环境:py3.6
核心库:selenium(考虑到通用性,js加载的网页)、pyinstaller
颜色显示:colors.py
colors.py
用于在命令行输出文字时,带有颜色,可有可无。
# -*- coding:utf-8 -*-# # filename: prt_cmd_color.py import ctypes, sys STD_INPUT_HANDLE = -10 STD_OUTPUT_HANDLE = -11 STD_ERROR_HANDLE = -12 # 字体颜色定义 text colors FOREGROUND_BLUE = 0x09 # blue. FOREGROUND_GREEN = 0x0a # green. FOREGROUND_RED = 0x0c # red. FOREGROUND_YELLOW = 0x0e # yellow. # 背景颜色定义 background colors BACKGROUND_YELLOW = 0xe0 # yellow. # get handle std_out_handle = ctypes.windll.kernel32.GetStdHandle(STD_OUTPUT_HANDLE) def set_cmd_text_color(color, handle=std_out_handle): Bool = ctypes.windll.kernel32.SetConsoleTextAttribute(handle, color) return Bool # reset white def resetColor(): set_cmd_text_color(FOREGROUND_RED | FOREGROUND_GREEN | FOREGROUND_BLUE) # green def printGreen(mess): set_cmd_text_color(FOREGROUND_GREEN) sys.stdout.write(mess) resetColor() # red def printRed(mess): set_cmd_text_color(FOREGROUND_RED) sys.stdout.write(mess) resetColor() # yellow def printYellow(mess): set_cmd_text_color(FOREGROUND_YELLOW) sys.stdout.write(mess + ' ') resetColor() # white bkground and black text def printYellowRed(mess): set_cmd_text_color(BACKGROUND_YELLOW | FOREGROUND_RED) sys.stdout.write(mess + ' ') resetColor() if __name__ == '__main__': printGreen('printGreen:Gree Color Text') printRed('printRed:Red Color Text') printYellow('printYellow:Yellow Color Text')
spider.py
主要在于通用性的处理
# -*- coding: utf-8 -*- ## import some modules import os import time from selenium import webdriver from selenium.webdriver.chrome.options import Options from bs4 import BeautifulSoup from os import path import requests import re from urllib.parse import urlparse, urljoin from colors import * d = path.dirname(__file__) bar_length = 20 def output(List, percent, msg ,url): hashes = '#' * int(percent / len(List) * bar_length) spaces = ' ' * (bar_length - len(hashes)) loadingStr = str(int(100 * percent / len(List)))+ u'%' length = len('100%') if len(loadingStr) < length: loadingStr += ' '*(length-len(loadingStr)) sys.stdout.write(" Percent: [%s %s]" % (hashes + spaces, loadingStr )) printYellow(" [%s] %s " % ( msg, url)) sys.stdout.flush() time.sleep(2) class Spider(): '''spider class''' def __init__(self): self.url = 'https://www.cnblogs.com/cate/csharp/#p5' self.checkMsg = '' self.fileName = path.join(d, 'image/') self.fileDirName = '' self.chrome_options = Options() self.chrome_options.add_argument('--headless') self.chrome_options.add_argument('--disable-gpu') self.driver = webdriver.Chrome(chrome_options=self.chrome_options) self.topHostPostfix = ( '.com', '.la', '.io', '.co', '.info', '.net', '.org', '.me', '.mobi', '.us', '.biz', '.xxx', '.ca', '.co.jp', '.com.cn', '.net.cn', '.org.cn', '.mx', '.tv', '.ws', '.ag', '.com.ag', '.net.ag', '.org.ag', '.am', '.asia', '.at', '.be', '.com.br', '.net.br', '.bz', '.com.bz', '.net.bz', '.cc', '.com.co', '.net.co', '.nom.co', '.de', '.es', '.com.es', '.nom.es', '.org.es', '.eu', '.fm', '.fr', '.gs', '.in', '.co.in', '.firm.in', '.gen.in', '.ind.in', '.net.in', '.org.in', '.it', '.jobs', '.jp', '.ms', '.com.mx', '.nl', '.nu', '.co.nz', '.net.nz', '.org.nz', '.se', '.tc', '.tk', '.tw', '.com.tw', '.idv.tw', '.org.tw', '.hk', '.co.uk', '.me.uk', '.org.uk', '.vg', ".com.hk") def inputUrl(self): '''input url''' self.url = input('please input your target: ') print('[*] url: %s' % self.url) def check(self): '''check url''' self.checkMsg = input('Are your sure to grab this site? [Y/N/Exit] :') if self.checkMsg == 'Y': self.middle = self.url.replace('http://', '') self.middle = self.middle.replace('https://', '') self.fileDirName = path.join(d, 'image/%s' % self.middle) self.makeFile() self.parse() elif self.checkMsg == 'N': self.inputUrl() self.check() elif self.checkMsg == 'Exit': sys.exit() else: print('please input one of [Y/N/Exit]!!') self.check() def makeFile(self): '''创建文件夹函数''' if os.path.exists(self.fileName): pass else: os.makedirs(self.fileName) if os.path.exists(self.fileDirName): pass else: os.makedirs(self.fileDirName) def getCssImage(self,url): '''获取css中的image''' headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'} try: response = requests.get(url, headers = headers, timeout=500).text bgCssList = re.findall("url((.*?))", response) bgCssSrc = [] if len(bgCssList) > 0: for v in bgCssList: v = v.replace('url(', '') v = v.replace('\', "") v = v.replace(')', "") print(v) print('-----------------------------------') bgCssSrc.append(v) return bgCssSrc except: print('connection timeout!!!') def getHostName(self, url): '''获取url主域名''' regx = r'[^.]+(' + '|'.join([h.replace('.', r'.') for h in self.topHostPostfix]) + ')$' pattern = re.compile(regx, re.IGNORECASE) parts = urlparse(self.url) host = parts.netloc m = pattern.search(host) urlm = 'http://www.' + m.group() if m else host return urlm def joinUrl(self, url): '''图片url处理''' # if url[:2] == '//': # url = url.replace('//', '') # url = 'http://' + url # elif url.startswith('/'): # ## 需要处理 # regx = r'[^.]+(' + '|'.join([h.replace('.', r'.') for h in self.topHostPostfix]) + ')$' # pattern = re.compile(regx, re.IGNORECASE) # parts = urlparse(self.url) # host = parts.netloc # m = pattern.search(host) # urlm = 'http://www.' + m.group() if m else host # url = urlm + url # try: # ## 处理字符串 获取 www http https # if url[:2] == '//': # url = url.replace('//', '') # url = 'http://' + url # elif url.startswith('/'): # ## 需要处理 # regx = r'[^.]+(' + '|'.join([h.replace('.', r'.') for h in self.topHostPostfix]) + ')$' # pattern = re.compile(regx, re.IGNORECASE) # parts = urlparse(self.url) # host = parts.netloc # m = pattern.search(host) # urlm = 'http://www/' + m.group() if m else host # url = urlm + url # else: # try: # url = url.split('www', 1)[1] # url = u'http://www' + url # except: # try: # url = url.split('http', 1)[1] # url = u'http' + url # except: # pass # except: # pass ## ex1 '//example.png' ## ex2 'http://' if url.startswith('http'): return url else: return urljoin(self.url, url) def download(self, key, url): if key == 0: pass else: print('') url = self.joinUrl(url) try: imgType = os.path.split(url)[1] imgType = imgType.split('.',1)[1] imgType = imgType.split('?',1)[0] except: msg = u' Error ' return msg fileName = int(time.time()) path = self.fileDirName+ u'/'+str(fileName) + u'.' + imgType try: headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'} try: response = requests.get(url, headers=headers, timeout=500).content except: msg = u' Error ' return msg f = open(path, 'wb+') try: f.write(response.encode('utf-8')) except: f.write(response) f.close() except Exception as e: msg = u' Error ' return msg return u'Success' def parse(self): '''parse html''' self.driver.get(self.url) time.sleep(3) html_content = self.driver.page_source bs = BeautifulSoup(html_content, "html.parser") ## 先获取所有的图片 imgList = bs.find_all('img') srcList = [] if len(imgList) > 0: for v in imgList: srcList.append(v['src']) print(v['src']) print('-----------------------------------') srcList = list(set(srcList)) print('[*] Find %s image in page',len(srcList)) ## 获取当前页面style里面的背景图 bgStyleList = re.findall("url((.*?))", html_content) bgSrc = [] if len(bgStyleList) > 0: for v in bgStyleList: v = v.replace('url(', '') v = v.replace('\',"") v = v.replace(')', "") print(v) print('-----------------------------------') bgSrc.append(v) bgSrc = list(set(bgSrc)) print('[*] Find %s image in Page style', len(bgSrc)) ## 获取所有的背景图 ## 获取所有的css文件 cssList = re.findall('<link rel="stylesheet" href="(.*?)"',html_content) cssImageUrls = [] if len(cssList) > 0: cssImageUrl = [] for url in cssList: cssImageUrl += self.getCssImage(url) cssImageUrls = cssImageUrl cssImageUrls = list(set(cssImageUrls)) print('[*] Find %s image in Page css', len(cssImageUrls)) ## 开始获取图片https://www.cnblogs.com/shuangzikun/ ## 开始下载标签的图片 print('---------------------------------------------') if len(srcList) > 0: print('Start Load Image -- %s' % len(srcList)) for percent,url in enumerate(srcList): percent += 1 msg = self.download(percent, url) output(srcList, percent, msg ,url) if len(bgSrc) >0: print(' Start Load Image In Style -- %s' % len(bgSrc)) for percent, url in enumerate(bgSrc): percent += 1 msg = self.download(percent, url) output(srcList, percent, msg, url) if len(cssImageUrls) > 0: print(' Start Load Image In Css -- %s' % len(cssImageUrls)) for percent, url in enumerate(cssImageUrls): percent += 1 msg = self.download(percent, url) output(srcList, percent, msg, url) print(' End----------------------------------Exit') if __name__ == '__main__': print(''' ____ __ __ __ __ _______ _______ /__ \ \_\/_/ / / / /____ / ___ / / ___ / / /_/ / \__/ / /___ / /__ / / / / / / / / / / ____/ / / / /___/ / / / / / /__/ / / / / / /_/ /_/ /_/___/ /_/ /_/ \_____/ /_/ /_/ version 3.6''') descriptionL = ['T', 'h', 'i', 's', ' ', 'i', 's' , ' ', 'a', ' ', 's', 'p', 'i', 'd', 'e', 'r', ' ','p', 'r', 'o', 'c', 'e', 'd', 'u', 'r', 'e', ' ', '-', '-', '-',' IMGSPIDER', ' '] for j in range(len(descriptionL)): sys.stdout.write(descriptionL[j]) sys.stdout.flush() time.sleep(0.1) urlL = ['[First Step]', ' input ', 'a', ' url ' , 'as ', 'your ', 'target ~ '] for j in range(len(urlL)): sys.stdout.write(urlL[j]) sys.stdout.flush() time.sleep(0.2) pathL = ['[Second Step]', ' check ', 'this ', 'url ~ '] for j in range(len(pathL)): sys.stdout.write(pathL[j]) sys.stdout.flush() time.sleep(0.2) ## new spider MySpider = Spider() ## input url path MySpider.inputUrl() # ## checkMsg MySpider.check()
运行效果
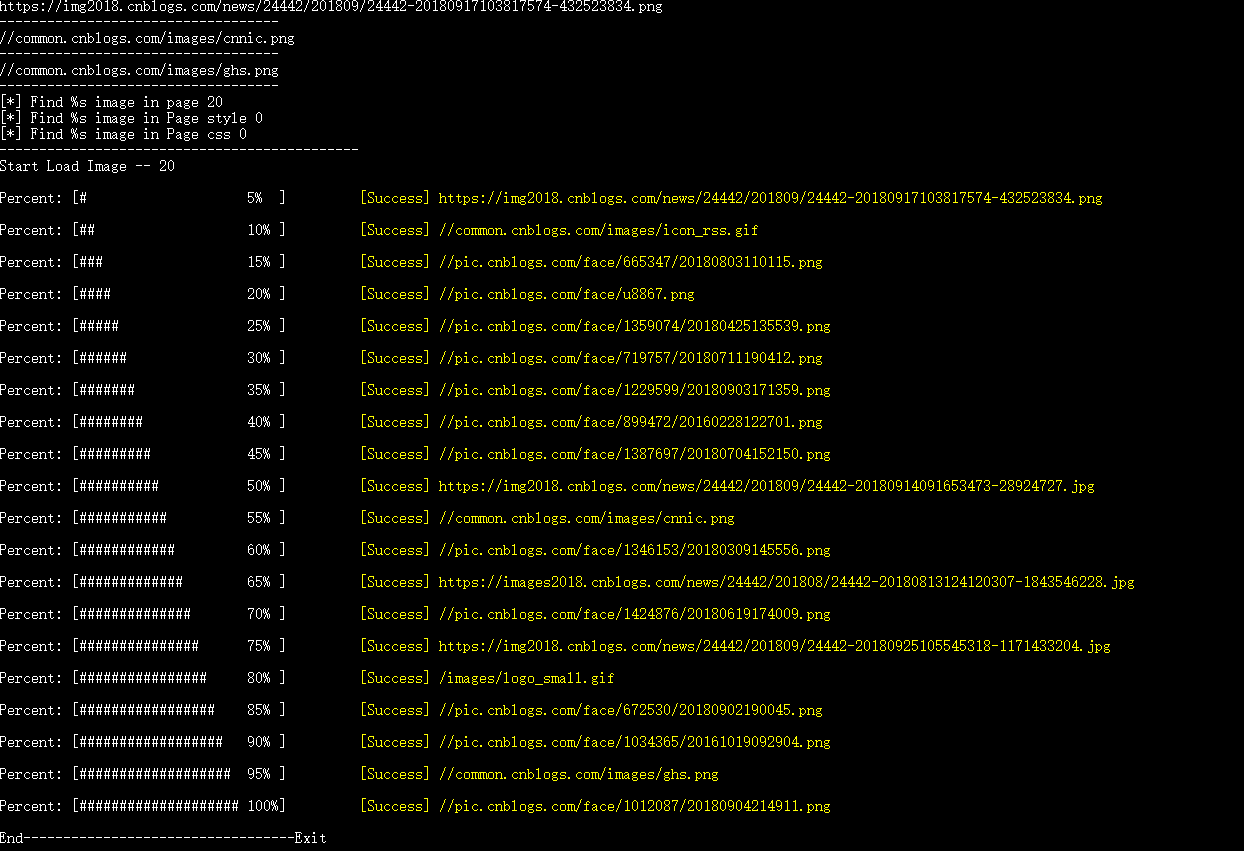
打包
使用到其它扩展
pyinstaller -f spider.py 打包成单一文件。
由于要在其它电脑上使用,需要修改下谷歌驱动的位置,把谷歌驱动放在spider.exe的同目录下。
try: self.chrome_options.add_argument(r"user-data-dir = %s" % path.join('ChromeApplication')) self.driver = webdriver.Chrome(path.join(d,'chromedriver.exe'),chrome_options=self.chrome_options) except Exception as e: print(e)
点击spider.exe,初始化没有报错即ok了。