这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍
Scrapy目前已经可以很好的在python3上运行
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、执行系统层次操作的代码(如等待系统队列),Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。
Scrapy data flow(流程图)
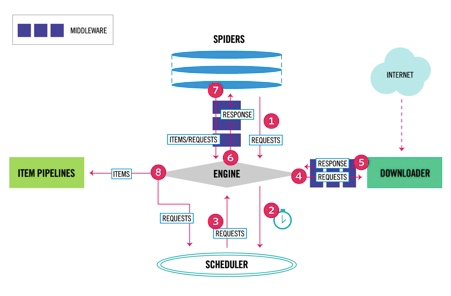
Scrapy数据流是由执行的核心引擎(engine)控制,流程是这样的:
1、爬虫引擎ENGINE获得初始请求开始抓取。
2、爬虫引擎ENGINE开始请求调度程序SCHEDULER,并准备对下一次的请求进行抓取。
3、爬虫调度器返回下一个请求给爬虫引擎。
4、引擎请求发送到下载器DOWNLOADER,通过下载中间件下载网络数据。
5、一旦下载器完成页面下载,将下载结果返回给爬虫引擎ENGINE。
6、爬虫引擎ENGINE将下载器DOWNLOADER的响应通过中间件MIDDLEWARES返回给爬虫SPIDERS进行处理。
7、爬虫SPIDERS处理响应,并通过中间件MIDDLEWARES返回处理后的items,以及新的请求给引擎。
8、引擎发送处理后的items到项目管道,然后把处理结果返回给调度器SCHEDULER,调度器计划处理下一个请求抓取。
9、重复该过程(继续步骤1),直到爬取完所有的url请求。
各个组件介绍
爬虫引擎(ENGINE)
爬虫引擎负责控制各个组件之间的数据流,当某些操作触发事件后都是通过engine来处理。
调度器(SCHEDULER)
调度接收来engine的请求并将请求放入队列中,并通过事件返回给engine。
下载器(DOWNLOADER)
通过engine请求下载网络数据并将结果响应给engine。
Spider
Spider发出请求,并处理engine返回给它下载器响应数据,以items和规则内的数据请求(urls)返回给engine。
管道项目(item pipeline)
负责处理engine返回spider解析后的数据,并且将数据持久化,例如将数据存入数据库或者文件。
下载中间件
下载中间件是engine和下载器交互组件,以钩子(插件)的形式存在,可以代替接收请求、处理数据的下载以及将结果响应给engine。
spider中间件
spider中间件是engine和spider之间的交互组件,以钩子(插件)的形式存在,可以代替处理response以及返回给engine items及新的请求集。
如何创建Scrapy项目
创建Scrapy项目
创建scrapy项目的命令是scrapy startproject 项目名,创建一个爬虫
进入到项目目录scrapy genspider 爬虫名字 爬虫的域名,例子如下:
zhaofandeMBP:python_project zhaofan$ scrapy startproject test1
New Scrapy project 'test1', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in:
/Users/zhaofan/Documents/python_project/test1
You can start your first spider with:
cd test1
scrapy genspider example example.com
zhaofandeMBP:python_project zhaofan$
zhaofandeMBP:test1 zhaofan$ scrapy genspider shSpider hshfy.sh.cn
Created spider 'shSpider' using template 'basic' in module:
test1.spiders.shSpider
scrapy项目结构
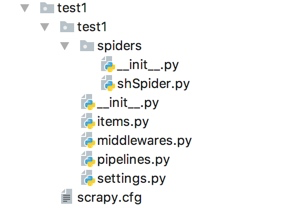
items.py 负责数据模型的建立,类似于实体类。
middlewares.py 自己定义的中间件。
pipelines.py 负责对spider返回数据的处理。
settings.py 负责对整个爬虫的配置。
spiders目录 负责存放继承自scrapy的爬虫类。
scrapy.cfg scrapy基础配置