这部分,写一写faster rcnn
0. faster rcnn
经过了rcnn,spp,fast rcnn,又到了faster rcnn,作者在对前面的模型回顾中发现,fast rcnn提出的roi pooling 虽然解决的cnn网络在单张完整图重复计算的问题(每个由ss算法得到的区域候选框都需要过一遍cnn)。
虽然说在训练阶段,不管时间复杂度,无所谓,可是在测试阶段,还是会因为ss算法过慢而无法达到实时的目的,Shaoqing Ren等人发现单一张图上ss基本就需要花费2秒来提取区域候选框,然而即使权衡准确度和速度选择了edgebox算法,每个图片上还是需要花费200ms来做区域候选框提取。所以才提出了RPN这个东西。
RPN:Region Proposal Networks,意图和fast rcnn网络一样,共享前面的cnn层,也就是一张完整的图片经过cnn,达到了最后的feature map,这个feature map需要做两件事:
- 1 提供候选框区域;通过给出区域的坐标回归和当前区域的得分,即该框中是对象的置信度(比如该区域多少面积与真的对象的区域重合,iou越高,该得分越高)
- 2 同时,也需要基于该区域得到对应的ROI,然后接着走fast rcnn 后续网络进行对象的分类和对象的坐标回归任务(包含坐标回归和得分)。
所以按照这个分法,faster rcnn就是由2个网络构成的,如图0.1所示:
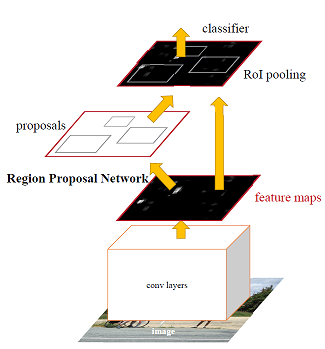
图0.1 faster rcnn网络结构
- 1 用一个深度网络来生成区域候选框:cnn+RPN;
- 2 用一个深度网络来对之前提出的区域候选框进行分类和坐标微调回归:cnn+roiPooling
而如果将上面两个深度网络的cnn部分合并,共享同一个基cnn,那么该网络就叫做faster rcnn
1. RPN
从论文中抠出RPN网络结构如下图所示:
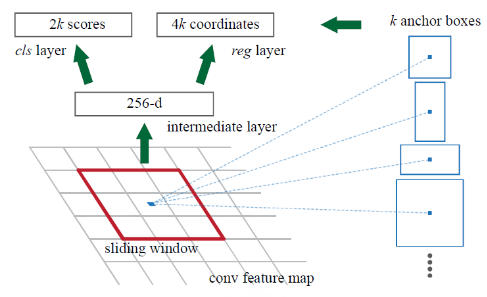
图1.1 RPN网络结构
为了实现直接从CNN最后一个feature map中得到对象候选框,也就是RPN网络的任务,如图1.1所示,在CNN网络的最后一层feature map上建立一个新的,小型网络;
该网络也就是RPN的精华所在,其实就是一个新的小的CNN网络:将由基CNN的feature map作为该网络的图片输入,然后如CNN的卷积一样,建立一,其中k表示当前划框位置上可以预测几个对象候选框。下面介绍。
图中256-d的解释:图中介绍的是基于一个划框下的结果。我们回忆最简单的卷积操作,其实就是对一个感受野做卷积,生成一个值作为下一层map中的一个点。图中表示的其实是一个点,比如:
- 上一个图的大小是13*13*256,
- 通过3*3,stride=1,padd=1,output=256的卷积,生成144个划框的结果。为12*12*256的map;
- 然后再通过一个1*1,output=(2*9)的卷积,生成为12*12*18的map.
图中全都省略每个划框,只针对一个划框,从而对应的就是256-d和2*9的cls层。
其中RPN的输入划窗大小是3*3,按照对应回基CNN的输入层,也就是真实图片上面的区域,分别是171和228,计算过程如下所示,来自这里:

1.1 在图片中如何处理不同尺寸大小的对象的
如上面介绍的RPN网络,在每个划框上,会有k个对象候选框,论文中叫做锚框“anchor box”(或者是reference boxes),这么做的灵感如下图所示:
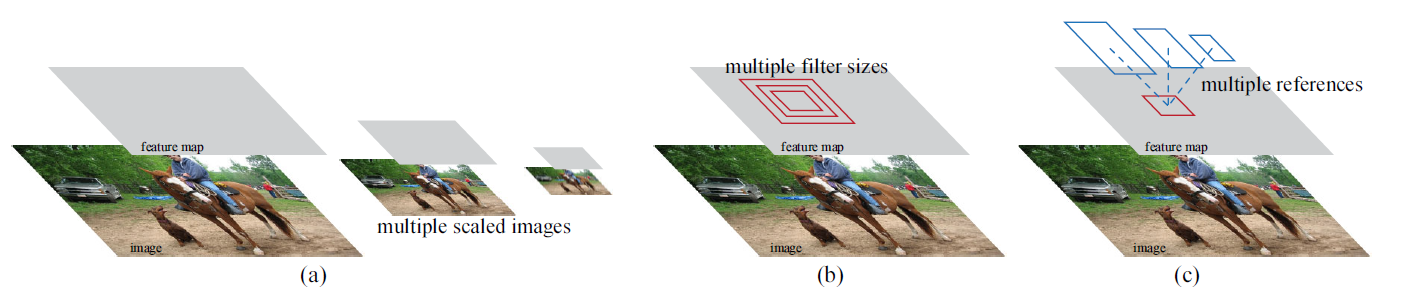
图1.1.1 RPN灵感来源
如图1.1.1所示,在处理不同图片尺寸上,有通过如图像金字塔得到不同尺寸的feature map的,或者在一个图像上使用不同的滤波(即卷积核)大小;而作者不同于他们,在单个尺寸图片和单尺寸滤波器大小上,选取多个不同尺寸的anchor box。从而基于加快整体的速度基础上,还能检测不同尺寸的图片,具有更好的适应性。
1.2 在每个划框上的操作
如1.1所示,作者希望能在每个划框上预测多个不同尺寸的对象(一个划框预测多个对象,每个对象可以存在不同的尺寸),其中当前这个划框上能有k个候选框,每个候选框对应一个分类和坐标回归(如图1.1中的2k和4k)。因为采用了3种缩放因子和3种长宽比,所以k等于9。更进一步,如果当前feature map的大小是40*60,那么就是2400个神经元,按照每个神经元都是可以成为划框中心来说,一共会有2400*9个候选框。量还是挺大的。而基于VGG的话,所需要增加的参数量:卷积核大小3*3,RPN中间层512个神经元,因为VGG有512个通道,且RPN顶层有9个2分类softmax和9个4坐标的回归层,所以:3*3(卷积核)*512(通道数)*512(中间层神经元个数)+512(中间层神经元个数)*(2+4)*9(锚框个数)=(2.4*10^6)
可以看出,该RPN网络在设计的时候本身就是具有平移不变性了,即当图片中的某个对象从一个位置移动到另一个位置,也能通过RPN网络得到相同的候选框区域,故而该网络具有很强的平移不变性
1.3 训练RPN
对于RPN网络的分类和回归层来说:分类层就是一个2分类,是将当前的候选框标记为对象还是非对象。
对于训练集的采样:其中,论文将2种情况下的锚box标记为正标签。
- 1 当前候选框与groundtruth的iou最高的时候;
- 2 与任何一个groundtruth的iou超过0.7的时候。
而当当前候选框与groundtruth的iou低于0.3的时候作为负标签。所以可想而知会发生一个groundtruth被多个候选框标记为正标签的情况。虽然第二种标记正标签的方法在很多时候也够用,不过还是会有极端情况下不满足0.7这个阈值,所以论文采用了第一种标记方法,以此保证正样本的足够(也就是一个划框中9个锚box中选取一个锚box为正标签)。而对于介于中间那些无标记的锚box,则让他们不参与误差的反向传播,也就是不对这些框做采样,不把它们放入训练集中。当然如果当前9个锚box对应的本就是背景,那么当前划框中9个候选框就没正标签了,不过因为每个锚box对应的输入层感受野本身就很大,所以应该很少会存在没有正标签的情况。
对于RPN的目标函数:

图1.3.1 RPN网络中单张图下的目标函数
如图1.3.1所示,在单张图基础上,有如上的目标函数,其中(p_i)为RPN预测的当前锚box是否是对象的概率,(p_i^*)是训练过程中人工标记的当前锚box是否是对象的值(故而该值只有0和1这两个值)。
(N_{cls})为当前batch size的值,而(N_{reg})为什么不也是batch size的值呢?个人觉得是因为分类部分是固定的,比如batch size等于256,也就是有256个锚box,因为每个锚box一定有0和1存在,而回归是建立在当当前锚box的确预测对了的基础上,所以这时候假如当前batch中有10个正锚box,而如果回归部分还是除以256,会有失公允,所以除以整体的2400(一张图上划框的总数),并引入(lambda)来权衡两个部分,不过作者通过实验发现(lambda)的值不是很敏感。
对于faster rcnn整个网络的训练如下面步骤:
- 1 用imagenet的分类网络来初始化基CNN,然后随机初始化RPN网络,并整体进行微调;
- 2 对基CNN,重新用imagenet的分类网络来初始化,然后将之前RPN网络预测得到的区域候选框来微调fast rcnn;
- 3 这时候固定住基CNN,微调RPN部分;
- 4 还是固定住基CNN,微调fast rcnn的ROI-pooling部分。
如上四步,这两个任务代表的网络就共享了基CNN。
待续。。。
参考文献:
[] - .faster rcnn