本文译自《Deep learning for understanding faces: Machines may be just as good, or better, than humans》。为了方便,文中论文索引位置保持不变,方便直接去原文中找参考文献。
近些年深度卷积神经网络的发展将各种目标检测和识别问题大大的向前推进了不少。这同时也得益于大量的标注数据集和GPU的使用,这些方面的发展使得在无限制的图片和视频中理解人脸,自动执行诸如人脸检测,姿态估计,关键点定位和人脸识别成为了可能。本文中,主要介绍人脸识别上应用的一些深度学习方法。讨论了一个自动人脸识别系统中的各个不同模块以及深度学习在其中扮演的角色。然后讨论了下在人脸识别上深度卷积神经网络尚未解决的一些问题。
1.我们能从人脸上学到什么?
人脸分析是CV中一个有挑战的事情,也一直被研究了20多年[1]。其目标在于从人脸上提取尽可能多的信息,如位置,姿态,性别,ID,年龄,表情等等。这些技术可以应用在如视频监控,手机的主动认证,支付验证等等。
本文主要介绍了近些年基于深度学习的自动人脸验证和识别系统。其中主要包含了三个模块:
- 人脸检测,用来在图像或者视频中进行人脸的定位。对于一个足够鲁棒的系统来说,人脸检测需要在可变姿态,光照,尺度下进行检测。同时人脸的定位和人脸框的大小应该尽可能精确,不要框到背景部分
- 关键点检测,用来定位重要的人脸关键点,如眼睛中点,鼻尖,嘴巴两个嘴角。这些点可以用来做人脸对齐,将人脸归一化到规范的坐标系上,以此减轻人脸内在的旋转和缩放带来的影响
- 特征描述,用于从对齐的人脸上提取足够辨识的信息。
在给定人脸表征基础上,可以通过一个度量方式去计算人脸之间的相似性得分,如果该得分低于阈值,则证明这2个人脸来自同一个人。从1990年代开始,就有很多已经很好工作的人脸验证和识别的方法,不过他们都基于约束条件下。然而这些方法一旦在姿态,光照,分辨率,表情,年龄,背景干扰和遮挡等情况下,准确度就急速下降。而且,视频监控等场景下,目标需要从上百个低分辨率的视频中验证,这就对算法的鲁棒性和实时性提出更严格的要求。
为了解决这些问题,研究者将深度学习引入进来,用来做所需要的特征提取。DCNN已经被证明在图像分析[3]任务上十分强大。在这近5年,DCNN已经用来解决许多CV的问题,如目标识别[3]-[5]和目标检测[6]-[8]。一个典型的DCNN就是多个卷积层和RELU激活函数不断层级重复的网络结构,其能够学到丰富而且具有判别性的表征,DCNN近期已经成功用在如人脸检测[2,9,10],关键点定位[2,10,11],人脸识别和验证[12]。其中一个关键的成功因素仍归功于大量标记的数据如:
- 用于人脸识别的数据集CASIA-WebFace[13],MegaFace[14,15],NS-Celeb-1M[16],VGGFace[17]
- 用于人脸检测的数据集WIDER FACE[18]
这些数据集就包含了丰富的可变性,如姿态,光照,表情,遮挡等等。这些都能让DCNN更鲁棒的去学习这些变化并提取其中有价值的特征。
2.在无约束图像中的人脸检测
人脸检测是人脸识别流程中关键的一环,给定一个图片,人脸检测需要提取图片中所有的人脸位置,并且返回每个人脸的框坐标。之前在无约束人类检测中,使用的特征如Haar 小波和HOG特征等都无法在不同分辨率,视角,光照,表情,皮肤颜色,遮挡,化妆等情况下抓取显著的人脸信息。相对于分类器而言,特征提取不好导致的影响会更大。不过随着近些年的深度学习技术和GPU的使用,DCNN可以更好的特征提取。如[3]中所述,在一个大型数据集上预训练的DCNN可以成为一个比较有意义的特征提取器。然后这些深度特征可以用来广泛的作为通常目标和人脸的检测。基于DCNN的人脸检测方法可以分成两个大类: 基于区域的和基于划框的。
基于区域的
基于区域的方法是生成一堆候选框(一张图片大概2k个),然后DCNN用来分类那个是还不是包含人脸的候选框。其中大多数提取候选框的方式是基于[2,10,19]。比如采用slective search[20]先进行候选框生成,然后用DCNN进行特征提取,并用分类器去分类这些候选框是否是人脸。HyperFace[10]和All in one face[2]就是基于区域的方法的。
Faster rcnn
最近主流的特征提取器就是faster rcnn[19]了,其可以同时回归每个人脸候选框的边界坐标。Li[21]等人基于faster rcnn的框架提出了一个多任务人脸检测,其将一个DCNN和一个三维平均脸模型进行整合,这个三维平均脸模型可以用来提升基于RPN的人脸检测性能,这极大的增强了人脸归一化后的候选框修剪和细化。同样的,chen[22]通过训练一个多任务RPN去进行人脸和关键点检测,在减少冗余人脸候选框基础上生成了高质量候选框,尽可能保持高召回率和准确率之间的平衡,这些候选框随后通过检测到的关键点进行归一化,然后使用一个DCNN人脸分类器去改善性能。
基于划框的
基于划框的方法是在给定尺度基础上,在feature map的每个位置上计算对应的人脸检测得分和候选框坐标。该方法比区域方法要快,而且可以只适用卷积操作就能实现。不同尺度上进行检测通常是通过构建一个图像金字塔来完成。使用该方式的有DP2MFD[9]和DDFD[25],Faceness[26]在全人脸响应基础上加上半脸响应,并基于空间配置将它们结合起来,最后去决定人脸得分,Li[27]提出了一个在多分辨率级联结构,可以快速的在低分辨率阶段上拒绝背景目标,然后在高分辨率阶段就只剩下少量高难度的候选框了
single shot 检测器
Liu[8]提出了ssd结构,该ssd结构是基于划框的一种检测器,它不通过生产图像金字塔形式,而是利用了网络结构本身内在的金字塔结构,通过在不同网络层进行池化,将其输送到最后一层来完成人脸分类和候选框回归。因为检测是一次前向传输,所以SSD总的计算时间要低于faster rcnn。也有一些基于SSD这种想法的网络结构,如Yang提出ScaleFace[28]从网络的不同层提取尺度信息,然后将它们融合到最后一层以完成人脸检测。Zhang提出S3FD[29],其使用一个尺度均衡的框架和尺度补偿的锚点匹配策略来提升对小脸的检测效果。图1就是该方法的架构。
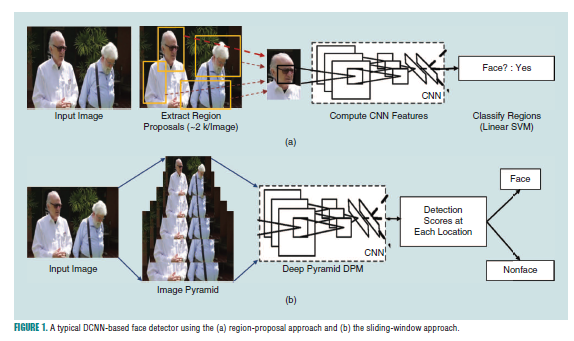
因有大量可以训练的无约束人脸检测数据集的存在,如FDDB[30]数据集是主流的无约束人脸检测数据集,它包含了2,845张图片,一共5,171张人脸,都来自yahoo.com的新闻报道。MALF[31]数据集包含了5,250张高分辨率图像,其中包含了11,931张人脸,这些图片来自Flickr和baidu搜索引擎。这些数据集都在遮挡,姿态,光照下有不少的变化。
WIDER[18]人脸数据集包含32,203张图片,其中50%用于训练,10%用于验证。该数据集中的人脸在姿态,光照,遮挡,尺度上也有不少变化。基于该数据集训练的人脸检测去获得了更好的性能[19,23,28,29,32,33].该数据集评估的结果揭示了,在拥挤的环境下寻找小脸仍然是一个挑战。近期有Hu[33]等人提出的方法显示上下文信息有助于检测小脸。它可以从更低层级特征中抓取语义信息并且从更高层级特征中抓取上下文信息,从而去检测小脸。如图2.

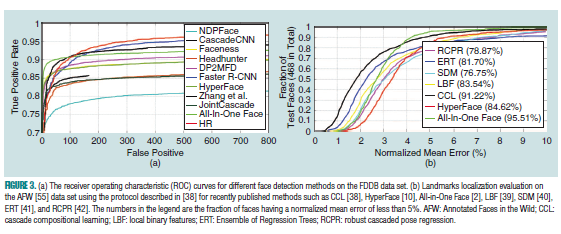
因本文篇幅所限,这里就不讨论传统的人脸检测方法了,可以参考[34],其中介绍了更多传统的级联方法和可变形部件模型(deformable part-based model,DPM)。另外,对于有多个脸的视频,可以通过人脸关联方式去对每个对象进行人脸追踪。可以参考[12],其中有关于基于视频的人脸识别。图3(a)提供了基于FDDB数据集上不同人脸检测方法的性能对比
3.关键点检测和头部角度检测
人脸关键点检测同样也是人脸识别和验证中一个重要的预处理部分。人脸关键点如眼睛中心,鼻尖,嘴角等,可以用来将人脸对齐到规范化坐标中,这样的人脸归一化有助于人脸识别[35]和属性检测。头部姿态评估同样也是基于姿态的人脸分析所需要的过程。这两个问题近些年也有不少研究成果,大多数现有的人脸关键点定位方法用的无非是:
- 基于模型的方法:
- 基于级联回归的方法
wang[36]有个基于传统方法的综述,包含了主动外观模型(active appearance model, AAM),主动形状模型(active shape model, ASM),受限局部模型(constrained local model, CLM),和一些回归方法如有监督下降方法(supervised descent method,SDM
)。Chrysos[37]同样总结了在视频下使用传统人脸检测方法进行人脸关键点追踪的工作。这里我们只是总结近些年基于DCNN进行人流检测的方法。
基于模型的
基于模型的方法,如AAM,ASM,CLM等,是在训练过程中学习一个形状模型,然后用它去拟合测试过程中新的人脸。如Antonakos [43]提出了一种方法,先从区域中提取多个块,然后在块之间使用多个基于图的成对正态分布(高斯马尔可夫随机场)方式,对人脸的形状进行建模。然而所学到的模型还是无法很好适应复杂的姿态,表情,光照下变化,同样的,其对梯度下降优化中的初始化也十分敏感。所以,大家也考虑如何基于3维空间进行人脸对齐。Jourabloo提出PIFA[44],使用三维空间中进行级联回归的方式去预测三维到二维投影矩阵的系数和基准形状系数。另一个来自Jourabloo[45]的工作是将人脸对其问题看成一个密度三维模型拟合问题,其中照相机映射居住和三维形状参数都通过一个基于DCNN回归器级联的方式去评估。Zhu提出的3DDFA[46],采用一个密度三维人脸模型去拟合图像,其中的深度数据采用Z-buffer方式去建模。
基于级联回归的方法
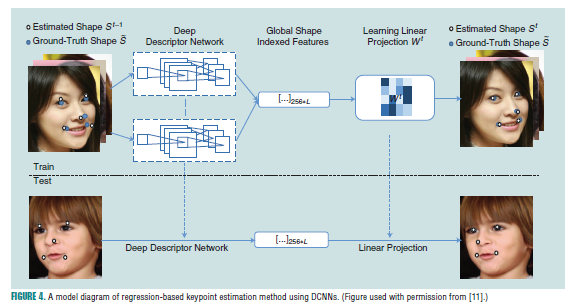
因为人脸对齐是一个回归问题,所以近些年就提出了不少基于回归的方法。通常而言,这些方法学习一个模型去直接将图像外观映射到目标输出上。然而,这些方法依赖于局部描述子的鲁棒性。Sun[47]提出一个基于精心设计的DCNN的级联方法,在每一个阶段,多个网络的输出被融合,从而进行关键点的评估,从而获得不错的效果。Zhang[48]提出一个从粗粒度到细粒度的自动编码器网络,其通过级联几个序列堆叠的自动编码器网络(SAN),前面的SAN用于预测每个人脸关键点的粗略位置,然后后续的SAN通过在更高分辨率基础上基于当前检测的结果提取局部特征,并将该特征作为网络的输入,从而进行关键点的修正。Kumar[11]通过精心设计一个单一的DCNN结构去预测关键点,并获得了更好的效果,如图4。
Xiong[49]提出了领域依赖下降映射(domain-dependent descent map)。Zhu[38]观察到优化基本形状系数和投影之间并不是直接因果关系,因为较小的参数误差不一定等于较小的对准误差。因此他们提出了CCL[38],即基于头姿态和领域选择的回归器(head-pose-based and domain selective regressors),首先基于头部姿态将优化领域划分到多个方向上,并将多个领域回归器的结果通过组成评估函数(composition estimator function)结合起来。Trigeorigis[50]提出基于卷积递归神经网络对回归器进行端到端的学习,并将其用在级联回归框架中。他避免了独立训练每个回归器的问题。Bulat[51]提出了一个DCNN结构,首先进行人脸的部分检测,即使用DCNN的前面几层的特征生成的得分map进行粗略的定位每个人脸关键点,然后通过一个回归分支去对关键点进行修正。因此该算法对检测到的人脸框质量不敏感,而且系统可以端到端的训练。Kumar[52]同样提出了一个在无约束条件下高效的去做关键点估计和姿态预测,其主要通过学习一个热力图的方式去解决人脸对齐问题,这里热力图中的值表示概率值,意在表示在具体位置上某个点存在的概率。
另一边,不同的数据集也提供了不同的关键点标注,300 Faces in the Wild database(300 W) [53] 已经成为一个benchmark,用于衡量不同的关键点方法的性能,它包含了超过12000张带有68个关键点的图片,包括Labeled Face Parts in the Wild[36], Helen [36], AFW [36], Ibug [36], and 600 test images.(i.e., 300 indoor and 300 outdoor.)
除了使用二维变换进行面部对齐之外,Hassner等 [54]提出了一种在通用三维人脸模型的帮助下使面部正面化的有效方法。 然而,该方法的有效性也高度依赖于检测到的面部关键点质量(即,当面部关键点质量差时,该方法通常会引入错误信息)。另外,也有不少方法是基于多任务(multitask learning,MTL)角度去做人脸检测,它们都是同时训练一个人脸检测和对应的人脸关键点估计。MTL有助于网络训练更鲁棒的特征,因为网络得到了额外的监督。例如从关键点获取的眼睛中心和鼻尖有助于网络判别人脸的结构。Zhang[32],Chen[22],Li[21]和HyperFace[10]都采用这样的思路,All in one face[2]基于MTL,将任务扩展到人脸验证,性别,笑容和年龄的估计上,图3(b)展现了基于AFW[55]数据集下不同算法对关键点估计的性能对比。
4.人脸识别和验证
这部分介绍关于人脸验证和识别的工作,图5中,介绍了使用DCNN进行人脸验证和识别的训练及测试流程。
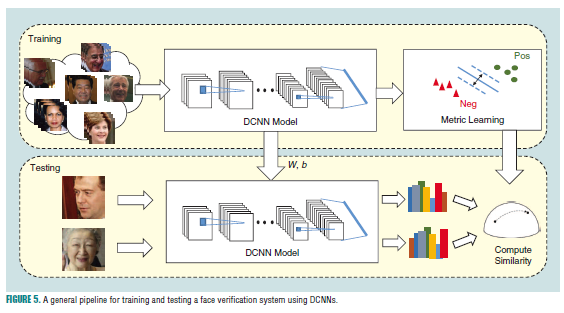
在其中有2个重要的组成部分:
- 鲁棒的人脸表征;
- 一个判别分类模型(人脸识别)或者相似性度量(人脸验证)。
因为本文只专注深度学习的方法,而[56]综述中介绍了基于传统方法,特征上如LBP,Fisher向量等,度量学习上如one-shot similarity(oss),Mahalanobis度量学习,cosine度量学习,large-margin最近邻,基于属性的分类器和联合贝叶斯(joint bayesian,JB)等。
4.1 使用深度学习对人脸进行鲁棒的特征学习
在人脸识别系统中,学习具有不变性和判别性的特征表征是很关键的一步。深度学习方法已经展示出可以在非常大的数据集上学到紧凑而具有判别性的表征。这里先总结下一些使用深度学习做特征表征学习的方法。
Huang[57]等人抛弃了传统的手动设计特征的方法如LBP等,而是提出基于局部卷积受限玻尔兹曼机上采用卷积深度置信网去学习人脸表征。他们首先基于自然场景下未标记的图片数据集,在无监督基础上学习有用的表征,然后通过分类器(SVM)和度量学习方法(OSS)将这些学到的表征用在人脸验证和识别上。该方法在未使用大规模标记人脸数据集训练的情况下,在LFW数据集上的结果也十分满意。
在早期基于三维空间的DCNN人脸识别的应用是由Taigman提出的DeepFace[58]。在该方法中,使用一个九层的DNN去学习人脸表征,其中包含了超过120百万个参数,且使用了未权重共享的局部连接层,而不是标准的卷积层。采用的训练集是包含4百万张人脸,其中超过4000个ID的数据集。
因为收集大规模标注数据集十分耗时,Sun提出了DeepID结构[59-61],采用联合贝叶斯方式(JB)去做人脸验证,其中利用了集成学习的方法,里面都是相对DeepFace而言,更浅且更小的深度卷积网络(每个DCNN包含四个卷积层,输入大小为39×31×1),其使用的数据集是10177个目标的202599张图片。基于大量不同ID的数据集和DCNN基于不同局部和全局人脸块的训练,是的DeepID学到了具有判别性和信息性的人脸表征。该方法也是首次在LFW数据集上超过人类的方法。
Schroff提出一个基于CNN的人脸识别方法叫做FaceNet[62],其直接优化人脸向量本身而不是如深度学习中那些bottleneck layer。他们基于大致对齐的匹配/非匹配面部块的三元组,使用在线三元组挖掘(online triplet )方法。他们的数据集是一个大型的专有人脸数据集,由1亿到2亿个面部缩略图组成,包含大约800万个不同的ID。
Yang[13]收集了一个公开的大规模标注人脸数据集,CASIA-WebFace,从IMDB上收集的包含494414个人脸图片10575个ID的数据集,网络参数超过5百万个。该模型也使用联合贝叶斯方法,在LFW上获得了满意的结果。CASIA-WebFace也是一个主流数据集了。
Parkhi[17]同样有一个公开的大规模人脸数据集,VGGFace,包含了2.6百万个人脸,2600个ID。如同大名鼎鼎的VGGNet[24]可以用于做目标识别,他使用了triplet embedding来做人脸验证。使用VGGFace训练的DCNN模型在静态人脸(LFW)和视频人脸(youtube face, YTF)上都获得了不错的结果,且只适用单一的网络结构,并且都已经开源。VGGFace数据集也是一个主流数据集。
在近些年的工作中,AdbAlmageed[63]通过基于DCNN,训练正面,半轮廓和全轮廓姿态,以提高无约束环境下人脸识别性能,解决姿态变化的问题。Masi[64]利用一个3-D可变形模型去增强CASIA-WebFace数据集,通过大量合成的人脸去代替众包注释任务收集数据的过程。DIng[65]采用一个新的triplet loss,从不同网络特征层基于人脸关键点周围进行深度特征融合的方式达到了当时视频上的人脸识别最好。Wen[66]提出了一个新的loss函数,其考虑了每个类别的中心点,并用它作为softmax loss的一个正则约束,基于残差神经网络去学习更具有判别性的人脸表征。Liu[67]基于修改的softmax loss,提出一个新颖的angular loss。它生成的判别性angular 特征表征是基于常见的相似的度量和cos距离进行优化的,该模型在基于更小的训练集上训练的结果获得了可媲美最好模型的结果。Ranjan等 [68]也在最近发布的MS-Celeb-1M人脸数据集的子集上使用缩放的L2范数正则对softmax loss进行训练,作者的工作显示正则后的loss优化了类别之间的angular margin。该方法在IARPA benchmark A(IJB-A)数据集[69]上获得了最好结果。除了常用的每帧视频人脸表征的平均聚合,Yang提出一个神经聚合网络[70]基于多个人脸图像或者人脸视频中人脸帧去执行动态权重聚合,获得了 视频人脸表征上简洁而强大的表征。该方法在多个图像集和视频人脸集合上获得了最好结果。Bodla[71]提出一个融合网络,基于两个不同的DCNN模型去组合人脸表征,提升识别性能。
4.2 人脸的判别性度量学习
从数据中学习一个分类器或者相似性度量是另一个提升人脸识别系统的关键部件。许多文献中提出的方法本质上是使用人脸图片或者人脸对中的标签信息。Hu[72]用DNN结构去学习一个判别性度量。Schroff[62]和Parkhi[17]基于triplet loss优化了DCNN的参数,可以直接将DCNN特征嵌入到一个判别性子空间,从而提升了人脸验证的结果。在[73]中,通过一个概率模型去学习判别性的低秩向量用于人脸验证和聚类。宋 [74]提出了一种通过考虑样本之间的逐对距离来批量充分的利用训练数据的方法。
不同于基于DCNN的有监督人脸识别,Yang[75]提出在循环结构中联合深度表征和图像聚类。每个图像在开始时被视为单独的簇,并且使用该初始分组训练深度网络。深度表征和类别成员随后通过迭代方式不断修改,知道聚类个数达到了预定的值。该无监督方法学到的表征被证明可以用在各种任务上,如人脸识别,数据分类等等。Zhang[76]提出通过在深度表示自适应和聚类之间交替来聚类视频中的人脸图像。Trigeorgis[77]提出一个深度半监督的非负矩阵分解方式去学习隐藏的表征,这些表征允许他们自身根据给定人脸数据集不同的未知属性(例如姿势,情绪和身份)来解释聚类。他们的方法同样给予了困难人脸数据集上的解决希望。另一方面,Lin[78]提出了一种无监督聚类算法,该算法利用样本之间的邻域结构,隐式执行域自适应,以改进聚类性能。他们同样用该方法制作了一个大规模噪音人脸数据集,如MS-Celeb-1M[79]。
4.3 实现
人脸识别可以划分成2个任务:
- 人脸验证;
- 人脸识别
对于人脸验证来说,就是给定2张人脸图片,系统去验证这两个人脸是不是来自同一个人。对于人脸识别,就是给定一个未知ID的人脸图片,然后系统通过特征匹配的方式决定该图片的ID是数据库中的哪一个。
对于这两个任务,获得判别性和鲁棒性的特征是十分重要的。对于人脸验证,人脸首先需要通过人脸检测检测出来,然后通过检测到的人脸关键点,采用相似性变换归一化到规范的坐标上。然后每个人脸图片再通过DCNN去获取它的人脸表征,一旦该特征生产,就可以通过相似性度量去计算度量的得分。大多数使用的相似性度量有:
- 人脸特征之间的L2距离;
- cosine相似性,可以表示在angular 空间中特征之间相隔的距离。
同样可以使用多个DCNN去融合网络特征或者相似性得分,如DeepID架构[59-61]或者融合网络[71]。对于人脸识别任务,训练集中的人脸图像会通过DCNN,然后每个ID的特征会存在数据库中。当一个新的人脸图片过来,先计算它的特征表征,然后计算与数据库中每个特征的相似性得分。
4.4 人脸识别的训练数据集
在表1中,我们总结了用来测试算法性能和训练DCNN模型的公开数据集
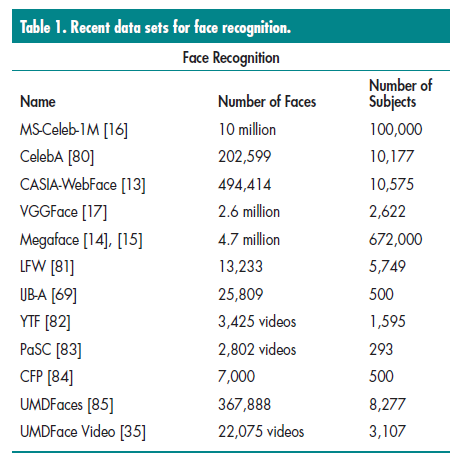
- MS-Celeb-1M[79]是当前最大的的公开人脸识别数据集,包含超过10百万个标记的人脸图像,这1百万个名人列表的前100000个ID有明显的姿态,光照,遮挡和其他变化。因为该数据集同样包含大量的标签噪音,感兴趣的读者可以阅读[78]。
- 对于其他数据集,如CelebA数据集[80],是包含了40个人脸属性和5个关键点的数据集,其是通过专业的标注公司对202599个人脸图片和10000个ID进标注的。
- CASIA-WebFace[13]同样是一个主流的公开数据集,其包含484414张人脸图片和10575个ID,都是来自IMDB网站。
- VGGFace[17]包含2.6百万张人脸和2600个ID。
- MegaFace[14,15]可以用来测试人脸识别算法的鲁棒性,其包含了1百万个干扰在。该数据集包含了2个部分,第一个允许使用外部的训练数据进行扩充,另一个提供了4.7百万张人脸图片和672000个ID。
- LFW[81]数据包含13233个人脸图片和5749个ID,都来自网络,其中1680个ID有两个甚至更多的图片。该数据集主要用来评估静态人脸识别算法性能,大多数都是正脸。
- IJB-A[69]数据集包含500个ID和5397个图片,其中2042个视频划分成了20412帧。该数据集设计用来测试基于较大姿态,光照和图像视频质量变化的基础上的鲁棒性。
- YTF[82]数据集包含3425个视频,涉及1595个iD,是用来测试视频人脸识别算法的标准数据集。
- PaSC[83]数据集包含2802个视频,涉及293个ID,被用来测试基于大的姿态,光照和模糊变化下视频人脸算法的性能,这些视频都来自受控情况下抓取的。
- Celebrities in Frontal-Profile(CFP)[84]数据集包含7000个图像和500个ID,用来测试极端姿态变化下的人脸验证算法。
- UMDFaces[85]和UMDFace Video[35]数据集包含367888个静态图片和82777个ID,以及22075个视频和3107个ID。这些数据集可以用来训练静态和视频的人脸数据集,UMDFace Video中的ID也出现在UMDFaces中,这有助于让模型从静态人脸识别迁移到视频领域。
最近,Bansal[35]研究了一个好的大规模数据集上不同特征,其中涉及到以下问题:
- 我们可以只在静态图片上训练,然后将其扩展到视频上吗?
- 更深的数据集是否好于更广的数据集,这里更深表示每个ID的图片增多,更广表示ID的数量很多?
- 增加标签噪音是否总是能提升深度网络性能?
- 人脸对齐对于人脸识别是否是必须的?
作者调研了CASIA-WebFace[13],UMDFaces[85]和他的视频扩展[35],Youtube face[82]和IJB-A数据集[69]。他发现DCNN同时在静态图片和视频帧上训练可以获得只在其一上训练有更好的结果。基于这个实验,他发现在更小的模型上,在更广的数据集上训练的结果要好于更深的数据集;而对于更深的模型,更广的数据集效果往往更好。[35]的作者工作显示标签噪音通常损害人脸识别的性能,同时发现人脸对齐有助于人脸识别的性能提升。
4.5 性能总结
本文总结了在LFW和IJB-A数据集上人脸识别和验证算法的性能结果
LFW 数据集
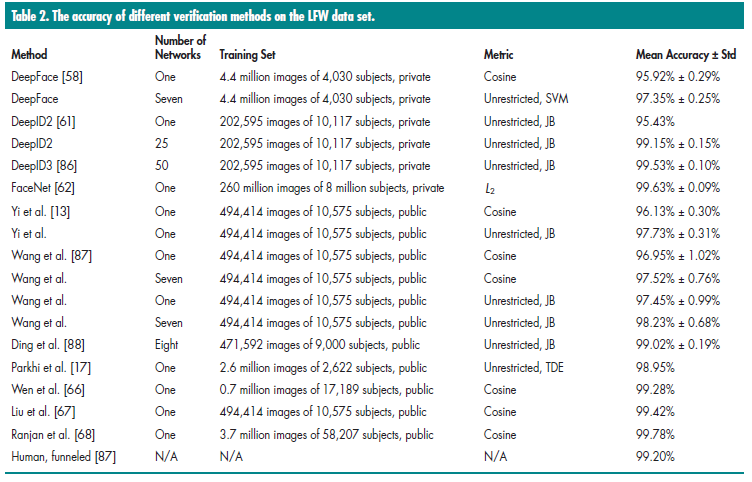
这里采用的人脸验证算法是标准协议,定义3000正对和3000负对,将它们划分到10个不重叠子集中。每个子集包含300个正对和300个负对。他包含7701个图片和4281个ID。如表2,涉及的有DeepFace[58], DeepID2[61], DeepID3[86], FaceNet[62], Yi[13], Wang[87], Ding[88], parkhi[17], Wen[66], Liu[67], Ranjan[68], 和人类的结果
IJB-A benchmark
该数据集中即包含图片也包含视频,视频帧如图6

通过ROC曲线去衡量人脸验证算法的好坏;用累积匹配特征(cumulative match characteristic,CMC)分数测量封闭集合下人脸识别算法的准确度。另外,IJB-A在十个分片集合上做人脸验证(1:1匹配),每个集合包含大概11748对(1756个正对和9992个负对);类似的,在人脸识别上(1:N搜索)也包含了十个分片集合。在每个集合中,大约有112个训练模板和1,763个预测模板(1,187个真正的预测模板和576个冒名顶替的预测模板)。训练集包含333个ID,测试集包含167个没有重复的ID。不同于LFW和YTF数据集,他们只是用一个负对稀疏集去做人脸验证算法的评估,IJB-A数据集将图像/视频帧划分成训练和测试集和,所以所有可用的正和负对都能用来做评估,同样的,每个训练和预测集合都包含多个模板。每个模板(ID)包含来自多个图像和视频的样本集合。而LFW和YTF数据集只包含由Viola Jones 人脸检测器检测的人脸,而IJB-A数据集包含极端姿态,光照,表情等变化。这些因素使得IJB-A变成一个具有挑战的数据集。
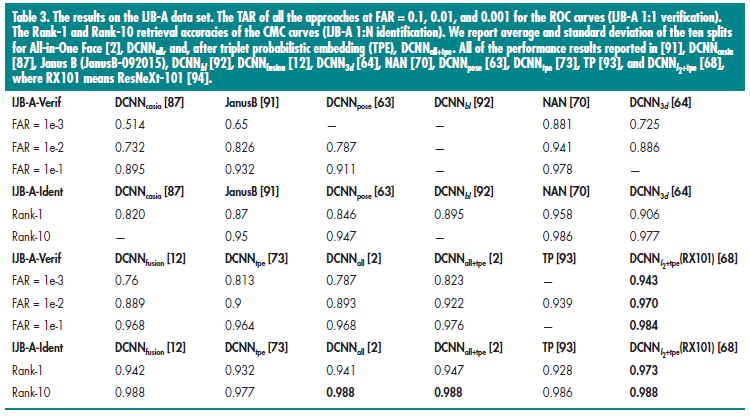
CMC算法和ROC曲线可以用来做不同算法在人脸识别和验证下的性能评估,如表3.
除了使用平均特征表征之外,我们还使用媒体平均,即首先平均来自同一个媒体(图像或视频)的特征,然后进一步平均,媒体平均特征,以生成最终特征表征,然后用triplet概率向量[73]。
表3总结了不同算法的得分,其中对比的算法有:
- (DCNN_{casia})[87]
- (DCNN_{bl}(bilinear CNN))[92]
- (DCNN_{pose}(multipose DCNN模型[63]))[70]
- (DCNN_{3d})[64]
- template adaptation(TP)[93]
- (DCNN_{tpe})[73]
- (DCNN_{all}) [2][all in one face]
- (DCNN_{L2+tpe})[68]
- [91]
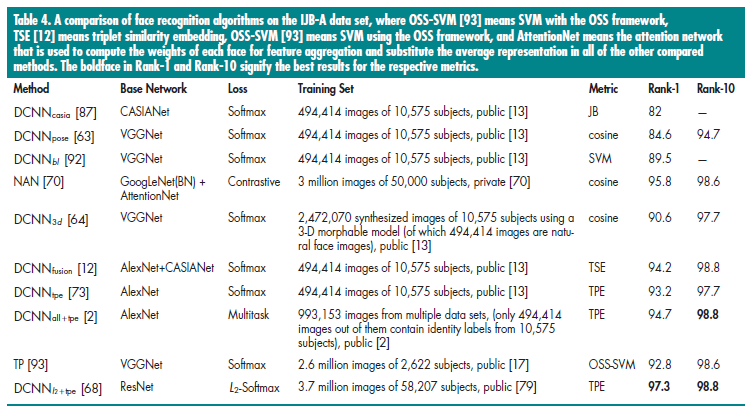
每个算法详细的对比在表4
5.人脸属性
对于一个单一人脸,我们能够验证人脸的属性如:性别,表情,年龄,皮肤颜色等等。这些属性对于图像检索,表情检测和手机安全都有帮助,在生物文献中,人脸属性被称为soft-生物性[95].Kumar[56]将属性概念引入到图像描述子中,以此用来做人脸验证。他们使用65个二值属性来描述每个人脸图像。Berg[56]对每个人脸对训练分类器,然后用这些分类器去生成人脸分类器的特征。这里每个人都被描述为与他人的相似性。这是一种自动创建属性集的方法,而不需要依赖很大的手工标注属性数据集。近些年DCNN也用来做属性分类,如深度属性的姿态对齐网络(pose aligned networks for deep attributes,panda)通过将part-based模型与pose-normalized DCNN来做属性分类[96]。[97]在adience数据集上使用DCNN去关注年龄和性别,Liu使用两个DCNN,一个用来做人脸检测,另一个做属性识别,其在Celeba和LFWA数据集上在许多属性上效果要好于PANDA[80]。
[99]中不将每个属性独立看待,而是利用属性之间的关联性去提升图像的排序和检索,通过先在独立训练属性分类器,然后学习这些分类器输出对之间的相关性。Hand[100]训练一个单一属性网络用来分类40个属性,通过学习这40个属性之间关系去共享网络之间的信息,而不只是属性对。Ranjan[2]用MTL去训练一个单一网络,其可以同时做人脸检测,人脸关键点标注,人脸识别,三维头部姿态估计,性别分类和年龄评估,笑容检测。最近Gunther提出无需对齐的人脸属性分类器技术(alignment-free facial attribute classifcation technique,affact)[101]算法去执行无需对齐的属性分类,它使用了一个数据增强技术,以此允许网络在不需要对齐的基础上做人脸属性分类,盖苏阿凡在CelebA数据集上以三个网络的集成学习方式达到了最好的效果。
另外,一些人脸属性可以用来加速手机认证性能[17]。近期提出的属性连续认证[102,103]方法显示了在大陆属性的基础上可以在手机上获得很好的认证效果。同样的,如果只学习人脸的一部分,那么就变得更容易了。通过使用这两个优势,Samangouei[98]设计了高效的DCNN网络结构,其可以部署在手机设备上,图7介绍了如何将人脸属性用在手机认证上.
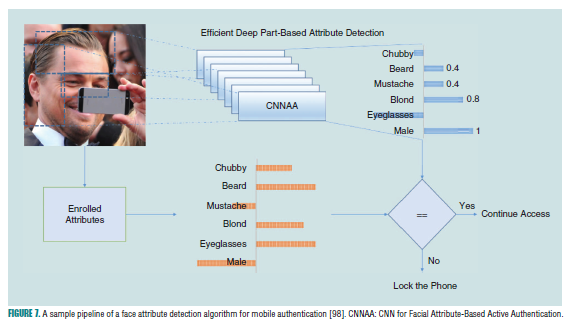
6.人脸分析的多任务学习
在这部分,介绍了几种不同的用于人脸分析的MTL方法。Caruana[104]首先分析了MTL框架在机器学习中的应用,然后,MTL被用来解决CV中的多种问题。基于MTL的一个早期的人脸分析工作是由Zhu[55]提出的。该算法用来解决人脸检测,关键点定位,头部姿态评估。另一个方法叫JointCascade[105],通过结合训练关键点标注任务来提升人脸检测效果。这些算法都是基于手工设计的特征,使得难以将MTL方法扩展到更多的任务上。
在深度学习出来之前,MTL受限于部分数据集,因为不同任务解决的特征表征问题是不同的。例如人脸检测通常使用HOG,而人脸识别使用LBP。类似的,关键点表征,练级和性别估计,属性分类,不同任务自然需要不同特征。然而,随着深度学习的出现,手工设计的特征可以抛弃了,从而训练一个单一的网络结构来实现人脸检测,关键点定位,人脸属性预测和人脸识别成为可能。
通常而言,当人类看图片中的人脸时,他会检测人脸在哪,然后判别其性别,大致姿态,年龄,标签等等。而当机器执行这些任务时,通常需要设计独立的算法去解决不同的任务。然而我们可以设计一个深度网络去同时完成这些所有的任务,并利用任务之间的关系。Goodfellow[106]将MTL解释为一个关于DCNN的正则。在采用MTL方法时,学到的参数可以即刻用在所有的任务上,这减少了过拟合,冰洁收敛于一个鲁棒的解决方法。
HyperFace[10]和任务受限深度卷积网络(Tasks-Constrained deep convolutional network, tcdcn)[107]. HyperFace被提出来解决人脸检测,关键点定位,头部姿态评估,和性别分类。他融合一个DCNN的中间层使得任务能够利用丰富的语义特征。所以MTL可以提升独立任务的性能。Zhang[107]提出TCDCN算法也能同时实现性别识别,笑容预测,眼睛检测等等。在他们的算法中所有任务的预测都来自相同的特征空间。他们的工作显示使用辅助任务例如眼睛检测和笑容预测可以提升人脸关键点定位。
ranjan最近提出的all in one face[2]是使用单一的DCNN来同时完成人脸检测,关键点标注,人脸识别,三维头部姿态估计,笑容检测,人脸年龄检测和性别分类。该结构(图8(a))
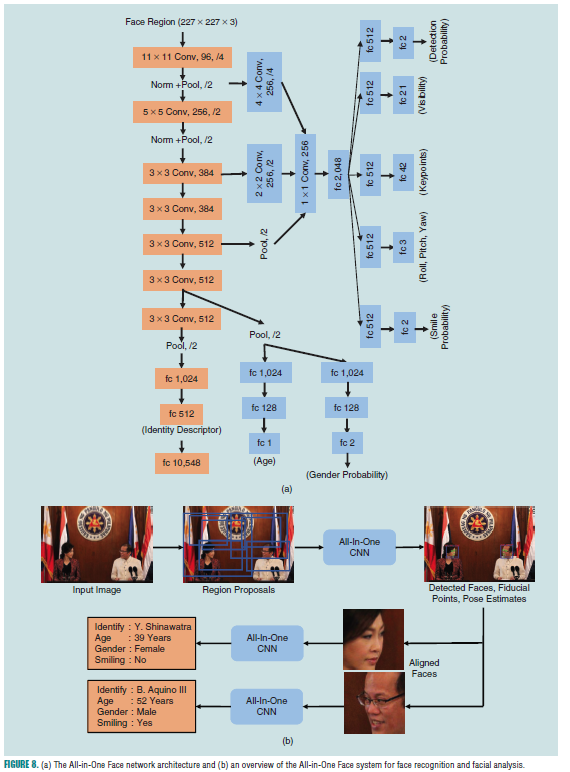
以一个预训练的人脸识别网络开始[73]。该网络有7层卷积层和三层全连接层组成,他用来做基底网络来训练人脸识别任务,且其前6层卷积层的参数用来共享给其他人脸相关的任务。中心原则是在人脸识别任务上预训练的CNN为通用人脸分析任务提供了更好的初始化,因为每一层的过滤器保留了有辨别力的人脸信息。
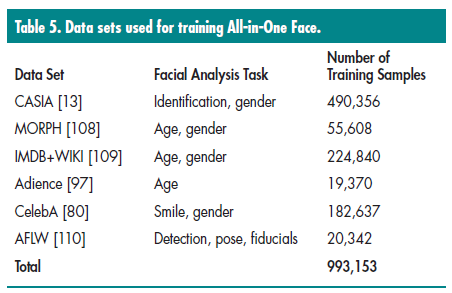
为了利用多个数据集上所有的信息,如人脸框,人脸关键点,姿态,性别,年龄,笑容,和ID信息,多个子网络可以关于任务相关的数据集进行训练,然后将参数进行共享,因为没有一个单一的数据集包含所有人脸分析任务所需的标注信息。通过这种方法,我们可以用参数共享的方式来自适应整个领域,而不是去拟合具体任务领域。在测试的时候,这些子网络融合到一个单一的all in one face中。表5列出了基于不同数据集下训练all in one face。
具体的loss函数用来端到端的训练该网络。all in one face网络输出结果在图9。

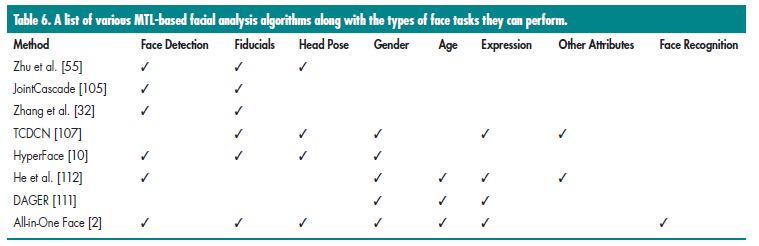
基于MTL的DCNN同样可以用来决定多个人脸属性。Depghan提出深度年龄,性别和表情识别(deep age, gender, and emotion recognition,dager)[111],基于DCNN网络去识别年龄,性别,表情。类似all in one face[2],它基于不同的任务采用不同的数据集去训练该DCNN。He[112]通过训练一个网络去联合的做人脸检测和人脸属性分析。不同于其他MTL方法,他们使用整个图片作为网络的输入,而不只是人脸本身的区域。一个基于faster rcnn的方法可以用来一起检测人脸,表6总结了一些近期基于MTL方法的人脸分析任务
7.开放问题
我们简短的讨论了对于一个自动人脸验证和失败系统的每个组件上的设计思路。包括:
- 人脸检测:相对通用目标检测,人脸检测是一个更具有挑战的任务,因为涉及到人脸的多种变化,这些变化包含光照的,人脸表情的,人脸角度的,遮挡等等。其他因素如模糊和低分辨率一样增大了该任务的难度;
- 关键点检测:大多数数据集包含几千张图片,一个很大的标注和无约束数据集会使得人脸对齐系统具有更强的鲁棒性来应对其中的挑战,如极端的姿态,低光照和小的,模糊的人脸图像。研究者们假设更深的CNN能够抓取更鲁棒的信息;然而目前为止,仍然未研究出哪些层能够准确的提取局部特征来做人脸关键点检测。
- 人脸验证/识别:对于人脸识别和验证而言,性能可以通过学习一个判别性距离度量来提升。由于受显卡的内存限制,如何选择信息对或三元组并使用大规模数据集上的在线方法(例如,随机梯度下降)端到端地训练网络仍然是一个悬而未决的问题。要解决的另一个具有挑战性的问题是在深度网络中加入全动态视频处理,以实现基于视频的人脸分析。
8.总结
可以参考文献[12]
参考文献:
- R. Ranjan, S. Sankaranarayanan, A. Bansal, N. Bodla, J. C. Chen, V. M. Patel, C. D. Castillo, and R. Chellappa. Deep learning for understanding faces: Machines may be just as good, or better, than humans [J]. IEEE Signal Processing Magazine, 35(1):66–83, 2018
- Yiming Lin, Jie Shen, Shiyang Cheng, Maja Pantic. Mobile Face Tracking: A Survey and Benchmark[J] arXiv Preprint, arXiv:1805.09749, 2018.
- Yuqian Zhou, Ding Liu, Thomas Huang. Survey of Face Detection on Low-quality Images[J] arXiv Preprint, arXiv:1804.07362, 2018.
- Xin Jin, Xiaoyang Tan Face Alignment In-the-Wild: A Survey[J] arXiv Preprint, arXiv:1608.04188, 2018.
[1] W. Y. Zhao, R. Chellappa, P. J. Phillips, and A. Rosenfeld, “Face recognition: aliterature survey,” ACM Comput. Surveys, vol. 35, no. 4, pp. 399–458, 2003.
[2] R. Ranjan, S. Sankaranarayanan, C. D. Castillo, and R. Chellappa, “An all-inone convolutional neural network for face analysis,” in Proc. IEEE Int. Conf.Automatic Face Gesture Recognition, 2017, pp. 17–24.
[3] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Proc. Advances Neural Information Processing Systems Conf., 2012, pp. 1097–1105.
[4] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” arXiv Preprint, arXiv:1409.4842, 2014.
[5] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2016, pp. 770–778.
[6] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2014, pp. 580–587.
[7] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Proc. Advances Neural Information Processing Systems Conf., 2015, pp. 91–99.
[8] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “SSD: Single shot multibox detector,” in Proc. European Conf. Computer Vision, 2016, pp. 21–37.
[9] R. Ranjan, V. M. Patel, and R. Chellappa, “A deep pyramid deformable part model for face detection,” in Proc. IEEE 7th Int. Conf. Biometrics Theory, Applications and Systems, 2015, pp. 1–8.
[10] R. Ranjan, V. Patel, and R. Chellappa, “Hyperface: a deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition,” arXiv Preprint, arXiv:1603.01249, 2016.
[11] A. Kumar, R. Ranjan, V. Patel, and R. Chellappa, “Face alignment by local deep descriptor regression,” arXiv Preprint, arXiv:1601.07950, 2016.
[12] J. Chen, R. Ranjan, S. Sankaranarayanan, A. Kumar, C. Chen, V. M. Patel, C. D. Castillo, and R. Chellappa, “Unconstrained still/video-based face verification with deep convolutional neural networks,” Int. J. Comput. Vis., pp. 1–20. 2017.
[13] D. Yi, Z. Lei, S. Liao, and S. Z. Li, “Learning face representation from scratch,” arXiv Preprint, arXiv:1411.7923, 2014.
[14] I. Kemelmacher-Shlizerman, S. M. Seitz, D. Miller, and E. Brossard, “The megaface benchmark: 1 million faces for recognition at scale,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2016, pp. 4873–4882.
[15] A. Nech and I. Kemelmacher-Shlizerman, “Level playing field for million scale face recognition,” in Proc. IEEE Int. Conf. Computer Vision Pattern Recognition, 2017, pp. 873–4882.
[16] Y. Guo, L. Zhang, Y. Hu, X. He, and J. Gao, “Ms-celeb-1m: A data set and benchmark for large-scale face recognition,” in Proc. European Conf. Computer Vision, 2016, pp. 87–102.
[17] O. M. Parkhi, A. Vedaldi, and A. Zisserman, “Deep face recognition,” in Proc. British Machine Vision Conf., vol. 1, no. 3, 2015, p. 6.
[18] S. Yang, P. Luo, C.-C. Loy, and X. Tang, “Wider face: A face detection benchmark,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2016, pp. 5525–5533.
[19] H. Jiang and E. Learned-Miller, “Face detection with the faster R-CNN,” arXiv Preprint, arXiv:1606.03473, 2016.
[20] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders, “Selective search for object recognition,” Int. J. Comput. Vis., vol. 104, no. 2, pp. 154–171, 2013.
[21] Y. Li, B. Sun, T. Wu, and Y. Wang, “Face detection with end-to-end integration of a convnet and a 3D model,” in Proc. European Conf. Computer Vision, 2016, pp. 420–436.
[22] D. Chen, G. Hua, F. Wen, and J. Sun, “Supervised transformer network for efficient face detection,” in Proc. European Conf. Computer Vision, 2016, pp. 122–138.
[23] M. Najibi, P. Samangouei, R. Chellappa, and L. Davis, “SSH: Single stage headless face detector,” arXiv Preprint, arXiv:1708.03979, 2017.
[24] K. Simonyan and A. Zisserman, “Very deep convolutional networks for largescale image recognition,” arXiv Preprint, arXiv:1409.1556, 2014.
[25] S. S. Farfade, M. J. Saberian, and L.-J. Li, “Multi-view face detection using deep convolutional neural networks,” in Proc. ACM Int. Conf. Multimedia Retrievals, 2015, pp. 643–650.
[26] S. Yang, P. Luo, C.-C. Loy, and X. Tang, “From facial parts responses to face detection: A deep learning approach,” in Proc. IEEE Int. Conf. Computer Vision, 2015, pp. 3676–3684.
[27] H. Li, Z. Lin, X. Shen, J. Brandt, and G. Hua, “A convolutional neural network cascade for face detection,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2015, pp. 5325–5334.
[28] S. Yang, Y. Xiong, C. C. Loy, and X. Tang, “Face detection through scalefriendly deep convolutional networks,” arXiv Preprint, arXiv:1706.02863,2017.
[29] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li, “S3 FD: Single shot scale-invariant face detector,” arXiv Preprint, arXiv:1708.05237, 2017.
[30] V. Jain and E. Learned-Miller, “FDDB: A benchmark for face detection in unconstrained settings,” Tech. Rep. vol. 88, Univ. Massachusetts, Amherst, UM-CS-2010-009, 2010.
[31] B. Yang, J. Yan, Z. Lei, and, S. Z. Li, “Fine-grained evaluation on face detection in the wild,” in, Proc. 11th IEEE Int. Conf. WorkshopsAutomatic Face and Gesture Recognition, vol. 1, 2015, pp. 1–7.
[32] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao, “Joint face detection and alignment using multitask cascaded convolutional networks,” IEEE Signal Processing Lett.,vol. 23, no. 10, pp. 1499–1503, 2016.
[33] P. Hu and D. Ramanan, “Finding tiny faces,” arXiv Prepr int, arXiv:1612.04402, 2016.
[34] S. Zafeiriou, C. Zhang, and Z. Zhang, “A survey on face detection in the wild:Past, present and future,” Comput. Vis. Image Understand., vol. 138, pp. 1–24,Sept. 2015.
[35] A. Bansal, C. D. Castillo, R. Ranjan, and R. Chellappa, “The do’s and don’ts for CNN-based face verification,” arXiv Preprint, arXiv:1705.07426, 2017.
[36] N. Wang, X. Gao, D. Tao, H. Yang, and X. Li, “Facial feature point detection: A comprehensive survey,” Neurocomputing, June 2017.
[37] G. G. Chrysos, E. Antonakos, P. Snape, A. Asthana, and S. Zafeiriou, “A comprehensive performance evaluation of deformable face tracking in-the-wild,” Int. J. Comput. Vis., pp. 1–35, 2016.
[38] S. Zhu, C. Li, C.-C. Loy, and X. Tang, “Unconstrained face alignment via cascaded compositional learning,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2016, pp. 3409–3417.
[39] S. Ren, X. Cao, Y. Wei, and J. Sun, “Face alignment at 3000 fps via regressing local binary features,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, June 2014, pp. 1685–1692.
[40] X. Xiong and F. D. la Torre, “Supervised descent method and its applications to face alignment,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2013,pp. 532–539.
[41] V. Kazemi and J. Sullivan, “One millisecond face alignment with an ensemble of regression trees,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2014, pp. 1867–1874.
[42] X. Burgos-Artizzu, P. Perona, and P. Dollár, “Robust face landmark estimation under occlusion,” in Proc. IEEE Int. Conf. Computer Vision, 2013, pp. 1513–1520.
[43] E. Antonakos, J. Alabort-i Medina, and S. Zafeiriou, “Active pictorial structures,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2015, pp. 5435–5444.
[44] A. Jourabloo and X. Liu, “Pose-invariant 3D face alignment,” in Proc. IEEE Int. Conf. Computer Vision, 2015, pp. 3694–3702.
[45] A.Jourabloo and X. Liu, “Large-pose face alignment via CNN-based dense 3D model fitting,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2016,pp. 4188–4196.
[46] X. Zhu, Z. Lei, X. Liu, H. Shi, and S. Z. Li, “Face alignment across large poses: A 3D solution,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2016, pp. 146–155.
[47] Y. Sun, X. Wang, and X. Tang, “Deep convolutional network cascade for facial point detection,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2013, pp. 3476–3483.
[48] J. Zhang, S. Shan, M. Kan, and X. Chen, “Coarse-to-fine auto-encoder networks for real-time face alignment,” in Proc. European Conf. Computer Vision, 2014, pp. 1–16.
[49] X. Xiong and F. D. la Torre, “Global supervised descent method,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2015, pp. 2664–2673.
[50] G. Trigeorgis, P. Snape, M. A. Nicolaou, E. Antonakos, and S. Zafeiriou, “Mnemonic descent method: A recurrent process applied for end-to-end face alignment,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2016, pp. 4177–4187.
[51] A. Bulat and G. Tzimiropoulos, “Convolutional aggregation of local evidence for large pose face alignment,” in Proc. British Machine Vision Conference (BMVC), Sept. 2016, pp. 86.1–86.12.
[52] A. Kumar, A. Alavi, and R. Chellappa, “Kepler: Keypoint and pose estimation of unconstrained faces by learning efficient H-CNN regressors,” in Proc. IEEE Int. Conf. Automatic Face Gesture Recognition, 2017. doi: 10.1109/FG.2017.149
[53] C. Sagonas, E. Antonakos, G. Tzimiropoulos, S. Zafeiriou, and M. Pantic, “300 Faces in-the-wild challenge: database and results,” Image Vis. Comput., vol.47, pp. 3–18, Mar. 2016.
[54] T. Hassner, S. Harel, E. Paz, and R. Enbar, “Effective face frontalization in unconstrained images,” in Proc. IEEE Int. Conf. Computer Vision Pattern Recognition, 2015, pp. 4295–4304.
[55] X. Zhu and D. Ramanan, “Face detection, pose estimation, and landmark localization in the wild,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, June 2012, pp. 2879–2886.
[56] E. Learned-Miller, G. B. Huang, A. RoyChowdhury, H. Li, and G. Hua, “Labeled faces in the wild: A survey,” in Proc. Advances Face Detection Facial Image Analysis Conf., 2016, pp. 189–248.
[57] G. B. Huang, H. Lee, and E. Learned-Miller, “Learning hierarchical representations for face verification with convolutional deep belief networks,” in Proc. IEEE Int. Conf. Computer Vision Pattern Recognition, 2012, pp. 2518–2525.
[58] Y. Taigman, M. Yang, M. A. Ranzato, and L. Wolf, “Deepface: Closing the gap to human-level performance in face verification,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2014, pp. 1701–1708.
[59] Y. Sun, X. Wang, and X. Tang, “Deep learning face representation from predicting 10000 classes,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2014, pp. 1891–1898.
[60] Y. Sun, Y. Chen, X. Wang, and X. Tang, “Deep learning face representation by joint identification-verification,” in Proc. Advances Neural Information Processing Systems Conf., 2014, pp. 1988–1996.
[61] Y. Sun, X. Wang, and X. Tang, “Deeply learned face representations are sparse, selective, and robust,” arXiv Preprint, arXiv:1412.1265, 2014.
[62] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” arXiv Preprint, arXiv:1503.03832, 2015.
[63] W. AbdAlmageed, Y. Wu, S. Rawls, S. Harel, T. Hassne, I. Masi, J. Choi, J. Lekust, J. Kim, P. Natarajana, R. Nevatia, and G. Medioni, “Face recognition using deep multi-pose representations,” in Proc. IEEE Winter Conf. Applications Computer Vision, 2016, pp. 1–9.
[64] I. Masi, A. T. Tran, J. T. Leksut, T. Hassner, and G. Medioni, “Do we really need to collect millions of faces for effective face recognition?” arXiv Preprint, arXiv:1603.07057, 2016.
[65] C. Ding and D. Tao, “Trunk-branch ensemble convolutional neural networks for video-based face recognition,” arXiv Preprint, arXiv:1607.05427, 2016.
[66] Y. Wen, K. Zhang, Z. Li, and Y. Qiao, “A discriminative feature learning approach for deep face recognition,” in Proc. European Conf. Computer Vision, 2016, pp. 499–515.
[67] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song, “Sphereface: Deep hypersphere embedding for face recognition,” in Proc. IEEE Int. Conf. Computer Vision Pattern Recognition, 2017, pp. 212–220.
[68] R. Ranjan, C. D. Castillo, and R. Chellappa, “L2-constrained softmax loss for discriminative face verification,” arXiv Preprint, arXiv:1703.09507, 2017.
[69] B. F. Klare, B. Klein, E. Taborsky, A. Blanton, J. Cheney, K. Allen, P. Grother, A. Mah, M. Burge, and A. K. Jain, “Pushing the frontiers of unconstrained face detection and recognition: IARPA Janus Benchmark A,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2015, pp. 1931–1939.
[70] J. Yang, P. Ren, D. Chen, F. Wen, H. Li, and G. Hua, “Neural aggregation network for video face recognition,” arXiv Preprint, arXiv:1603.05474, 2016.
[71] N. Bodla, J. Zheng, H. Xu, J.-C. Chen, C. Castillo, and R. Chellappa, “Deep heterogeneous feature fusion for template-based face recognition,” in Proc. IEEE Winter Conf. Applications Computer Vision, 2017, pp. 586–595.
[72] J. Hu, J. Lu, and Y.-P. Tan, “Discriminative deep metric learning for face verification in the wild,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2014, pp. 1875–1882.
[73] S. Sankaranarayanan, A. Alavi, C. Castillo, and R. Chellappa, “Triplet probabilistic embedding for face verification and clustering,” arXiv Preprint, arXiv:1604.05417, 2016.
[74] H. O. Song, Y. Xiang, S. Jegelka, and S. Savarese, “Deep metric learning via lifted structured feature embedding,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2016, pp. 4004–4012.
[75] J. Yang, D. Parikh, and D. Batra, “Joint unsupervised learning of deep representations and image clusters,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2016, pp. 5147–5156.
[76] Z. Zhang, P. Luo, C. C. Loy, and X. Tang, “Joint face representation adaptation and clustering in videos,” in Proc. European Conf. Computer Vision, 2016, pp. 236–251.
[77] G. Trigeorgis, K. Bousmalis, S. Zafeiriou, and B. W. Schuller, “A deep matrix factorization method for learning attribute representations,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 3, pp. 417–429, 2017.
[78] W.-A. Lin, J.-C. Chen, and R. Chellappa, “A proximity-aware hierarchical clustering of faces,” in Proc. IEEE Conf. Automatic Face Gesture Recognition, 2017. doi: 10.1109/FG.2017.134
[79] Y. Guo, L. Zhang, Y. Hu, X. He, and J. Gao, “MS-celeb-1m: A data set and benchmark for large scale face recognition,” in Proc. European Conf. Computer Vision, 2016, pp. 87–102.
[80] Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in Proc. IEEE Int. Conf. Computer Vision, 2015, pp. 3730–3738.
[81] G. B. Huang, M. Mattar, T. Berg, and E. Learned-Miller, “Labeled faces in the wild: A database for studying face recognition in unconstrained environments,” vol.1, no. 2, p. 3, Tech. Rep. 07-49, Univ. Massachusetts, Amherst, 2007.
[82] L. Wolf, T. Hassner, and, I. Maoz, “Face recognition in unconstrained videos with matched background similarity,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2011, pp. 529–534.
[83] J. R. Beveridge, P. J. Phillips, D. S. Bolme, B. A. Draper, G. H. Givens, Y. M. Lui, M. N. Teli, H. Zhang, W. T. Scruggs, K. W. Bowyer, and P. J. Flynn, “The challenge of face recognition from digital point-and-shoot cameras,” in Proc. IEEE
Int. Conf. Biometrics: Theory, Applications and Systems, 2013, pp. 1–8. [84] S. Sengupta, J.-C. Chen, C. Castillo, V. M. Patel, R. Chellappa, and D. W. Jacobs, “Frontal to profile face verification in the wild,” in Proc. IEEE Winter Conf. Applications of Computer Vision, 2016, pp. 1–9.
[85] A. Bansal, A. Nanduri, C. Castillo, R. Ranjan, and R. Chellappa, “Umdfaces: An annotated face data set for training deep networks,” arXiv Preprint, arXiv:1611.01484, 2016.
[86] Y. Sun, D. Liang, X. Wang, and X. Tang, “Deepid3: Face recognition with very deep neural networks,” arXiv Preprint, arXiv:1502.00873, 2015.
[87] D. Wang, C. Otto, and A. K. Jain, “Face search at scale: 80 million gallery,” arXiv Preprint, arXiv:1507.07242, 2015.
[88] C. Ding and D. Tao, “Robust face recognition via multimodal deep face representation,” arXiv Preprint, arXiv:1509.00244, 2015.
[89] L. Wolf, T. Hassner, and I. Maoz, “Face recognition in unconstrained videos with matched background similarity,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2011, pp. 529–534.
[90] P. Viola and M. J. Jones, “Robust real-time face detection,” Int. J. Comput. Vis., vol. 57, no. 2, pp. 137–154, 2004.
[91] “IARPA Janus benchmark: A performance report,” National Institute of Standards and Technology (NIST), 2016.
[92] A. RoyChowdhury, T.-Y. Lin, S. Maji, and E. Learned-Miller, “One-to-many face recognition with bilinear CNNs,” in Proc. IEEE Winter Conf. Applications of Computer Vision, 2016, pp. 1–9.
[93] N. Crosswhite, J. Byrne, O. M. Parkhi, C. Stauffer, Q. Cao, and A. Zisserman, “Template adaptation for face verification and identification,” Proc. IEEE Int. Conf. Automatic Face Gesture Recognition, 2017, pp. 1–8.
[94] S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” arXiv Preprint, arXiv:1611.05431, 2016.
[95] A. K. Jain, S. C. Dass, and K. Nandakumar, “Can soft biometric traits assist user recognition?” in Defense and Security. Orlando, FL: Int. Society Optics and Photonics, 2004, pp. 561–572.
[96] N. Zhang, M. Paluri, M. Ranzato, T. Darrell, and L. Bourdev, “Panda: Pose aligned networks for deep attribute modeling,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2014, pp. 1637–1644.
[97] G. Levi and T. Hassner, “Age and gender classification using convolutional neural networks,” in Proc. IEEE Conf. Computer Vision Pattern Recognition Workshops, 2015, pp. 34–42.
[98] P. Samangouei and R. Chellappa, “Convolutional neural networks for attributebased active authentication on mobile devices,” in Proc. IEEE Int. Conf. Biometrics Theory Applications Systems, 2016, pp. 1–8.
[99] B. Siddiquie, R. S. Feris, and L. S. Davis, “Image ranking and retrieval based on multi-attribute queries,” in Proc. IEEE Conf. Computer Vision Pattern Recognition, 2011, pp. 801–808.
[100] E. M. Hand and R. Chellappa, “Attributes for improved attributes: A multitask network utilizing implicit and explicit relationships for facial attribute classification,” in Proc. AAAI Conf. Artificial Intelligence, 2017, pp. 4068–4074.
[101] M. Günther, A. Rozsa, and T. E. Boult, “Affact-alignment free facial attribute classification technique,” arXiv Preprint, arXiv:1611.06158, 2016.
[102] P. Samangouei, V. M. Patel, and R. Chellappa, “Attribute-based continuous user authentication on mobile devices,” in Proc. IEEE Int. Conf. Biometrics Theory Applications Systems, 2015, pp. 1–8.
[103] P. Samangouei, V. Patel, and R. Chellappa, “Facial attributes for active authentication on mobile devices,” Image Vis. Computing, vol. 58, pp. 181–192, Feb. 2017.
[104] R. Caruana, “Multitask learning,” in Learning to Learn. New York: Springer, 1998, pp. 95–133.
[105] Y. W. X. C. D. Chen, S. Ren, and J. Sun, “Joint cascade face detection and alignment,” in Proc. European Conf. Computer Vision, 2014, vol. 8694, pp. 109–122.
[106] I. Goodfellow, Y. Bengio, and A. Courville. (2016). Deep Learning. Cambridge, MA: MIT Press. [Online]. Available: http://www.deeplearningbook .org
[107] Z. Zhang, P. Luo, C. Loy, and X. Tang, “Facial landmark detection by deep multi-task learning,” in Proc. European Conf. Computer Vision, 2014, pp. 94–108.
[108] K. Ricanek and T. Tesafaye, “Morph: A longitudinal image database of normal adult age-progression,” in Proc. Int. Conf. Automatic Face Gesture Recognition, Apr. 2006, pp. 341–345.
[109] R. Rothe, R. Timofte, and L. V. Gool, “DEX: Deep expectation of apparent age from a single image,” in Proc. IEEE Int. Conf. Computer Vision Workshop ChaLearn Looking at People, 2015, pp. 10–15.
[110] M. Koestinger, P. Wohlhart, P. M. Roth, and H. Bischof, “Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization,”
in Proc. IEEE 1st Int. Workshop Benchmarking Facial Image Analysis Technologies, 2011, pp. 2144–2151.
[111] A. Dehghan, E. G. Ortiz, G. Shu, and S. Z. Masood, “DAGER: Deep age, gender and emotion recognition using convolutional neural network,” arXiv Preprint, arXiv:1702.04280, 2017.
[112] K. He, Y. Fu, and X. Xue, “A jointly learned deep architecture for facial attribute analysis and face detection in the wild,” arXiv Preprint, arXiv:1707.08705, 2017.