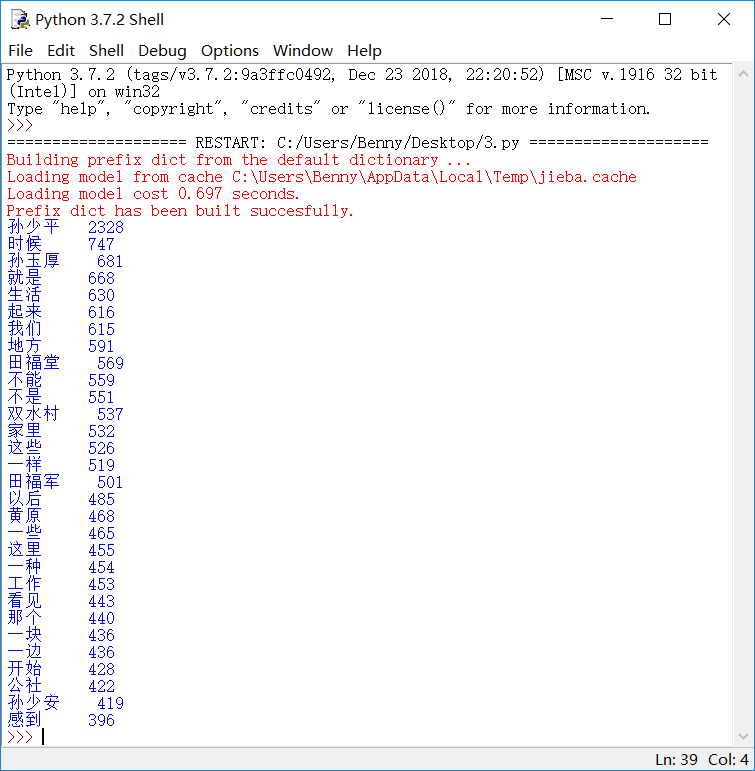
import jieba jieba.add_word("福军") jieba.add_word("少安") excludes={"一个","他们","自己","现在","已经","什么","这个","没有","这样","知道","两个"} txt = open("D:\Users\Benny平凡的世界.txt", "r", encoding='utf-8').read() words = jieba.lcut(txt) # 使用精确模式对文本进行分词 counts = {} # 通过键值对的形式存储词语及其出现的次数 for word in words: if len(word)==1: continue elif word =="少平": rword="孙少平" elif word =="少安": rword="孙少平" elif word =="玉厚"or word=="父亲": rword="孙玉厚" elif word =="福军": rword="田福军" else: rword=word counts[rword]=counts.get(rword,0)+1 for word in excludes: del(counts[word]) items=list(counts.items()) items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序 for i in range(30): word, count = items[i] print("{0:<5}{1:>5}".format(word, count))