本文来自《Generative Visual Manipulation on the Natural Image Manifold》,是大神Jun-Yan Zhu在2016年9月的作品。
0 引言
视觉交流在现在的社会发展中一直处于技术不够强大的现状,比如你想要去商场买个衣服,你想要告知导购衣服的颜色,款式,花纹等等,而最后导购拿出来的衣服却并不是你心中所想,这时候如果是个画家,他可以将自己所思所想画出来让导购看,而非画家就很难将心中所想进行可视化了。然而Photoshop虽然强大,可是能够精通的也没几个。而且非画家画出来的东西也是抽象多过具体让人糊涂。
对自然图像流行进行理解并建模一直是个未解决的问题。不过GAN的提出让该问题变得相对容易了些。不过还是有2个方面让GAN等方法不能落地:
- 生成的图像虽然很好,可是仍然不能与真实场景拍摄的照片相比(还有分辨率不高的问题);
- 这些生成模型通过一个潜在的向量空间,以随机采样的方式来生成图片,那么意味着不可控,即用户不能和画画一样指定如拉伸,填充等操作。
本文中朱俊彦使用GAN去学习自然图像的流行,不过不是用来做图像生成,而是用来作为各种图像编辑操作输出上的约束,即让结果能一直处在学到的自然图像流行上。这就可以让用户使用好几个编辑操作,如颜色,形状等等。然后模型自动调整输出,尽可能保持结果和真实场景的图像一致。
本文会呈现三种应用:
- 图像编辑:基于潜在的生成模型,操作一个现有存在的图片,改变它的颜色和形状;
- 风格转移:将一个图片进行“生成变换”,让它看起来向另一个图片;
- 图片生成:基于用户的涂鸦和几个UI控件从头生成一张图片。
所有的操作都是以简单直观的方式执行的,基于梯度优化,得到一系列快速简单的图像编辑工具。
1 学习自然图像流行
假设所有的自然图像都落在一个理想的低维度流行(mathbb{M}),其中距离函数(S(x_1,x_2))测量两个图片(x_1,x_2 in mathbb{M})之间的感知相似度(perceptual similarity)。直接对(mathbb{M})进行建模是极具挑战的,因为需要在一个高度结构化和复杂百万维度空间中训练一个生成模型。随着最近深度生成网络在生成自然图片上的成功,作者通过GAN在一个大规模图像集合上,学习一个模型来近似该图片流行。在得到高质量结果的同时,GAN还有其他的特性。

GAN
主要部分略。定义(z)为生成器的输入,是一个均匀分布([-1,1]^d).定义( ilde{mathbb{M}}={G(z)|zin mathbb{Z} }),并使用它作为理想流行(mathbb{M})的近似( ilde{ mathbb{M}}approx mathbb{M})。同时两个生成的图片间距离函数,近似为对应的潜在向量之间的欧式距离(S(G(z_1),G(z_2))approx ||z_1-z_2||^2)。
GAN作为一个流行近似
使用GAN去近似一个理想的流行有两个原因:
- 它会生成高质量的采样(图2a),虽然有时候会缺少视觉细节,模型可以合成大致看上去很自然合理的样本;
- 潜在空间上的欧式距离通常对应一个感知上有意义的视觉相似度(如图2b)。
所以GAN是一个强大的生成模型,可以很好的对图像流行进行建模。
穿越这个流行
给定两个在该流行上的图片(G(z_0),G(z_N)in ilde{mathbb{M}}),并想找到一个平滑的N+1个图片序列([G(z_0),G(z_1),...G(z_N)])。该问题的思路通常是构建一个image graph,其中image是node,逐对距离函数作为edge,计算开始image和结束image之间的最短路径。在本场景中,计算(min sum_{t=0}^{N-1}S(G(z_t),G(z_{t+1}))),这里(S)是距离函数。在本场景中,(S(G(z_1),G(z_2))approx ||z_1-z_2||^2),所以一个简单的线性插值([(1-frac{t}{N}cdot z_0+frac{t}{N}cdot z_N)]_{t=0}^N)就是最短路径.。图2c就是通过潜在空间中两个点之间插值生成的一个平滑的,有意义的图像序列。这里会用该自然图像的流行近似作为真实的图片编辑。
2 本文方法
图1是本方法的概述。
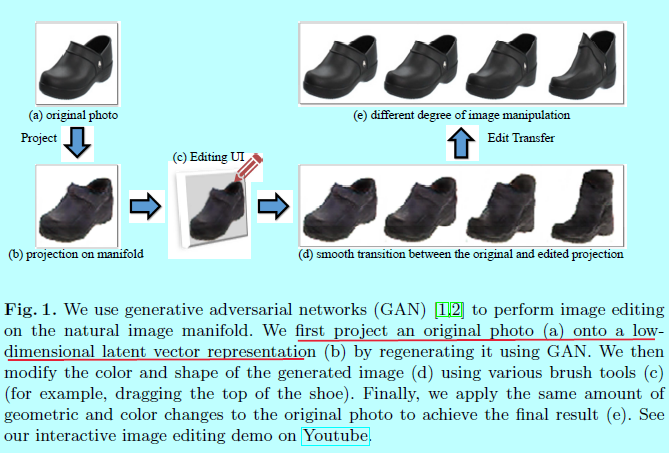
给定一个真实照片,首先将它映射到图像流行的近似上,即找到与原始图片最接近的GAN潜在特征向量(z)。然后,用一个实时的方法逐步和平滑的更新潜在向量(z),生成一个合适的图像,能够同时满足用户的编辑(一个涂鸦或者其他操作)且与自然图像流行保持相近。不幸的是,在该变换中,生成模型通常会丢失输入图像low-level的细节。因此,作者提出了一种密集的对应方法,该方法从应用于生成模型的编辑中估计每像素颜色和形状变化。然后通过边缘感知插值方式迁移这些变化到原始照片上,生成最后的操作结果。
2.1 将一张图像映射到流行上
假定一个真实的照片(x^R)处在理想的图像流行(mathbb{M})上。然而对于近似流行( ilde{mathbb{M}}),这里的目标是找到一个生成的图片(x^{*}in ilde{mathbb{M}})在以某个距离测度方法(mathcal{L}(x_1,x_2))基础上能够接近(x^R):
对于GAN的流行( ilde{mathbb{M}}),将其重写为:
这里的目标是使用生成模型G来重构原始照片(x^R),通过最小化重构误差。基于某个可微分的特征空间(mathcal{C}),(mathcal{L}(x_1,x_2)=||mathcal{C}(x_1)-mathcal{C}(x_2)||^2)。如果(mathcal{C}(x)=x),那么重构误差就简化成逐像素欧式误差。《Generating images with perceptual similarity metrics based on deep networks》和《Perceptual losses for real-time style transfer and super-resolution》等文献表明通过一个DNN可以重构感知上有意义的细节。作者发现将原始像素和AlexNet(基于Imagenet训练的)中conv4的特征(x0.002)进行权重结合的效果最好。
通过最优化来实现映射
正如特征提取器(mathcal{C})和生成模型G是可微分的,可以直接采用L-BFGS-B来优化上述目标函数。然而,(mathcal{C}(G(z)))的级联让问题变得高度非凸,所以重构的结果就严重依赖一个很好的(z)初始化。可以从多个随机初始化开始,输出具有最小cost的结果。然而,随机初始化的重试次数可能很大(超过100次),这让实时处理变得不可能。所以作者直接训练一个DNN来直接最小化式子2
通过一个前向网络来实现映射
训练一个前向NN (P(x; heta_p)),从(x)直接预测潜在向量(z)。预测模型(P)的可训练目标为:
这里(x_n^R)表示数据集中第(n)个图片。模型(P)的结构等同于对抗网络中的判别器D,只是最终输出的网络数量有所不同。目标函数3让人想起AE模型,其中编码器(P),解码器(G)。然而,解码器G在训练中是固定不变的。式子2其实就是式子3,基于学习的方法通常执行的更好,而且也不会陷入局部最优。这里将此行为归因于映射问题的规律性和网络P的有限容量。相似图片的映射会共享相似的网络参数,并生成相似的结果。在许多场景下,一个图片的loss为更多具有相似外观的图像提供信息。然而,AE本身的逆权重矩阵通常不是最优的,需要引入更多的优化方法来提升性能。
一个混合的方法
混合方法同时结合上述2个方法的优点,给定一个真实相片(x^R),首先预测(P(x^R; heta_p)),然后用它作为最优化目标(式子2)的初始化。所以训练好的预测模型扮演着为了解决非凸最优化问题上一个快速自底向上初始化的方法。

图3展示这三个方法的对比。
2.2 操作潜在变量
用上述方法,将图像(x_0^R)映射到流行( ilde{mathbb{M}})上如(x_0=G(z_0)),可以开始修改流行上的图片了,即更新初始化的映射(x_0),通过同时匹配用户的操作并保持其一直位于流行上,使其接近原始图像(x_0)。
每个编辑操作形式化为输出图像(x)上局部位置的一个约束(f_g(x)=v_g)。编辑操作(g)包含颜色,形状和warping constraints。给定一个初始化映射(x_0),去寻找一个新的图片(xin mathbb{M}),使其接近(x_0),并且尽可能满足如下约束:
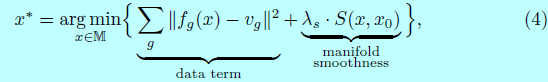
这里数据项是测量约束的偏离程度;平滑项强制在流行上移动一小步,所以图像内容不会修改太多。这里(lambda_s=5)。
上述式子在近似GAN流行( ilde{mathbb{M}})上简化为:

这里最后一项(E_D=lambda_Dcdot log(1-D(G(z))))可选地抓取由GAN鉴别器D判断的,所生成输出的,视觉真实性。其可以将图片推向自然图片流行方向,并轻微提升结果的视觉质量。默认情况下,该项被忽略以加快帧率。
梯度下降更新
最约束的式子5是非凸的。这里通过梯度下降的方式来解决,其允许我们提供给用户一个实时的反馈。目标5也是实时评估的。因为计算的原因,只在改变约束(v_g)后执行一小会的梯度下降更新。每个更新step大概需要50-100ms,这保证交互式反馈。

图4展示了(z)的一个更新例子。给定一个初始化的红鞋,用户逐步的在鞋图片(图4a)上画上黑色的一笔,然后更新方法通过增加越来越多的用户约束,来平滑的改变图片的外观(图4b),一旦最后结果(G(z_1))计算完成,用户可以看到介于初始化点(z_0)和(z_1)之间的插值序列(图4c),然后选择任意中间结果作为新的开始点。
虽然该编辑框架允许用户在近似自然图像流行( ilde{mathbb{M}})上修改任何生成的图片,它不会直接提供给用户一种方法来修改原始高分辨率的图片(x_0^R)。下面会介绍如何在近似流行上的编辑可以变换到原始图片上。
2.3 编辑迁移
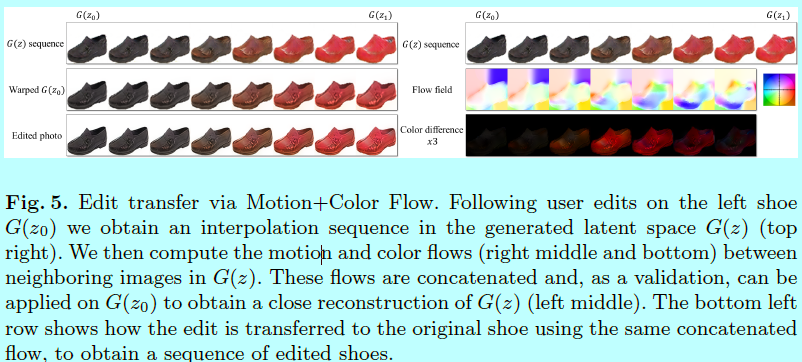
给定原始照片(x_0^R)(如一个黑鞋子),和其在流行上的映射(G(z_0)),和一个基于本文定义的用户修改(G(z_1))(如生成红鞋子),生成的图片(G(z_1))需要捕获到我们大致想要的结果,虽然画质比原始图像有所下降。
那么能否直接调整原始照片,然后生成一个更具真实的结果(x_1^R),其中包含了所需要的修改?一个直观的方法就是直接迁移像素的改变(即(x_1^R=x_0^R+(G(z_1)-G(z_0))))。作者已经尝试了这种方法,而因为两幅图像的错位,其引入了新的伪造图像。为了解决该问题,作者提出一个密集对应算法来同时评估因编辑操作引起的几何和颜色的改变。
具体的,给定两个生成的图片(G(z_0))和(G(z_1)),可以生成任意数量的中间帧([G((1-frac{t}{N})cdot z_0+frac{t}{N}cdot z_1)]_{t=0}^N),连续帧之间仅有轻微的视觉变化。
动作+颜色流动算法(Motion+Color ow algorithm)
通过以传统的光流方法中的亮度恒定性假设来估计颜色和几何变化。其生成下面的动作+颜色流目标:
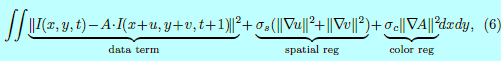
这里(I(x,y,t))表示在生成的图像(G((1-frac{t}{N})cdot z_0+frac{t}{N}cdot z_1))中像素((x,y))上的RGB值((r,g,b,1)^T)。((u,v))是关于(t)改变的流向量,(A)表示一个(3 imes 4)的颜色仿射变换矩阵。数据项通过引入局部仿射颜色转移模型A 来放松颜色恒常性假设(the color constancy assumption),而空间和颜色的正则化项会促进运动和颜色变化的平滑性。
作者通过采用传统光流算法迭代式的评估流((u,v))来解决该目标函数,并通过求解一个线性等式系统来计算颜色变化A。作者迭代3次。并生成8个中间帧(即N=7)。作者同时评估近邻帧之间的变化,然后逐帧来合并这些变化以获得基于任何两帧(z_0
ightarrow z_1)之间的长期变化。
)上应用flow后的warping序列。
{kind=link}
将编辑迁移到原始照片上
在评估生成图像序列中颜色和形状变化后,将他们应用在原始图像上,并生成一个有趣的变化序列。因为flow的分辨率和颜色域的是受限于生成的图像(64x64),需要将这些编辑以一个引导的图像滤波器进行上采样。
3 用户接口
就是如何将该算法与用户进行交互的UI界面。
用户接口包含一个主要窗口用于展示当前编辑的图片,一个展示所有候选结果的缩略图,一个滑动条来搜索原始图片和最终结果之间的图片序列中图片。
候选结果:基于初始化(z),生成多个不同的结果,生成64个结果,并展现按照式子5计算cost最小的9个结果。
略
3.1 编辑约束
该系统提供三个约束来编辑图片:着色(coloring),素描( sketching),扭曲( warping)。所有的约束都是以画刷展示:
- 着色画刷:着色画刷允许用户改变指定区域的颜色。用户从调色盘选取颜色,然后调整画刷size。对于每个以该画刷标记的相似,可以约束每个像素(p)的颜色(f_g(I)=I_p=v_g)到选定的值(v_g);
- 素描画刷:素描画刷允许用户勾勒出形状或者增加细节部分。在图像的具体位置(p)上增加(f_g(I)=HOG(I)_p),一个可微分HOG描述符,以接近用户的笔画(即(v_g=HOG(stroke)_p))。选择HOG特征提取器是因为他可以拿来即用,这也使得其对素描不准确性具有鲁棒性;
- 扭曲画刷:扭曲画刷允许用户更明显的修改形状,用户首先选择一个局部区域(一个可调整size的窗口),将其拖拽到另一个位置。然后在空余区域上面增加颜色和素描约束,以使其模仿拖拽区域的外形。
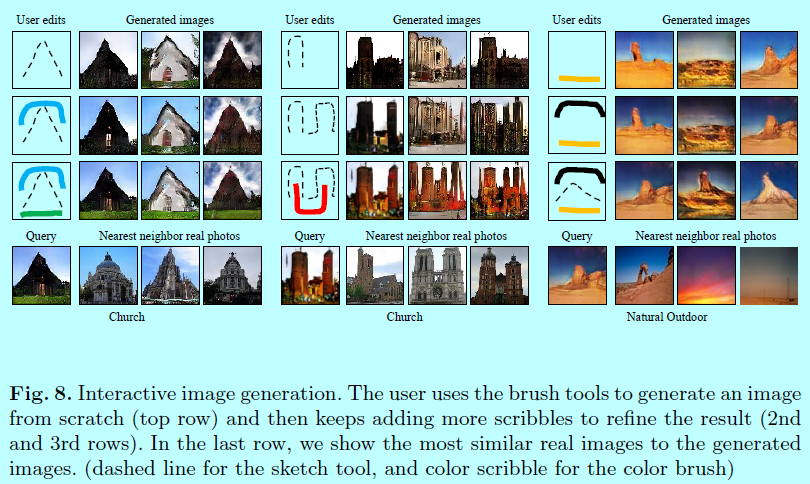
图8 展示颜色和素描画刷用在交互式图片生成的上下文中结果;图1展示用扭曲画刷来拖拉鞋子的顶部;

图6是更多的例子。
4 实现细节
网络结构
采用DCGAN一样的网络结构。基于100维度的随机向量,训练G生成一个64x64x3的图像。注意到本方法也可以用在其他生成模型上(如VAE),去近似自然图像流行。
计算时间
运行在Titan x上,每次更新向量(z)大致需要50-100微秒,一旦编辑完成了,需要5-10秒来将编辑迁移结果去生成高分辨率的最终结果。
5 结果
略


。