1 Field的特性
Document(文档)是Field(域)的承载体, 一个Document由多个Field组成. Field由名称和值两部分组成, Field的值是要索引的内容, 也是要搜索的内容.
-
是否分词(tokenized)
是: 将Field的值进行分词处理, 分词的目的是为了索引. 如: 商品名称, 商品描述. 这些内容用户会通过输入关键词进行查询, 由于内容多样, 需要进行分词处理建立索引.
否: 不做分词处理. 如: 订单编号, 身份证号, 是一个整体, 分词以后就失去了意义, 故不需要分词.
-
是否索引(indexed)
是: 将Field内容进行分词处理后得到的词(或整体Field内容)建立索引, 存储到索引域. **索引的目的是为了搜索. **如: 商品名称, 商品描述需要分词建立索引. 订单编号, 身份证号作为整体建立索引. **只要可能作为用户查询条件的词, 都需要索引. **
否: 不索引. 如: 商品图片路径, 不会作为查询条件, 不需要建立索引.
-
是否存储(stored)
是: 将Field值保存到Document中. 如: 商品名称, 商品价格. **凡是将来在搜索结果页面展现给用户的内容, 都需要存储. **
否: 不存储. 如: 商品描述. 内容多格式大, 不需要直接在搜索结果页面展现, 不做存储. 需要的时候可以从关系数据库取.
2 常用的Field类型
以下是企业项目开发中常用的Field类型:
| Field类型 | 数据类型 | 是否分词 | 是否索引 | 是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue, Store.YES) | 字符串 | N | Y | Y/N | 字符串类型Field, 不分词, 作为一个整体进行索引 (如: 身份证号, 订单编号), 是否需要存储由Store.YES或Store.NO决定 |
| LongField(FieldName, FieldValue, Store.YES) | 数值型代表 | Y | Y | Y/N | Long数值型Field代表, 分词并且索引(如: 价格), 是否需要存储由Store.YES或Store.NO决定 |
| StoredField(FieldName, FieldValue) | 重载方法, 支持多种类型 | N | N | Y | 构建不同类型的Field, 不分词, 不索引, 要存储. (如: 商品图片路径) |
| TextField(FieldName, FieldValue, Store.NO) | 文本类型 | Y | Y | Y/N | 文本类型Field, 分词并且索引, 是否需要存储由Store.YES或Store.NO决定 |
3 常用的Field种类使用
3.1 准备环境
复制Lucene 02 - Lucene的入门程序(Java API的简单使用)中的lucene-first项目, 修改名称为lucene-second;
修改pom.xml文件, 将所有的lucene-first修改为lucene-second.
3.2 需求分析
| Field名称 | 是否分词 | 是否索引 | 是否存储 | Field类型 |
|---|---|---|---|---|
| 图书id | 不需要 | 需要(这里可以索引, 也可以不索引) | 需要 | StringField |
| 图书名称 | 需要 | 需要 | 需要 | TextField |
| 图书价格 | 需要 | 需要(数值型的Field, Lucene使用内部分词) | 需要 | FloatField |
| 图书图片 | 不需要 | 不需要 | 需要 | StoredField |
| 图书描述 | 需要 | 需要 | 不需要 | TextField |
3.3 修改代码
public class IndexManager {
/**
* 创建索引功能的测试
* @throws Exception
*/
@Test
public void createIndex() throws IOException{
// 1. 采集数据
BookDao bookDao = new BookDaoImpl();
List<Book> books = bookDao.listAll();
// 2. 创建文档对象
List<Document> documents = new ArrayList<Document>();
for (Book book : books) {
Document document = new Document();
// 给文档对象添加域
// add方法: 把域添加到文档对象中, field参数: 要添加的域
// TextField: 文本域, 属性name:域的名称, value:域的值, store:指定是否将域值保存到文档中
// 图书Id --> StringField
document.add(new StringField("bookId", book.getId() + "", Store.YES));
// 图书名称 --> TextField
document.add(new TextField("bookName", book.getBookname(), Store.YES));
// 图书价格 --> FloatField
document.add(new FloatField("bookPrice", book.getPrice(), Store.YES));
// 图书图片 --> StoredField
document.add(new StoredField("bookPic", book.getPic()));
// 图书描述 --> TextField
document.add(new TextField("bookDesc", book.getBookdesc(), Store.NO));
// 将文档对象添加到文档对象集合中
documents.add(document);
}
// 3. 创建分析器对象(Analyzer), 用于分词
Analyzer analyzer = new StandardAnalyzer();
// 4. 创建索引配置对象(IndexWriterConfig), 用于配置Lucene
// 参数一:当前使用的Lucene版本, 参数二:分析器
IndexWriterConfig indexConfig = new IndexWriterConfig(Version.LUCENE_4_10_2, analyzer);
// 5. 创建索引库目录位置对象(Directory), 指定索引库的存储位置
File path = new File("/Users/healchow/Documents/index");
Directory directory = FSDirectory.open(path);
// 6. 创建索引写入对象(IndexWriter), 将文档对象写入索引
IndexWriter indexWriter = new IndexWriter(directory, indexConfig);
// 7. 使用IndexWriter对象创建索引
for (Document doc : documents) {
// addDocement(doc): 将文档对象写入索引库
indexWriter.addDocument(doc);
}
// 8. 释放资源
indexWriter.close();
}
}
3.4 重新建立索引
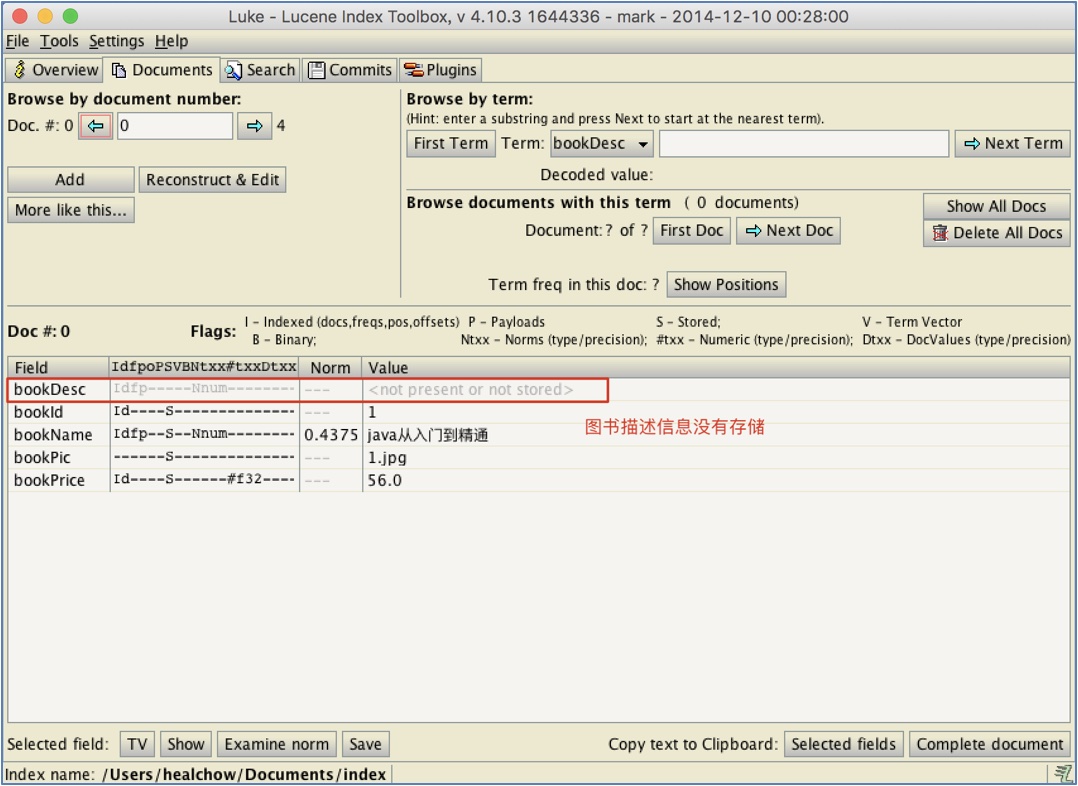
删除之前建立的索引, 再次建立索引. 打开Luke工具查看索引信息, 可看到图书图片不分词, 故没有索引, 图书价格使用了Lucene的内部分词, 故按照UTF-8解码后显示乱码, 如下图示:

图书的描述信息没有存储:
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.