引言
推荐系统中的推荐是建立在海量数据挖掘基础上的,主要是给用户提供个性化的信息服务和决策支持,其主要作用是:
- 降低信息过载
- 发掘长尾
- 提高转化率
按照现在说法,推荐系统其实就是人,货,场中的场。主要就是将不同的信息推荐给不同的人,分为:
- 个性化,千人千面,精准到个人一面
- 非个性化,如热门推荐,编辑精选,相似推荐等
如从零搭建推荐系统——数据篇中所述,"将历史数据与现实流量打通,针对用户产生的行为数据挖掘出画像信息,结合物料信息共同构建出个性化的推荐模式"。
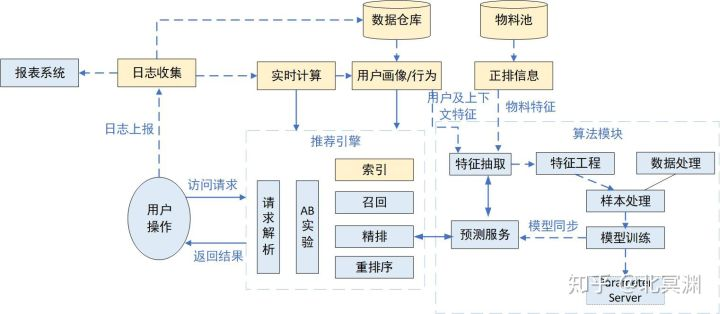
如图所示,物料池其实就是推荐系统中的货,而上图中的例子主要是新闻类推荐,众所周知,新闻类推荐和电商类推荐两者内在还是存在诸多不同的。如电商领域,货物通过录入系统录入之后,并接受各种标签以及描述信息的填写,这类数据,也就是物料主要以hive,hbase形式存储。
其实物料如何存储,如hive的大,但是慢,还是采用列式数据库hbase快速读取,这都取决于整个推荐系统的架构,推荐系统领域发展至今,其内部诸多功能并不是单一统一的,各个企业都有各自的考量点,如阿里妈妈的MIMN模型中,就是将不实时的部分解耦开,存储到外部,等用到再调用一样的道理。
虽然关于物料池的排序问题主要益于搜索系统,但是推荐系统也有其用武之地,如当对物料池进行以品类进行倒排后,在召回阶段(现在都基本是多路召回)的同品类商品召回上,就十分迅速了。关于电商数据如何采集以及如何建表,可参考书籍《大数据之路 阿里巴巴大数据实践》和《大数据大创新 阿里巴巴云上数据中台之道》
正排
假定物料池中一个物料如下:
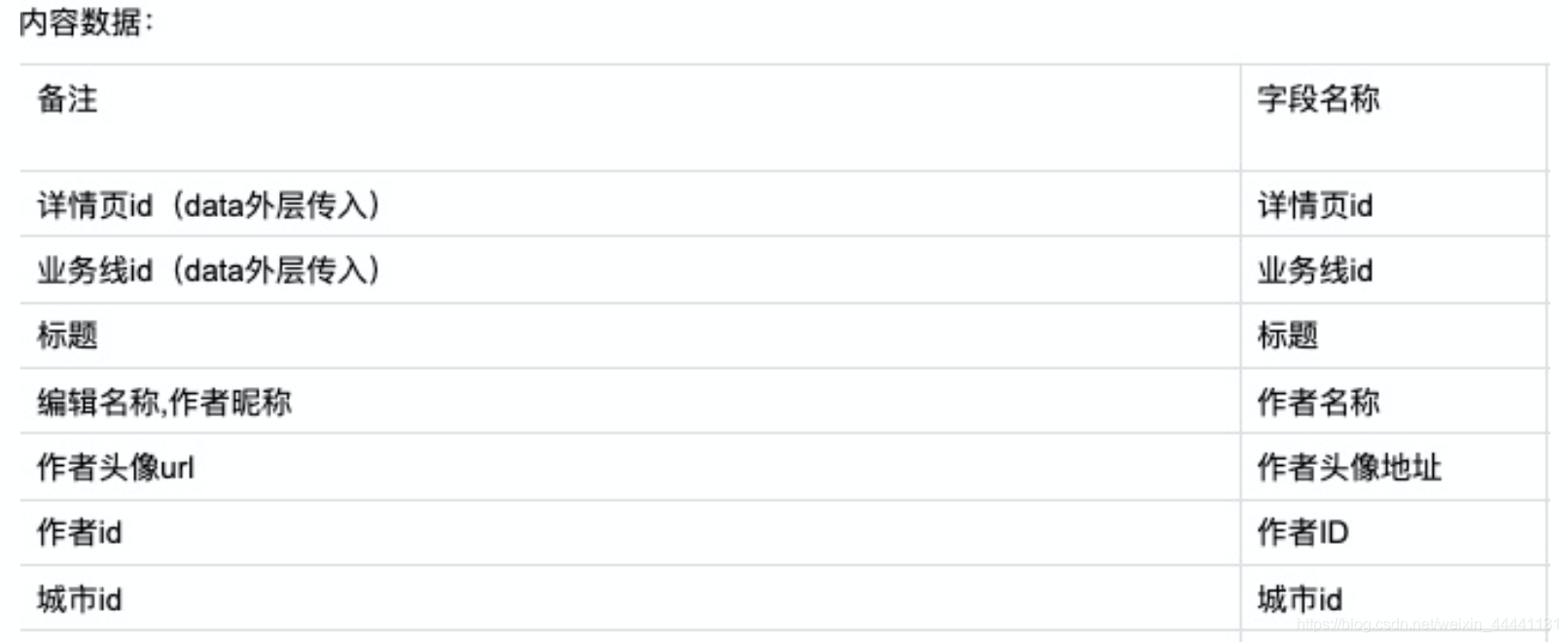
用每条物料唯一的ID去取到这条物料的各种属性字段,查询这条物料的详细情况,这就是我们通常意义下的正排索引。所以如果要想知道多少物料包含某个属性,针对正排只有遍历这一条路。
正排索引其实就是数据结构中简单的排序了,什么快排啊,归并排序啊,直接对id从小到大排序即可。
倒排
在推荐系统的召回阶段,我们实际要取到某个特征、主题或关键词下的所有物料,作为推荐的候选集,如文章中提到的推荐池,是基于一些规则,从整体物料库(可能会有几十亿甚至百亿规模)中选择一些item进入推荐池,再通过汰换规则定期进行更新。比如电商平台可以基于近30天成交量、商品在所属类目价格档位等构建推荐池。
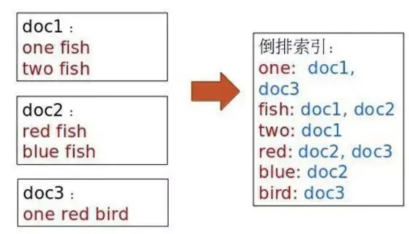
这个时候就反过来了,是由以特征为出发点去找具备这些特征的物料,这就是所谓的倒排索引。如下图就是关于文本的倒排索引的例子