大白话讲解MobileNet-v3
(38条消息) 大白话讲解MobileNet-v3_期待黎明的博客-CSDN博客
大白话讲解MobileNet-v3

 3400
3400  收藏 9
收藏 9大白话讲解MobileNet-v3
MobileNet-v3可以说是轻量化网络的集大成者,所以在介绍MobileNet-v3之前我们有必要了解一下目前的一些轻量化网络及特点。
1.轻量化网络
在移动端部署深度卷积网络,无论什么视觉任务,选择高精度的计算量少和参数少的骨干网是必经之路。轻量化网络是移动端的研究重点,目前的一些主要的轻量化网络及特点如下:
SqueezeNet:提出Fire Module设计,主要思想是先通过1x1卷积压缩通道数(Squeeze),再通过并行使用1x1卷积和3x3卷积来抽取特征(Expand),通过延迟下采样阶段来保证精度。综合来说,SqueezeNet旨在减少参数量来加速。
通过减少MAdds来加速的轻量模型:
MobileNet V1:提出深度可分离卷积;
MobileNet V2:提出反转残差线性瓶颈块;
ShuffleNet:结合使用分组卷积和通道混洗操作;
CondenseNet:dense连接
ShiftNet:利用shift操作和逐点卷积代替了昂贵的空间卷积
从SqueezeNet开始模型的参数量就不断下降,为了进一步减少模型的实际操作数(MAdds),MobileNetV1利用了深度可分离卷积提高了计算效率,而MobileNetV2则加入了线性bottlenecks和反转残差模块构成了高效的基本模块。随后的ShuffleNet充分利用了组卷积和通道shuffle进一步提高模型效率。CondenseNet则学习保留有效的dense连接在保持精度的同时降低,ShiftNet则利用shift操作和逐点卷积代替了昂贵的空间卷积。
(1)MobileNet-v1中深度可分离卷积的理解:
将传统卷积分解为空间滤波和特征生成两个步骤,空间滤波对应较轻的3x3 depthwise conv layer,特征生成对应较重的1x1 pointwise conv layer.
(2)MobileNet-v2中反转残差线性瓶颈块的理解:
扩张(1x1 conv) -> 抽取特征(3x3 depthwise)-> 压缩(1x1 conv)
当且仅当输入输出具有相同的通道数时,才进行残余连接
在最后“压缩”完以后,没有接ReLU激活,作者认为这样会引起较大的信息损失
该结构在输入和输出处保持紧凑的表示,同时在内部扩展到更高维的特征空间,以增加非线性每通道变换的表现力。
(3)MnasNet理解:
在MobileNet-v2的基础上构建,融入SENet的思想
与SE-ResBlock相比,不同点在于SE-ResBlock的SE layer加在最后一个1x1卷积后,而MnasNet的SE layer加在depthwise卷积之后,也就是在通道数最多的feature map上做Attention。
(4)MobileNet-v3的理解:
MobileNet-v3集现有轻量模型思想于一体,主要包括:swish非线性激活Squeeze and Excitation思想为了减轻计算swish中传统sigmoid的代价,提出了hard sigmoid
2.整体来说MobileNetV3有两大创新点
(1)互补搜索技术组合:由资源受限的NAS执行模块级搜索,NetAdapt执行局部搜索。
(2)网络结构改进:将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish激活函数。
3.开源代码
感谢github上大佬们开源,开源代码整理如下:
(1)PyTorch实现1:https://github.com/xiaolai-sqlai/mobilenetv3
(2)PyTorch实现2:https://github.com/kuan-wang/pytorch-mobilenet-v3
(3)PyTorch实现3:https://github.com/leaderj1001/MobileNetV3-Pytorch
(4)Caffe实现:https://github.com/jixing0415/caffe-mobilenet-v3
(5)TensorFLow实现:https://github.com/Bisonai/mobilenetv3-tensorflow
4.细节内容
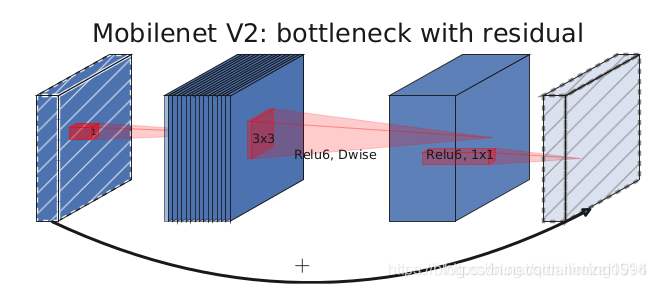
上面两张图是MobileNetV2和MobileNetV3的网络块结构。可以看出,MobileNetV3是综合了以下三种模型的思想:MobileNetV1的深度可分离卷积(depthwise separable convolutions)、MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)和MnasNet的基于squeeze and excitation结构的轻量级注意力模型。综合了以上三种结构的优点设计出了高效的MobileNetV3模块。
4.1 互补搜索技术组合
(1)资源受限的NAS(platform-aware NAS):计算和参数量受限的前提下搜索网络的各个模块,所以称之为模块级的搜索(Block-wise Search)。
(2)NetAdapt:用于对各个模块确定之后网络层的微调。
对于模型结构的探索和优化来说,网络搜索是强大的工具。研究人员首先使用了神经网络搜索功能来构建全局的网络结构,随后利用了NetAdapt算法来对每层的核数量进行优化。对于全局的网络结构搜索,研究人员使用了与Mnasnet中相同的,基于RNN的控制器和分级的搜索空间,并针对特定的硬件平台进行精度-延时平衡优化,在目标延时(~80ms)范围内进行搜索。随后利用NetAdapt方法来对每一层按照序列的方式进行调优。在尽量优化模型延时的同时保持精度,减小扩充层和每一层中瓶颈的大小。
4.2网络结构的改进
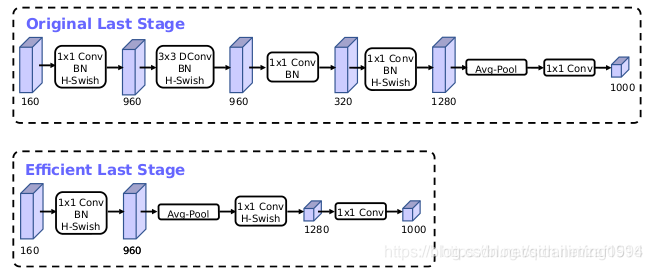
(1)改进一:
首先是最靠后部分的修改,也就是预测部分的修改。下图是MobileNet-v2的整理模型架构,可以看到,网络的最后部分首先通过1x1卷积映射到高维,然后通过GAP收集特征,最后使用1x1卷积划分到K类。所以其中起抽取特征作用的是在7x7分辨率上做1x1卷积的那一层。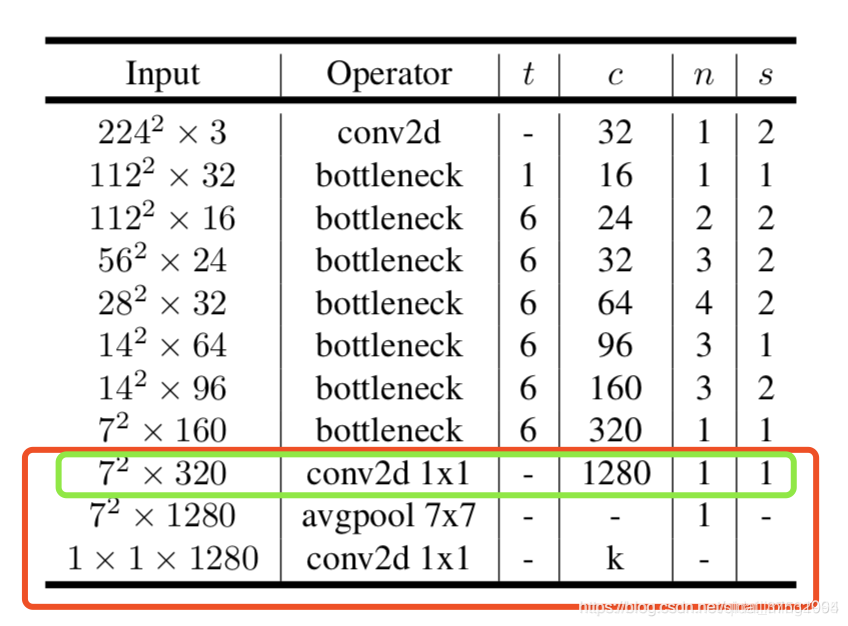
再看MobileNet-v3,上图为large,下图为small。按照刚刚的思路,这里首先将特征进行Pooling,然后再通过1x1卷积抽取用于训练最后分类器的特征,最后划分到k类。作者的解释是: This final set of features is now computed at 1x1 spatial resolution instead of 7x7 spatial resolution.

(2)改进二::
现有的移动端模型倾向于使用32个标准3 * 3卷积来构建最初的滤波器组,定性角度来看,这一个滤波器组起到的作用往往是检测边缘。
得益于hard swish的设计,经过试验可以在不损失精度的情况下降滤波器的个数从32减少到16。
这一改进可以节省3ms时间,1000万次乘加运算。
4.3激活函数
作者发现swish激活函数能够有效提高网络的精度,然而,swish的计算量太大了。作者提出h-swish(hard version of swish)如下所示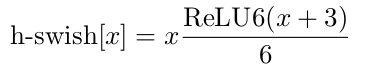
这种非线性在保持精度的情况下带了了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。这一非线性改变将模型的延时增加了15%。但它带来的网络效应对于精度和延时具有正向促进,剩下的开销可以通过融合非线性与先前层来消除。
5.效果总结:
MobileNetV3-Large在ImageNet分类上的准确度与MobileNetV2相比提高了3.2%,同时延迟降低了15%。MobileNetV3-large 用于目标检测,在COCO数据集上检测精度与MobileNetV2大致相同,但速度提高了25%。在Cityscapes语义分割任务中,新设计的模型MobileNetV3-Large LR-ASPP 与 MobileNetV2 R-ASPP分割精度近似,但快30%。