梯度下降的向量化
[Lambda J = egin{bmatrix}
frac{partial J}{partial heta _0} \
frac{partial J}{partial heta _1} \
frac{partial J}{partial heta _2} \
... \
frac{partial J}{partial heta _n}
end{bmatrix} = frac{2}{m}egin{bmatrix}
sum(X^{(i)}_b heta - y^{(i)}) \
sum(X^{(i)}_b heta - y^{(i)}) cdot X_1^{(i)}\
sum(X^{(i)}_b heta - y^{(i)}) cdot X_2^{(i)}\
...\
sum(X^{(i)}_b heta - y^{(i)}) cdot X_n^{(i)}
end{bmatrix}]
之前求梯度的过程是使用for循环对每一项的( heta) 求偏导数, 对上面的式子,进行向量化
[Lambda J = egin{bmatrix}
frac{partial J}{partial heta _0} \
frac{partial J}{partial heta _1} \
frac{partial J}{partial heta _2} \
... \
frac{partial J}{partial heta _n}
end{bmatrix} = frac{2}{m}egin{bmatrix}
sum(X^{(i)}_b heta - y^{(i)}) cdot X_0^{(i)}\
sum(X^{(i)}_b heta - y^{(i)}) cdot X_1^{(i)}\
sum(X^{(i)}_b heta - y^{(i)}) cdot X_2^{(i)}\
...\
sum(X^{(i)}_b heta - y^{(i)}) cdot X_n^{(i)}
end{bmatrix} = frac{2}{m}(X_b heta -y)^Tcdot X_b ]
将式子转换为列向量:
[Lambda J = frac{2}{m}(X_b heta -y)^Tcdot X_b = frac{2}{m} X_b^T cdot (X_b heta -y)
]
优化代码:
def dJ(theta,X_b,y): #求导
#返回的导数矩阵
#res = numpy.empty(len(theta))
#res[0] = numpy.sum(X_b.dot(theta)-y)
#for i in range(1,len(theta)):
#res[i] = ((X_b.dot(theta)-y).dot(X_b[:,i]))
#return res*2/len(X_b)
return X_b.T.dot(X_b.dot(theta)-y)*2/len(X_b)
使用梯度下降法预测波士顿房价:
import numpy
import matplotlib.pyplot as plt
from sklearn import datasets
from mylib.LineRegression import LineRegression
from mylib.model_selection import train_test_split
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y<50]
y = y[y<50]
X_train,X_test,y_train,y_test = train_test_split(X,y,seed=666)
reg = LineRegression()
%time reg.fit_gd(X_train,y_train)
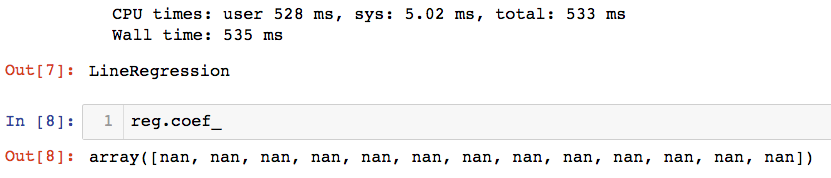
由此看出是梯度下降过程不收敛,先尝试减小学习步长 $eta $ 并增大学习次数n_iters
%time reg.fit_gd(X_train,y_train,eta=0.000001,n_iters=1e6)
reg.score(X_test,y_test)
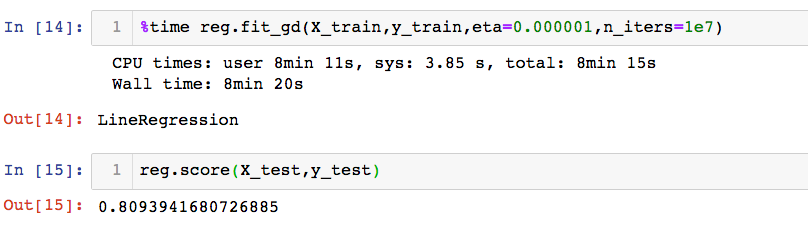
训练时间长达8分钟!!!
数据标准化
由上可知,因为真实数据集各个特征的规模不一样,学习率取较大值时,梯度下降过程可能不收敛,学习率取较小值时,学习次数多,导致学习时间很慢,所以在使用梯度下降法时,将数据归一化
from sklearn.preprocessing import StandardScaler
Sd = StandardScaler()
Sd.fit(X_train)
X_train_stand = Sd.transform(X_train)
X_test_stand = Sd.transform(X_test)
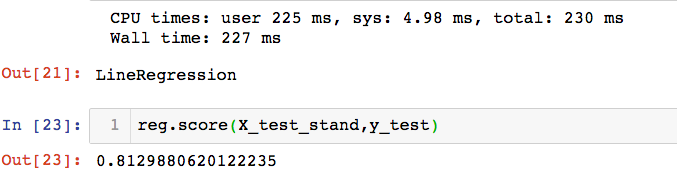
%time reg.fit_gd(X_train_stand,y_train)
梯度下降法的优势
虚构一个有1000个样本数,每个样本有5000个特征的数据集
import numpy
m=1000 #样本数
n=5000 #特征值
big_x = numpy.random.normal(size=(m,n))
true_theta = numpy.random.uniform(0.0, 100.0,size=n+1)
big_y = big_x.dot(true_theta[1:]) + true_theta[:1] + numpy.random.normal(0.0,10.0,size=m)
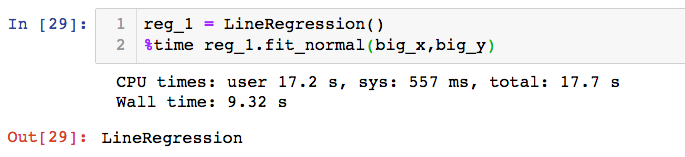
用线性回归算法训练:
用梯度下降法训练:
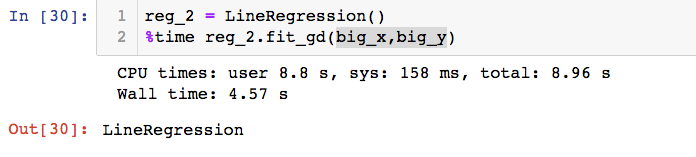
由上可以看出,梯度下降所需的时间要少于线性回归法,这是因为正规方程解处理的是m*n规模的矩阵之间的大量乘法运算,当数据规模比较大的时候,计算耗时是更高的。