集群是Redis的分布式方案,通过分片来进行数据共享,并提供复制和故障转移功能。
一、节点node
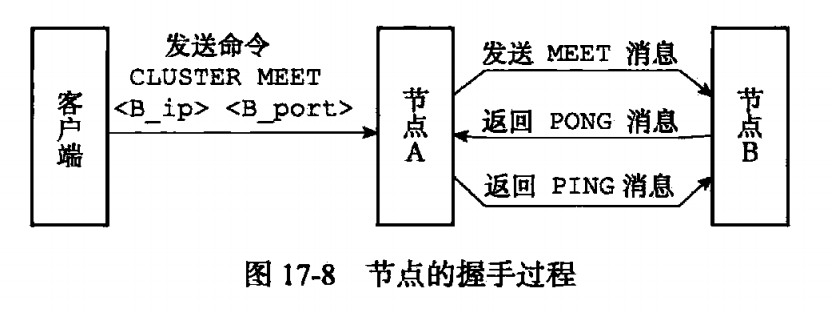
集群模式下的Redis服务器叫节点,一开始各个节点相互独立,连起来后叫集群。通过向某个节点发送命令【cluster meet <ip> <port>】,节点和【ip+port】服务器握手成功后就将其添加到所在的集群中。
启动节点:Redis服务器启动时根据cluster-enabled配置选择开启后作为普通模式还是集群模式,集群模式会有特定的数据结构和消息传递。
二、集群数据结构


struct clusterNode{ mstime_t ctime;//创建节点的时间 char name[40];//节点名字,40个十六进制符 int flags;//各种标识,主从节点、上线下线 unit64_t configEpoch;//配置纪元,用于故障转移 char ip[REDIS_IP_STR_LEN];//ip地址 int port;//端口 clusterLink* link;//保存连接节点所需的有关信息 //... };
clusterNode表示一个节点的各种基本信息,包括创建时间、地址、端口、配置纪元、名字、所连的节点等信息,属性【clusterLink* link】表示所连的节点。
typedef struct clusterLink{ mstime_t ctime;//创建连接的时间 int fd;//TCP套接字描述符 sds sndbuf;//输出缓冲区,保存要发给其他节点的信息 sds rcvbuf;//输入缓冲区,保存从其他节点接收到的信息 struct clusterNode* node;//连接关联的节点,没有则设空 //... }clusterLink;
clusterLink保存了连接节点所需的有关信息,其中缓冲区是给节点用的,而不是客户端。
typedef struct clusterState{ clusterNode* myself;//指向当前节点的指针 unit64_t currentEpoch;//配置纪元 int state;//集群状态 int size;//集群中至少处理一个槽的节点数量 dict* nodes;//集群节点名单,key为节点名,val为clusterNode结构 //... }clusterState;
clusterState是每个节点都会有的结构,记录的是集群信息,nodes字典包含了全部的节点。
握手过程:B发命令给A,A在clusterState的nodes字典里建立一个clusterNode保存B的节点信息,然后A返回命令给B,B做同样的事。B发pong命令,A收到回复ping命令。握手完成。随后A把B的信息发给及群里其他节点,纷纷握手。
三、槽
Redis集群通过分片来保存键值对,整个数据库被分为16384个槽(slot),每个节点处理0-16384个槽,全部槽都有节点处理时集群才处于上线状态。
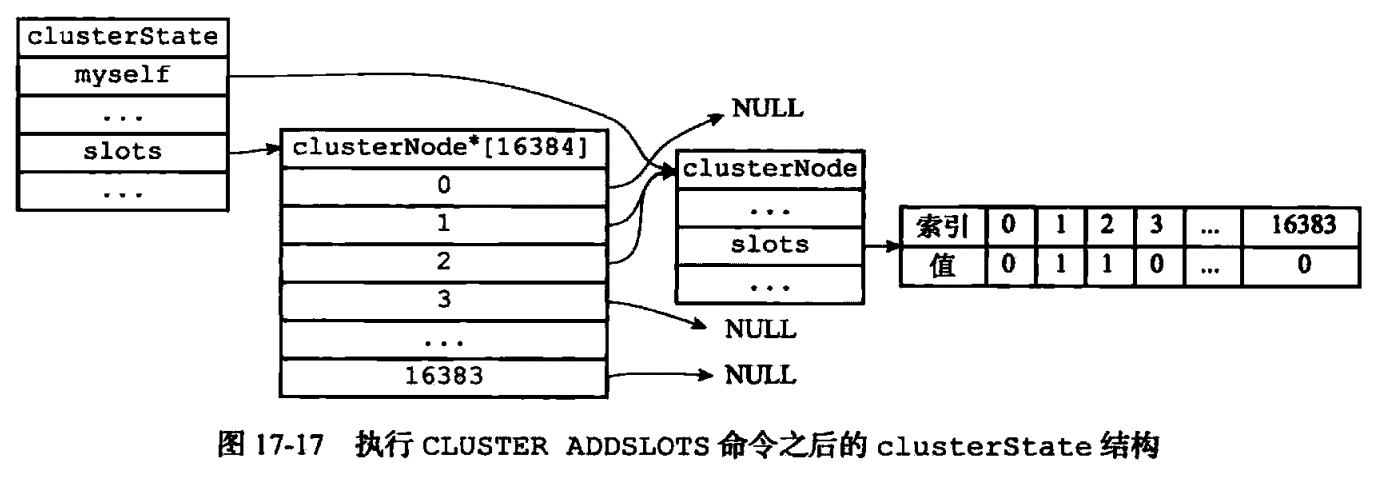
存储节点信息的clusterNode有属性记录节点负责处理哪些槽。
unsigned char slots[16384/8];//二进制位数组,1表示处理,0表示不处理 int numslots;//本节点负责的槽点数量

节点负责处理哪些槽的信息会群发给其他节点,每个节点都知道全部槽分别由谁负责处理,信息存在clusterState里。
clusterNode* slots[16384];//要么指向NULL,要么指向节点
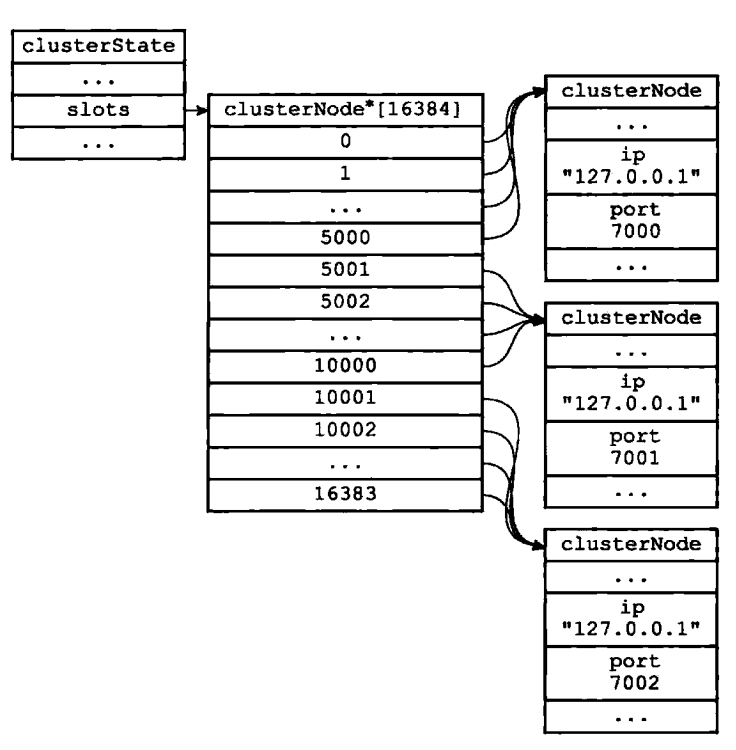
中间的数组提供索引查找作用,快速定位到节点,设置和查找时间复杂度都是O(1),若没有则需要暴力。
槽指派:通过命令【cluster addslots <slot> [slot ...]】,如果指派的槽有一个被处理了则返回错误,否则就改一下clusterNode的slots数组,改一下clusterState的slots数组指向。再群发。
四、在集群中执行命令
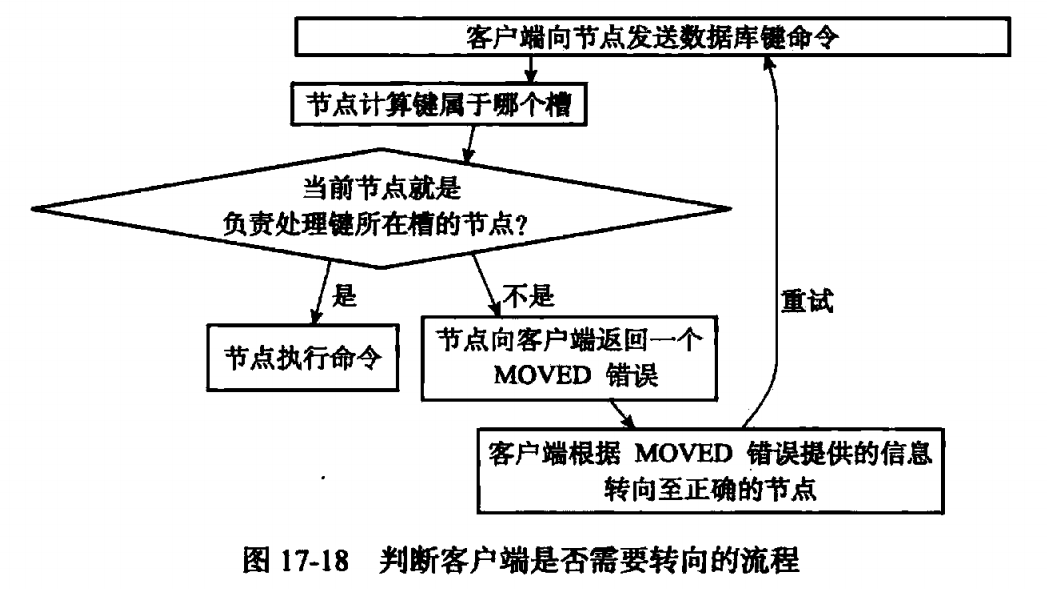
1.计算键属于哪个槽 = CRC16(key)&16383,CRC16(key)是计算key的CRC-16校验和。
2.检查是否为自己负责的槽,判断clusterState.slots[i]==clusterState.myself,不等于则返回MOVED命令,蕴含了clusterState.slots[i]指向的节点。
3.MOVED错误【moved <slot> <ip>:<port>】,若客户端未连上目标节点,则先连再发。集群模式下MOVED错误不会打印出来,单纯是告诉客户端去找其他节点,但是单机模式则会被打印出来,因为不会自动转向。MOVED错误的解决措施是永久的,权限已经改变了,客户端以后直接去找新的节点。
4.节点只能用0号数据库,单机Redis则可以随便用,过期处理方式则相同。集群状态clusterState结构中还有slots_to_keys跳跃表保存槽与键之间的关系,跳跃表的分值(score)对应键的槽号,有序,方便批量操作。
5.重新分片,无需下线。

6.ASK错误是重新分片过程中遇到客户端与键相关的命令,在源节点找不键则会去目标节点找,类似MOVED错误,被隐藏。ASK错误是一次性的,还没迁移完成,下一次还是找源节点,找不到再通过ASK错误去找目标节点。具体实现略过。
五、集群里的主从复制与故障转移
和普通的主从复制差不多。一开始各个节点定时相互发送消息以检测故障,谁没及时回复就被标记为疑似下线状态,然后告知其他节点,半数以上有处理槽的节点认为疑似下线就可以标记为已下线。从节点发现自己的主节点已下线时,先选新的主节点,规则与选领头羊Sentinel一样。旧的主节点上线后变从节点。
六、消息
meet消息:A接到【cluster meet】时,向B发送【meet】,请求B加到A所在的集群。
ping消息:每个节点默认1s随机选5个节点并挑最久没发过ping消息的节点发送ping消息,检测对方是否在线。
pong消息:对meet和ping消息的回应 或 群发状态确认。
fail消息:主节点A断定主节点B已下线时,群发告知。
publish消息:当节点收到,会执行并群发,后续接收者也如此。
消息 = 消息头header + 消息正文data
参考&引用
《redis设计与实现》