一.什么是存储过程
存储过程,百度百科上是这样解释的,存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来调用存储过程。
简单的说就是专门干一件事一段sql语句。
可以由数据库自己去调用,也可以由java程序去调用。
在oracle数据库中存储过程是procedure。
二.为什么要写存储过程
1.效率高
存储过程编译一次后,就会存到数据库,每次调用时都直接执行。而普通的sql语句我们要保存到其他地方(例如:记事本 上),都要先分析编译才会执行。所以想对而言存储过程效率更高。
2.降低网络流量
存储过程编译好会放在数据库,我们在远程调用时,不会传输大量的字符串类型的sql语句。
3.复用性高
存储过程往往是针对一个特定的功能编写的,当再需要完成这个特定的功能时,可以再次调用该存储过程。
4.可维护性高
当功能要求发生小的变化时,修改之前的存储过程比较容易,花费精力少。
5.安全性高
完成某个特定功能的存储过程一般只有特定的用户可以使用,具有使用身份限制,更安全。
三.存储过程基础
1.存储过程结构
(1).基本结构
Oracle存储过程包含三部分:过程声明,执行过程部分,存储过程异常(可写可不写,要增强脚本的容错性和调试的方便性那就写上异常处理)
(2).无参存储过程

这里的as和is一样任选一个,在这里没有区别,其中demo是存储过程名称。
(3).有参存储过程
a.带参数的存储过程

上面脚本中,
第1行:param1 是参数,类型和student表id字段的类型一样。
第3行:声明变量name,类型是student表name字段的类型(同上)。
第4行:声明变量age,类型数数字,初始化为20
b.带参数的存储过程并且进行赋值
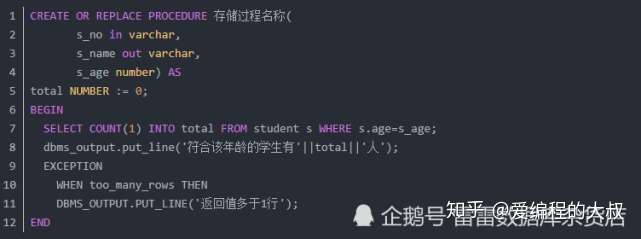
上面脚本中:
其中参数IN表示输入参数,是参数的默认模式。
OUT表示返回值参数,类型可以使用任意Oracle中的合法类型。
OUT模式定义的参数只能在过程体内部赋值,表示该参数可以将某个值传递回调用他的过程
IN OUT表示该参数可以向该过程中传递值,也可以将某个值传出去
第7行:查询语句,把参数s_age作为过滤条件,INTO关键字,把查到的结果赋给total变量。
第8行:输出查询结果,在数据库中“||”用来连接字符串
第9—11行:做异常处理————————————————
2.存储过程语法
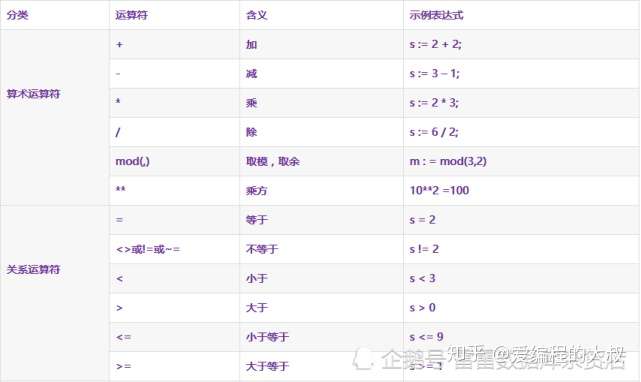
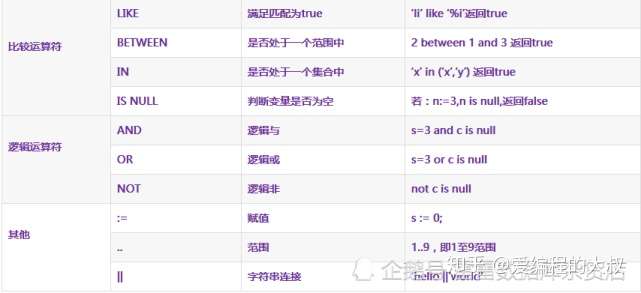
(1).运算符
这里s,m,n是变量,类型是number;
(2).SELECT INTO STATEMENT语句
该语句将select到的结果赋值给一个或多个变量,例如:
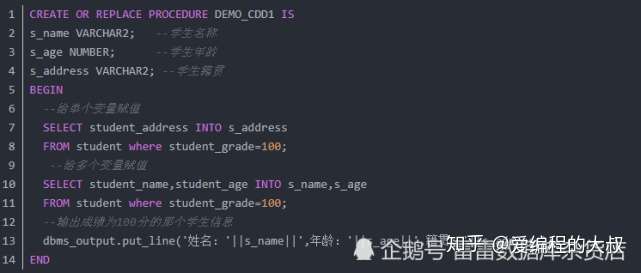
上面脚本中:
存储过程名称:DEMO_CDD1, student是学生表,要求查出成绩为100分的那个学生的姓名,年龄,籍贯
(3).游标
Oracle会创建一个存储区域,被称为上下文区域,用于处理SQL语句,其中包含需要处理的语句,例如所有的信息,行数处理,等等。
游标是指向这一上下文的区域。 PL/SQL通过控制光标在上下文区域。游标持有的行(一个或多个)由SQL语句返回。行集合光标保持的被称为活动集合。
a.下表是常用的游标属性:
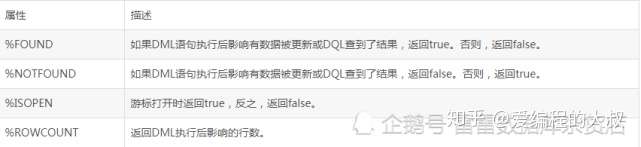
b.使用游标
声明游标定义游标的名称和相关的SELECT语句:
CURSOR cur_cdd IS SELECT s_id, s_name FROM student;
打开游标游标分配内存,使得它准备取的SQL语句转换成它返回的行:
OPEN cur_cdd;
抓取游标中的数据,可用LIMIT关键字来限制条数,如果没有默认每次抓取一条:
FETCH cur_cdd INTO id, name ;
关闭游标来释放分配的内存:
CLOSE cur_cdd;
四.存储过程进阶
在上面的案例中,我们的存储过程处理完所有数据要多长时间呢?事实我没有等到它执行完,在我可接受的时间范围内它没有完成。那么对于处理这种千万级数据量的情况,存储过程是不是束手无策呢?答案是否定的,接下来我们看看其他绝招。
我们先来分析下执行过程的执行过程:一个存储过程编译后,在一条语句一条语句的执行时,如果遇到pl/sql语句就拿去给pl/sql引擎执行,如果遇到sql语句就送到sql引擎执行,然后把执行结果再返回给pl/sql引擎。遇到一个大数据量的更新,则执行焦点(正在执行的,状态处于ACTIVE)会不断的来回切换。
Pl/SQL与SQL引擎之间的通信则称之为上下文切换,过多的上下文切换将带来过量的性能负载。最终导致效率降低,处理速度缓慢。
从Oracle8i开始PL/SQL引入了两个新的数据操纵语句:FORALL、BUIK COLLECT,这些语句大大滴减少了上下文切换次数(一次切换多次执行),同时提高DML性能,因此运用了这些语句的存储过程在处理大量数据时速度简直和飞一样。
1.BUIK COLLECT
Oracle8i中首次引入了Bulk Collect特性,Bulk Collect会能进行批量检索,会将检索结果结果一次性绑定到一个集合变量中,而不是通过游标cursor一条一条的检索处理。可以在SELECT INTO、FETCH INTO、RETURNING INTO语句中使用BULK COLLECT,接下来我们一起看看这些语句中是如何使用BULK COLLECT的。
(2).FETCH INTO
从一个集合中抓取一部分数据赋值给一个集合变量。
(3).RETURNING
BULK COLLECT除了与SELECT,FETCH进行批量绑定之外,还可以与INSERT,DELETE,UPDATE语句结合使用,可以返回这些DML语句执行后所影响的记录内容(某些字段)。
(4).注意事项
a.不能对使用字符串类型作键的关联数组使用BULK COLLECT 子句。
b.只能在服务器端的程序中使用BULK COLLECT,如果在客户端使用,就会产生一个不支持这个特性的错误。
c.BULK COLLECT INTO 的目标对象必须是集合类型。
d.复合目标(如对象类型)不能在RETURNING INTO 子句中使用。
e.如果有多个隐式的数据类型转换的情况存在,多重复合目标就不能在BULK COLLECT INTO 子句中使用。
f.如果有一个隐式的数据类型转换,复合目标的集合(如对象类型集合)就不能用于BULK COLLECTINTO 子句中。