(一)使用Requests存储网页
Requests
是什么?网络资源(URLs)抓取套件
优点?
- 改善urllib2的缺点,让使用者以最简单的方式获取网络资源
- 可以使用REST操作(POST,PUT,GET,DELETE)存取网络资源
import requests
response = requests.get('http://blog.sina.com.cn/lm/stock/')
print(response.text)模拟HTTP的GET方法存储网页,获取网页的内容,这时我们发现我们获取的结果是乱码,为什么呢?
- 我们所抓取网页是UTF8的,但是python在请求的时候,把它误判为不知道是什么编码,因此把这个编码显示为预设编码:ISO-8859-1
import requests
response = requests.get('http://blog.sina.com.cn/lm/stock/')
print(response.encoding)显示结果为ISO-8859-1,所以我们要告诉python我们遇到的网页是utf8,下面代码改进如下,我们便可以获得一个简体中文的内容:
import requests
response = requests.get('http://blog.sina.com.cn/lm/stock/')
response.encoding = 'utf-8'
print(response.text)现在我们还有一个问题,该如何把上面非结构化的数据转化为结构化的数据呢?—DOM TREE方法
(二)用BeautifulSoup解析网页
1.基础铺垫-DOM TREE
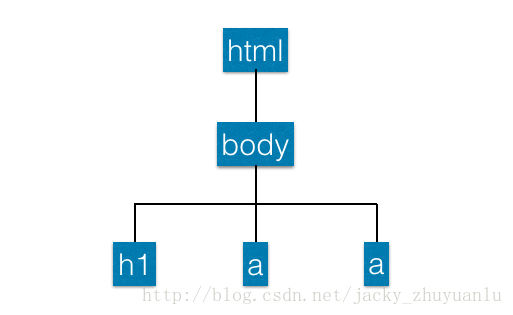
- 全称:Document Object Model Tree,它是一组API,可以跟网页的元素进行互动,使用BeautifulSoup就可以把网页变成一个DOM TREE,我们就可以根据DOM TREE的节点进行操作

- 上图的举例,最外面结构是html,是最上层的节点,下面一层是body,里面包含h1和a两个链接,这些就组成了DOM TREE的架构,我们就可以根据这个架构下的某些节点进行互动,我们可以取得h1里面的词,也可以取得a里面的词,这时候我们就可以把数据顺利提取出来;
2.BeautifulSoup范例
- 将网页读进BeautifulSoup中
from bs4 import BeautifulSoup
html_sample = '
<html>
<body>
<h1 id="title">Hello World</h1>
<a href="#" class="link">This is link1</a>
<a href="# link2" class="link">This is link2</a>
</body>
</html> '
soup = BeautifulSoup(html_sample)
print(soup.text)
- 这里会显示警告信息,警告信息告诉我们这段代码没有使用到我们的剖析器,这时python会预测一个剖析器给我们,如果我们要避免这种警告的产生,我们可以在代码中指明
soup = BeautifulSoup(html_sample,'html.parser')3.找出所有含有特定标签的HTML元素
另外需要考虑的是,即使我们可以利用BeautifulSoup将标签移除掉,但有时我们要抓取的一些内容还位于特殊的标签之中,我们该怎样把特殊标签,以及节点中的资料取出来?
- 使用select找出含有h1标签的元素
soup = BeautifulSoup(html_sample)
header = soup.select('h1')
print(header)- 使用select找出含有a标签的元素
soup = BeautifulSoup(html_sample)
alink = soup.select('a')
print(alink)下面我们实操一下:
from bs4 import BeautifulSoup
html_sample = '
<html>
<body>
<h1 id="title">Hello World</h1>
<a href="#" class="link">This is link1</a>
<a href="# link2" class="link">This is link2</a>
</body>
</html> '
soup = BeautifulSoup(html_sample,'html.parser')
header = soup.select('h1')
print(header)显示的结果为:

- 如何进一步把上面的文字解开?加上[0],可以去掉中括号,加.text可以把里面的文字取出来
print(header[0].text)
4.取得含有特定CSS属性的元素
除了标签以外,我们该怎样取得特定的元素?我们可以透过CSS的属性去取得里面的元素,CSS是网页的“化妆师”,透过这个化妆师,我们可以对网页进行点缀
(1)如何要抓取独立不重复的元素,可以加上id的修饰
- 使用select找出所有id为title的元素(id前面需加#)
alink = soup.select('#title')
print(alink)(2)如果要抓取重复的元素,可以加上class的修饰
- 使用select找出所有class为link的元素(class前面需加 . )
soup = BeautifulSoup(html_sample)
for link in soup.select('.link'):
print(link)5.取得含有特定CSS属性的元素
在网页的连接上,我们会用 a tag 去连接不同的网页,a tag 有一个属性就叫href,透过这个属性我们才能连接到不同的网页;
- 使用select找出所有a tag 的href连结
alinks = soup.select('a')
for link in alinks:
print(link['href'])