为了方便的学习站内搜索,下面我来演示一个MVC项目。
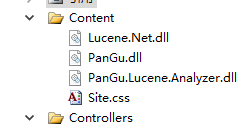
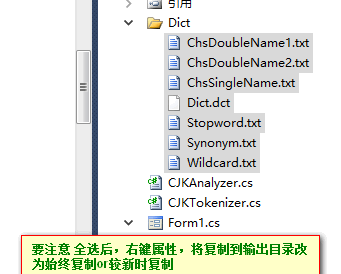
1.首先在项目中【添加引入】三个程序集和【Dict】文件夹,并新建一个【分词内容存放目录】
Lucene.Net.dll、PanGu.dll、PanGu.Lucene.Analyzer.dll
链接:http://pan.baidu.com/s/1eS6W8s6 密码:ds8b
链接:链接:http://pan.baidu.com/s/1geYyDnt 密码:8rq4
2.建立Search控制器,并转到Index界面写入如下内容:
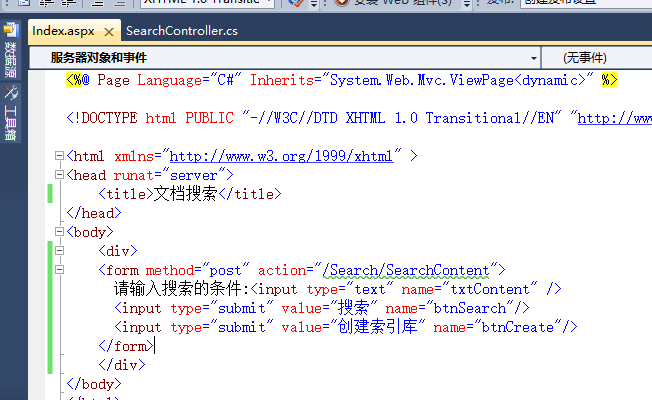
PS:VS有问题,波浪号由他去吧,,,
----------后台语句-------
->创建索引语句
public ActionResult SearchContent()
{
//首先根据name区分是点击的哪个按钮
if (!String.IsNullOrEmpty(Request.Form["btnSearch"]))//执行搜索
{
}
else//创建索引
{
CreateSearchIndex();//调用创建索引语句
}
return Content("OK");
}
//创建索引语句
public void CreateSearchIndex()
{
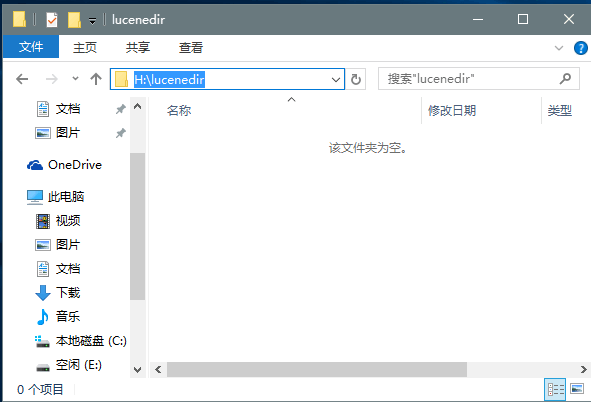
string indexPath = @"H:lucenedir";//注意和磁盘上文件夹的大小写一致,否则会报错。将创建的分词内容放在该目录下
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory());
bool isUpdate = IndexReader.IndexExists(directory);//判断索引库是否存在
if (isUpdate)
{
//如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁
//Lucene.Net在写索引库之前会自动加锁,在close的时候会自动解锁
//不能多线程执行,只能处理意外被永远锁定的情况
if (IndexWriter.IsLocked(directory))
{
IndexWriter.Unlock(directory);//un-否定。强制解锁
}
}
IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, Lucene.Net.Index.IndexWriter.MaxFieldLength.UNLIMITED);
//-------调用业务层拿到所有的数据
Search.BLL.UserGUIDBll bll = new Search.BLL.UserGUIDBll();
List<Search.Model.UserInfo> list=bll.SelectAll();
foreach (UserInfo item in list)
{
Document document = new Document();//一条Document相当于一条记录
document.Add(new Field("id",item.UserId.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));//每个Document可以有自己的属性(字段),所有字段名都是自定义的,值都是string类型
//想给用户展示什么就往词库里面添加什么
document.Add(new Field("title",item.UserName, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS));
document.Add(new Field("content", item.UserContent, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS));
writer.AddDocument(document);
}
writer.Close();//会自动解锁
directory.Close();//不要忘了Close,否则索引结果搜不到
}
执行创建索引语句,将看到分词内容文件夹里面将多一些东西,这些就是用来以后检索的
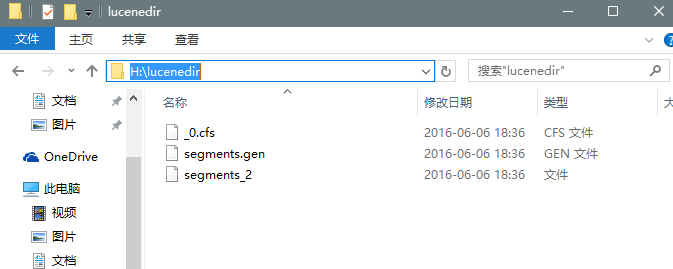
->执行索引语句
public ActionResult SearchContent()
{
//首先根据name区分是点击的哪个按钮
if (!String.IsNullOrEmpty(Request.Form["btnSearch"]))//执行搜索
{
List<ViewSearchContentModel> recList=SearchBookContent();
ViewData["searchList"] = recList;
return View("Index");
}
else//创建索引
{
CreateSearchIndex();//调用创建索引语句
}
return Content("OK");
}
SearchBookContent类:
//执行索引语句
public List<ViewSearchContentModel> SearchBookContent()
{
string indexPath = @"H:lucenedir"; //lucene存数据的路径
string searchTxt = Request.Form["txtContent"];//获取用户输入的内容
//将用户输入的内容进行分词
List<string> kw=SearchController.GetPanGuWord(searchTxt);
//string kw = "没有";
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory());
IndexReader reader = IndexReader.Open(directory, true);
IndexSearcher searcher = new IndexSearcher(reader);
PhraseQuery query = new PhraseQuery();//查询条件
//query.Add(new Term("msg", kw));//where contains("msg",kw) 这里的msg对应上面的msg
foreach (string word in kw)//先用空格,让用户去分词,空格分隔的就是词“计算机 专业”
{
query.Add(new Term("content", word));//contains("msg",word)
}
query.SetSlop(100);//两个词的距离大于100(经验值)就不放入搜索结果,因为距离太远相关度就不高了
TopScoreDocCollector collector = TopScoreDocCollector.create(1000, true);//盛放查询结果的容器
searcher.Search(query, null, collector);//使用query这个查询条件进行搜索,搜索结果放入collector
//collector.GetTotalHits()总的结果条数
ScoreDoc[] docs = collector.TopDocs(0, collector.GetTotalHits()).scoreDocs;//从查询结果中取出第m条到第n条的数据
List<ViewSearchContentModel> list = new List<ViewSearchContentModel>();
for (int i = 0; i < docs.Length; i++)//遍历查询结果
{
ViewSearchContentModel viewModel = new ViewSearchContentModel();
int docId = docs[i].doc;//拿到文档的id。因为Document可能非常占内存(DataSet和DataReader的区别)
//所以查询结果中只有id,具体内容需要二次查询
Document doc = searcher.Doc(docId);//根据id查询内容。放进去的是Document,查出来的还是Document
viewModel.Id = doc.Get("id");
viewModel.Title = doc.Get("title");
viewModel.Content = doc.Get("content");
list.Add(viewModel);
}
return list;
}
class SearchResult
{
public int Id { get; set; }
public string Msg { get; set; }
}
//利用盘古分词对用户输入的内容进行分词
public static List<string> GetPanGuWord(string str)
{
List<string> list=new List<string>();
Analyzer analyzer = new PanGuAnalyzer();
TokenStream tokenStream = analyzer.TokenStream("", new StringReader(str));
Lucene.Net.Analysis.Token token = null;
while ((token = tokenStream.Next()) != null)
{
list.Add(token.TermText());
// Console.WriteLine(token.TermText());
}
return list;
}
ViewSearchContentModel类:(这个类定义在MVC中的Model里面的,视图要展示啥数据,这里就定义什么)

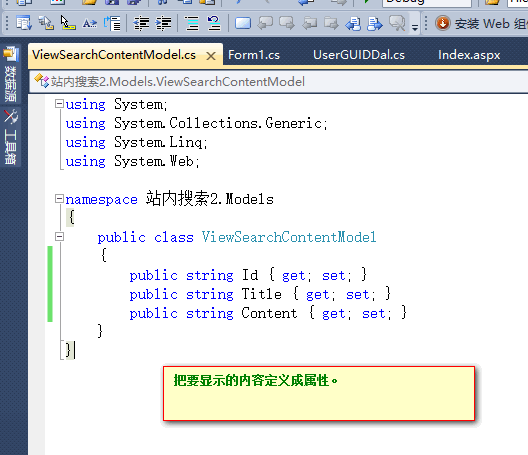
->前台修改如下:
<%@ Page Language="C#" Inherits="System.Web.Mvc.ViewPage<dynamic>" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" >
<head runat="server">
<title>文档搜索</title>
</head>
<body>
<div>
<form method="post" action="/Search/SearchContent">
请输入搜索的条件:<input type="text" name="txtContent" />
<input type="submit" value="搜索" name="btnSearch"/>
<input type="submit" value="创建索引库" name="btnCreate"/>
</form>
<table>
<tbody>
<%if (ViewData["searchList"] != null)
{
foreach (站内搜索2.Models.ViewSearchContentModel item in (List<站内搜索2.Models.ViewSearchContentModel>)ViewData["searchList"])
{%>
<tr><td><%=item.Id%></td><td><%=item.Title%></td><td><%=item.Content%></td></tr>
<% }
}
%>
</tbody>
</table>
</div>
</body>
</html>
-----这时基本搜索功能就实现了,接下来实现高亮显示-------
1.添加或引入PanGu.HighLight和PanGu.HighLight.pdb
链接:http://pan.baidu.com/s/1eS6W8s6 密码:ds8b
创建一个Common文件夹,并在里面建立一个WebCommon类
代码如下:(这个类中参数keyworkds就是要高亮显示的值,content就是返回的内容,这样在搜索结果中调用这个类就能实现高亮)
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using PanGu.HighLight;
using PanGu;
namespace 站内搜索2.Common
{
public class WebCommon
{
public static string CreateHighLight(string keywords, string content)
{
SimpleHTMLFormatter simpleHTMLFormatter = new PanGu.HighLight.SimpleHTMLFormatter("<font style='color:red'>", "</font>");
Highlighter highlighter = new PanGu.HighLight.Highlighter(simpleHTMLFormatter, new Segment());
//设置每个摘要的字符数
highlighter.FragmentSize = 150;
return highlighter.GetBestFragment(keywords, content);
}
}
}
在搜索结果中调用这个类:
// viewModel.Content = doc.Get("content");
viewModel.Content = Common.WebCommon.CreateHighLight(Request["txtContent"], doc.Get("content"));
写到这先放张效果图吧:

注意:有的时候我们使用razor引擎,会发生自动编码问题,为了正常显示,我们可以这样写:@MVCHtmlString.Create(item.Title)
JS侧栏分享代码:
<!-- JiaThis Button BEGIN --> <script type="text/javascript" src="http://v3.jiathis.com/code/jiathis_r.js?move=0&btn=r4.gif" charset="utf-8"></script> <!-- JiaThis Button END -->
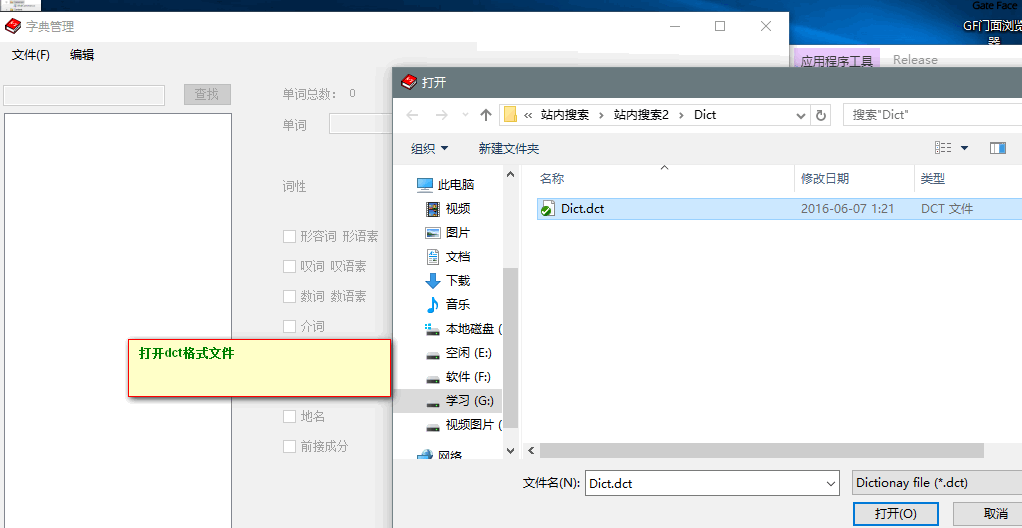
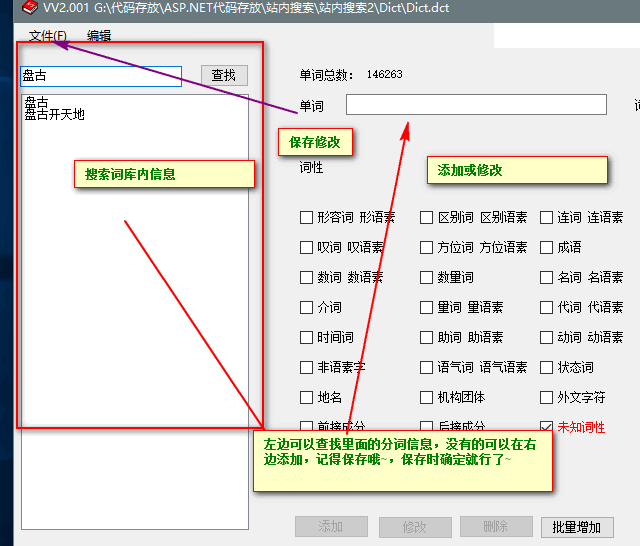
最后再补充一下分词工具使用方式:
站内搜索源码下载:链接:http://pan.baidu.com/s/1o8IlAZK 密码:0gwf