这里介绍Python中使用Pandas读取Excel的方法
一、软件环境:
OS:Win7 64位
Python 3.7
二、文件准备
1、项目结构:

2、在当前实验文件夹下建立一个Source文件夹,里面放待读取的Excel文件
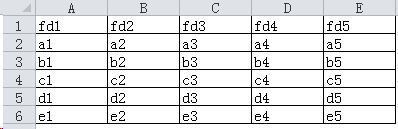
3、待读取的Excel文件名:Book1.xlsx,Sheet Name:Sheet1
内容示例:
三、代码参考
代码中已进行了注释说明,这里就不重复说明了。
1、第一行作为列名处理,数据的第1行实际是从Excel的第2行开始,数据的最大行数等于Excel的最大行数减1
#! -*- coding utf-8 -*- #! @Time :2019/3/20 22:00 #! Author :Frank Zhang #! @File :Pandas_ReadExcelV1.0.py #! Python Version 3.7 """ 模块功能:读取当前文件夹下的Source里的Excel文件,显示其相关信息 说明:默认把Excel的第一行当做列名,数据的第1行是从Excel的第2行开始 这里获取的最大行是Excel的最大行减去作为列名的第1行 """ import pandas as pd sExcelFile="./Source/Book1.xlsx" df = pd.read_excel(sExcelFile,sheet_name='Sheet1') #获取最大行,最大列 nrows=df.shape[0] ncols=df.columns.size print("=========================================================================") print('Max Rows:'+str(nrows)) print('Max Columns'+str(ncols)) #显示列名,以列表形式显示 print(df.columns) #显示列名,并显示列名的序号 for iCol in range(ncols): print(str(iCol)+':'+df.columns[iCol]) #列出特定行列,单元格的值 print(df.iloc[0,0]) print(df.iloc[0,1]) print("=========================================================================") #查看某列内容 #sColumnName='fd1' print(df[sColumnName]) #查看第3列的内容,列的序号从0开始 sColumnName=df.columns[2] print(df[sColumnName]) #查看某行的内容 iRow=1 for iCol in range(ncols): print(df.iloc[iRow,iCol]) #遍历逐行逐列 for iRow in range(nrows): for iCol in range(ncols): print(df.iloc[iRow,iCol]) print('=====================================End==================================')
2、不把第1行作为列名,读取Excel那就没有列名,需增加参数:header=None
代码如下:
#! -*- coding utf-8 -*- #! @Time :2019/3/20 9:44 #! Author :Frank Zhang #! @File :Pandas_ReadExcelV1.1.py #! Python Version 3.7 """ 模块功能:读取当前文件夹下的Source里的Excel文件,显示其相关信息 说明:数据从第1行开始,不设列名,不把第1行作为列名 这里获取的最大行就是是Excel的最大行 """ import pandas as pd sExcelFile="./Source/Book1.xlsx" df = pd.read_excel(sExcelFile,sheet_name='Sheet1',header=None) #获取最大行和最大列数 nrows=df.shape[0] ncols=df.columns.size print("=====================================================") print('Max Rows: '+str(nrows)) print('Max Columns: '+str(ncols)) #显示某特定单元格的值 print(df.iloc[0,0]) print(df.iloc[0,1]) print("=====================================================") #查看某行的内容 print("====================显示某一行=======================") #iRow=1 print("请输入行号(1-"+str(nrows)+"):") iRow=int(input())-1 for iCol in range(ncols): print(df.iloc[iRow,iCol]) print("====================显示某一列=======================") #iCol=1 print("请输入列号(1-"+str(ncols)+"):") iCol=int(input())-1 if iCol>=0 and iCol<=ncols: for iRow in range(nrows): print(df.iloc[iRow,iCol]) else: print('输入了错误的列号') #遍历逐行逐列 print(" 逐行逐列显示:") for iRow in range(nrows): for iCol in range(ncols): print(df.iloc[iRow,iCol]) print('=========================End=========================')
示例2增加了动态输入行号和列号,显示相应行列的内容。
这两个示例都是可以运行的。