between and 的用法。
--模糊查询
select * from student
where name like '_五%';
_ 表示有且仅有一个字符,而%表示有0~无穷大个字符。 这里特别注意,name列使用char(10)类型的,而这里记录比如name=“王五” 两个汉字代表4个字符,那么剩下的6个字符会变成空格放在值的后面,而此时'_五%'不能用'_五' 来查询,因为‘五’的后面还有空格.
- order by 用法如下,company的值可能相同,如果company相同的数据以orderNumber升序排列

聚合函数
- 聚合函数是对一组值执行计算并返回单一的值的函数,它经常与SELECT语句的GROUP BY子句一同使用,SQL SERVER 中具体有哪些聚合函数呢?
1. AVG 返回指定组中的平均值,空值被忽略。
例:select prd_no,avg(qty) from sales group by prd_no
2. COUNT 返回指定组中项目的数量。
例:select count(prd_no) from sales
3. MAX 返回指定数据的最大值。
例:select prd_no,max(qty) from sales group by prd_no
4. MIN 返回指定数据的最小值。
例:select prd_no,min(qty) from sales group by prd_no
5. SUM 返回指定数据的和,只能用于数字列,空值被忽略。
例:select prd_no,sum(qty) from sales group by prd_no
- gourp by的使用 : 先分组后在执行聚合函数。
-
-
select avg(sal) as 平均工资 from emp group by deptno
having avg(sal)>2000需要注意的一点,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。
group by后面不能跟where 只能跟having
-
-
- truncate table tablename 删除表,不记录日志文件,删除后不能恢复,而delete table tablename 删除表,记录文件,可恢复。
truncate删除数据速度很快。
-
--删除重复数据
select distinct deptno from emp;

- 1. union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
2. union All:对两个结果集进行并集操作,包括重复行,不进行排序;
3. intersect:对两个结果集进行交集操作,不包括重复行,同时进行默认规则的排序;
4. minus:对两个结果集进行差操作,不包括重复行,同时进行默认规则的排序。
select sal as 平均工资
from emp
where sal>3000
union All
select sal as 平均工资
from emp
where sal<1000;
结果:

多表查询
--多表查询
select dept.loc,emp.job
from dept,emp
where dept.deptno=emp.deptno;
如果多个表中有列名相同的列,那么必须指定哪张表 ,例dept.loc。 这种方式仅适用于数据量小的,因为这种查询先执行select dept.loc,emp.job from dept,emp ,数据量相当于把两个表的数据量相乘形成笛卡尔积,然后再根据where条件筛选。数据量比较大的时候一般用连接查询:
连接查询:1.内连接:对等连接和不对等连接
2.外连接:左外连接和右外连接
3.cross连接(交叉连接)
4.全外连接
5.子查询:相关子查询、嵌套子查询、多列子查询
--对等连接
--查询员工号、姓名、薪水、工作所在地 select empno,ename,sal,loc from emp inner join dept on dept.deptno=emp.deptno
on相当于where 后跟条件。
--不对等连接
--查询员工号、姓名、薪水、薪水等级 select empno,ename,sal,grade from emp inner join salgrade on emp.sal between salgrade.losal and salgrade.hisal;
先把emp表的empno,ename,sal数据列出来,然后找sal值在losal和hisal之间的grade连接起来。
- 左外/右外连接:
两个表:
A(id,name)
数据:(1,张三)(2,李四)(3,王五)
B(id,name)
数据:(1,学生)(2,老师)(4,校长)
左连接结果:
select A.*,B.*
from A
left join B on A.id=B.id;
1 张三 1 学生
2 李四 2 老师
3 王五 NULL NULL
右链接结果:
select A.*,B.*
from A
right join B on A.id=B.id;
1 张三 1 学生
2 李四 2 老师
NULL NULL 4 校长
****************
左外连接:以左边表为基准表,无条件列出本表数据,右表数据如果跟左边一样的补在左表后面,不一样的留空。
补充:下面这种情况就会用到外连接
比如有两个表一个是用户表,一个是交易记录表,如果我要查询每个用户的交易记录就要用到左外外连接,因为不是每个用户都有交易记录。
用到左外连接后,有交易记录的信息就会显示,没有的就显示NULL,就像上面我举得例子一样。
如果不用外连接的话,比如【王五】没有交易记录的话,那么用户表里的【王五】的信息就不会显示,就失去了查询所有用户交易记录的意义了。
--cross连接
select t1.*,t2.*
from t1,t2
返回被连接的两个表所有数据行的笛卡尔积,返回到的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。
- 全外连接:以两个表为基准表。

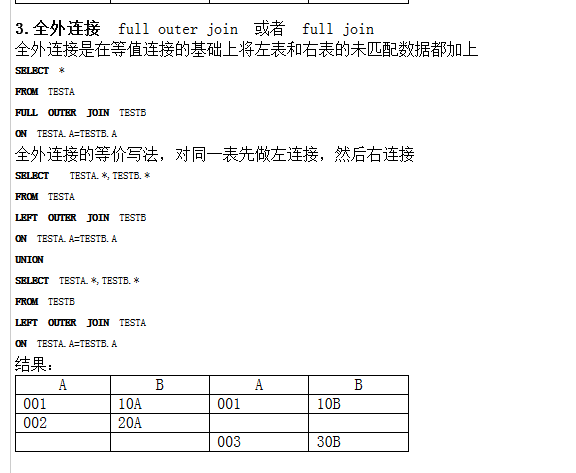
- 嵌套子查询:子查询的结果可以独立运行
--查询低于公司平均工资的员工信息
--嵌套子查询
select * from emp
where sal<(
select avg(sal) from emp
);
- 相关子查询:子查询不能独立运行。
--查询各个部门中,哪些员工的工资低于所在部门的平均工资
select * from emp out_emp
where sal<(
select avg(sal)
from emp in_emp
where in_emp.deptno=out_emp.deptno
)
序列

CREATE SEQUENCE sequence //创建序列名称
[INCREMENT BY n] //递增的序列值是n 如果n是正数就递增,如果是负数就递减 默认是1
[START WITH n] //开始的值,递增默认是minvalue 递减是maxvalue
[{MAXVALUE n | NOMAXVALUE}] //最大值
[{MINVALUE n | NOMINVALUE}] //最小值
[{CYCLE | NOCYCLE}] //循环/不循环
[{CACHE n | NOCACHE}];//分配并存入到内存中
create table score(
id int primary key,
math int,
chinese int
);
create sequence se_score
start with 1
increment by 1
insert into score values(se_score.nextval,90,80);
视图
- 用户可以通过视图以不同形式来显示基表中的数据,视图的强大之处在于它能够根据不同用户的需要来对基表中的数据进行整理。视图常见的用途如下:
通过视图可以设定允许用户访问的列和数据行,从而为表提供了额外的安全控制
隐藏数据复杂性。
create view v_emp
as
select *
from emp
select * from v_emp;