1. tensorflow工作流程
如官网所示:
根据整体架构或者代码功能可以分为:
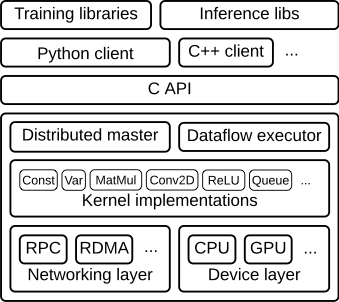
图1.1 tensorflow架构
如图所示,一层C的api接口将底层的核运行时部分与顶层的多语言接口分离开。
而根据整个的工作流程,又可以分为:
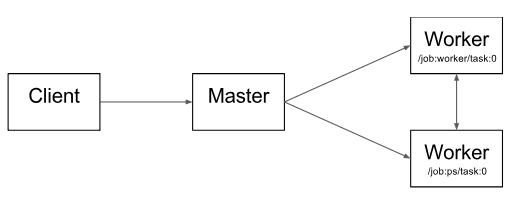
图1.2 不同系统组件之间的交互
而图1.2也是tensorflow整个工作的流程,其中主要分为四个部分:
1.1. 客户端client
- 将整个计算过程转义成一个数据流graph
- 通过session,将graph传递给master执行
ps:假设我们使用的是python作为客户端,则其中session文件在Anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py
1.2. 分布式主节点Distributed Master
- 基于用户传递给Session.run()中的参数来进行修剪整个完整的graph,提取其中特定subgraph;
- 将上述subgraph划分成不同部分,并将其对应不同的进程和devices中;
- 将上述划分的部分分布到worker services上;
- 每个worker services执行其收到的graph块
1.3. 工作节点的服务Worker Services (one for each task)
- 使用可用的硬件kernel(如cpu,gpu)计划执行接收到的graph块表示的计算部分;
- 与其他work services相互发送和接收计算结果
1.4. 核的实现Kernel Implementations
- 执行graph操作的计算部分
现在回到图1.2。其中的"/job:worker/task:0" 和"/job:ps/task:0" ,都是worker services上执行的任务。
- "PS"表示parameter server:一个task负责存储和更新模型的参数
- 其他worker会发送他们迭代优化的参数给PS。
当然如果在单机环境下,上述PS和worker不是必须的,不过如果是分布式训练,这种模式就很常见了。而且上述的 "Distributed Master","Worker Service"只存在于分布式tensorflow中,对于单进程的tensorflow(也就是单机版),一个特定的session就负责了Distributed Master的任何事情,且其自己负责本机的多进程或者说多devices之间的数据交互。
下面,通过一个graph例子详细的介绍下tensorflow的核心模块。
2 client
用户负责在client端编写tensorflow代码,以此行程一个计算graph。该程序可以直接通过底层API组成(如自己写每一层,每一个激活函数),或者使用google提供的如Estimators API等高阶API来完成整个NN的搭建。同时Tensorflow支持多种client端的语言,如Python,CPP。当然随着tensorflow本身的趋于完善,CPP的接口也会越来越多,用于提供更快速的执行效率,当然python接口还是最全的。
client创建一个session,该会话会将graph的定义通过一个tf.GraphDef的protocol buffer 发送给distributed master。当在run中指定了某个graph中的node或者某些nodes,该函数会触发distributed master 去执行所需要的计算。
假如我们的graph如图2.1,就是一个$$s+= wx+b$$
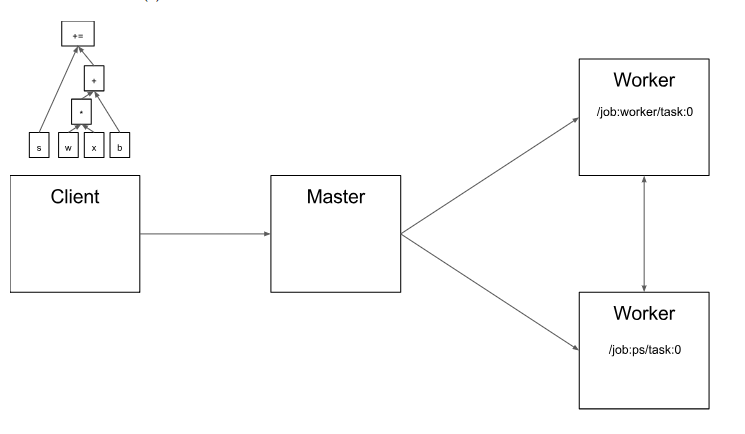
图2.1 基于client端建立的graph
ps:tf.Session
3 Distributed master
该部分的主要工作为:
- 基于client在run中指定的节点,从整个完整的graph中截取所需要的subgraph;
- 将subgraph进一步划分成多个pieces,使其可以将每个piece映射到不同的执行设备上;
- 将划分好的pieces缓存起来,以备后面的其他run的触发。
因为一旦到了master的部分,master可以总揽整个graph,所以它可以使用标准的优化方法去做优化,如公共子表达式消除(common subexpression elimination )和常量的绑定。然后给优化后的subgraphs或者说pieces定义不同的坐标,每个坐标对应了不同的执行设备如"/job:worker/task:0" 和"/job:ps/task:0"
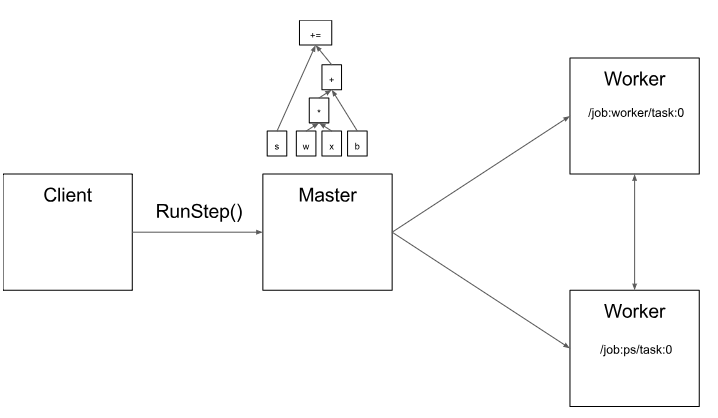
图3.1 client通过运行run,将graph发送给master
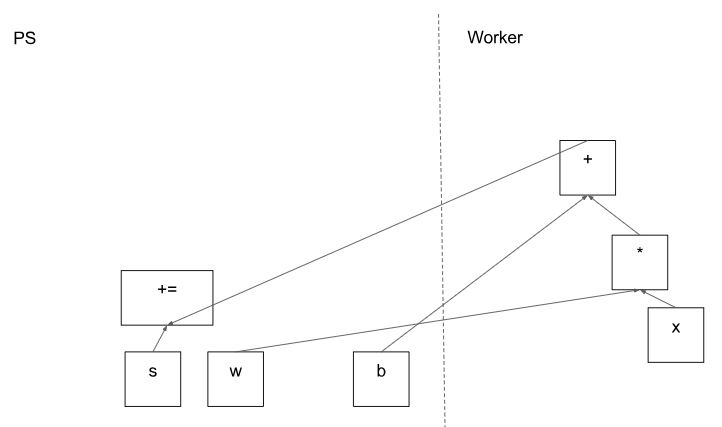
图3.2 master将所需要执行的subgraph划分成参数更新和迭代优化两部分
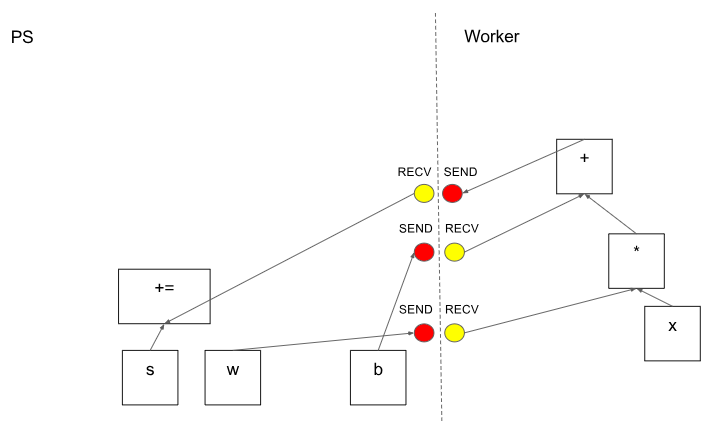
图3.1 master在划分好的subgraph上添加所需要的发送和接收接口,为真实任务分发做准备
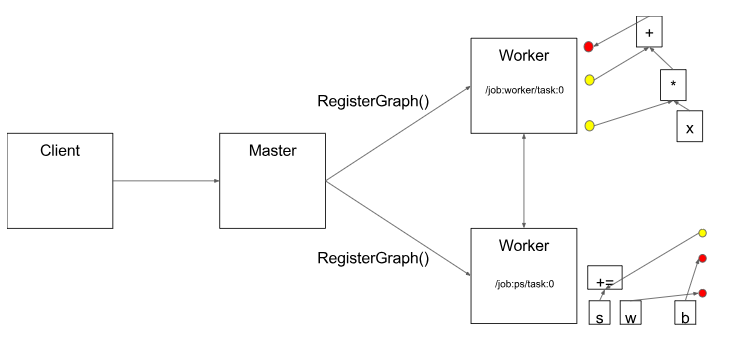
图3.1 master将每个piece通过分布式task分发到真实的节点去运行
Ps:MasterService API definition
Master interface
4 Worker Service
在每个task中,该部分负责:
- 处理从master发来的请求;
- 基于接收到的subgraph,规划所需要执行的kernels;
- 与其他task直接进行消息交换
google优化了该部分,使其就算面对large graph,其负载也很低。当前的版本可以执行每秒上万个subgraphs,这使得大量副本可以进行快速的,细粒度的训练。该部分会将所需要执行的kernels指派给本地的devices,并尽可能的并行执行kernels。例如使用多CPU核或者多GPU流。
该部分还负责具体化源和目标device的Send和Recv操作:
- 使用cudaMemcpAsync()来进行本地CPU和GPU设备之间的数据传输操作;
- 使用点对点的DMA进行GPU之间的传输,以避免需要通过host CPU主内存进行数据传输的高代价
为了在tasks之间进行传输,tensorflow使用多种协议:
- 基于TCP的gRPC;
- 基于Converged Ethernet的RDMA
同时tensorflow也支持NVIDIA的NCCL库来为多GPU之间进行数据交互(tf.contrib.nccl)
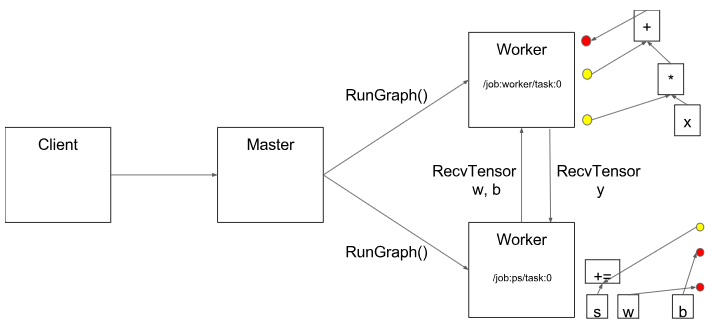
图4.1 worker端接收到的piece;对应的接收发送接口;task之间的交互
ps:WorkerService API definition
Worker interface
Remote rendezvous (for Send and Recv implementations)
5 Kernel Implementations
该运行时包含了超过200个标准操作,其中涉及数学,数组,控制流,和状态管理等操作。每个操作都有对应不同devices的优化后的实现。其中许多kernel是通过使用了CPP的模版的Eigen:Tensor去实现的,主要是为了能生成可以在多CPU和多GPU上运行的高效并行代码。不过如果cuDNN中已经实现了一些kernel,那么就用cuDNN的接口。同时google还实现了quantization,可以更快速的基于移动设备和高吞吐量的数据中心应用进行inference,并且可以使用低精确度的gemmlowp用于加速量化计算。
如果用户发现很难去将子计算组合成一个大计算,或者说组合后发现效率很低,那么用户可以通过注册额外的cpp编写的kernel来提供一个新的接口。例如,可以自己将一些性能敏感的操作如ReLU和Sigmoid等函数(或者其对应的梯度等)进行融合。XLA提供了一个实验性质的自动kernel融合实现
参考资料: