1.前言:
我们提到程序中的集合的时候,往往脑海中会浮现出, 如ArrayList和LinkedList以及和HashMap。当然在提到ArrayList和LinkedList的时候,我们大多数的人都知道一点:ArrayList查询速度快,操作速度慢。LinkedList查询速度慢,但是操作速度快。但是why ? 为什么会是这样的现象? 那么接下我从数据结构角度带大家一起去认识下这个问题。
2.数据结构 --- 线性表
数据结构是计算机存储、组织数据的方式。
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。
上述概念得出:数据结构 = 数据存储 + 数据集合。
线性表: 线性表是一个线性结构,它是一个含有n≥0个结点的有限序列,对于其中的结点,有且仅有一个开始结点没有前驱但有一个后继结点,有且仅有一个终端结点没有后继但有一个前驱结点,其它的结点都有且仅有一个前驱和一个后继结点。
在数学的角度 线程表A = { A0, A1, A2, ….. , An-1, An, An+1 } ,那么我们称之为 An-1 是 An 的前驱元 ,An+1 是后继元。
3.存储方式
我们简单的认识了线性表的结构 ,那么根据计算机存储不同, 我们将线性表分类成为:线性存储和链式存储。

3.1 线性存储
线性表中线性储存表示我们数据结构在中的元素在存储元素的时候是按照顺序在计算机内存中存储。 典型代表:ArrayList
线性存储的设计数据结构需要包含以下:
I. 起始位置
II. 数组
III. 表空间元素存储位置
从上面我们可以看的出来,我们在设计线程表的时候是通过数组的形式来维护的数据结构的关系,不需要我们自行设计逻辑关系的维护。
数组在维护逻辑关系上来说,由于数组本身包含记录着元素索引。索引搜索起来的速度较快。
缺点:
由于是由数组维护数据结构,会产生一些问题?
第一. 在实现元素的添加的时候,涉及的一个问题就是数组的自动扩容策略。
顺序存储的线性链表在选择自动扩容的测试就是数组的拷贝。
参考ArrayList;源码分析 元素添加方法

其中自动扩容选择了Arrays.copyOf(elementData, newCapacity) 数组的拷贝实现。
那么数组在拷贝的时候,就是涉及到 数据结构中的元素的大量的拷贝迁移
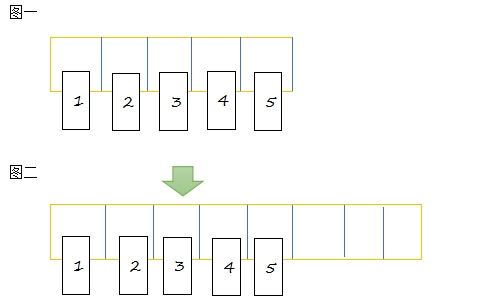
从图一到图二的过度,是我们线性表的自动扩容的过程,涉及到的步骤有数组的新建和元素的拷贝,这样就额外的增加了性能开销。
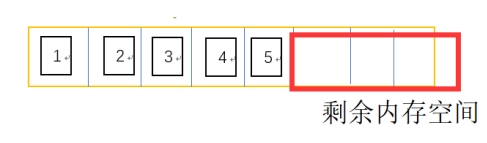
第二. 空间碎片问题
我们在使用数组开辟内存空间, 但是当我们并没有使用完数组的开辟的空间时候,那么剩余未被使用的空间就会被一直占用不能被释放出来,造成了空间的浪费,这称之为空间碎片
3.2 链式存储
线性表中链式存储存表示我们数据结构在中的元素在存储元素的时候是随机存放在计算机内存中可用的区域存储。这样可以更好的利用内存空间 。典型代表LinkedList
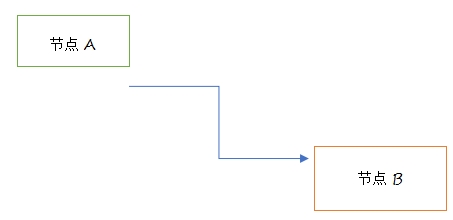
链式存储的线性表结构:设计时不使用数组来维护元素的逻辑关系,需要我们设计节点来描述数据结构中的元素关系。
节点之间需要我们去维护 “ 邻居关系”, 使用任意一组存储单元存储元素,线性表之间的线性逻辑关系是通过这组存储单元中的指针域去指向下一组存储单元,下一组储存单元可以放在任意位置。
参考LinkedList源码:

那么通过上面的数据结构我们可以看出,链式存储的线性表的逻辑关系是通过指针域存储逻辑关系,所以内存上的分布是逻辑上的关联,而物理上是分离的。
这样设计的好处在于,提升了内存的使用效率,避免了空间碎片问题。逻辑关系可以自行维护。那么在实现添加或者删除逻辑操作会更加高效。
今天主要带领大家从数据结构的视角认识我们的简单表结构。 学会了吗? 不一样的角度认识我们的老朋友 ArrayList和LinkedList。接下来还有更多java后端相关知识奉上,请多多关注上海尚学堂JAVA培训,期待下次见面。