一、应用场景
- 网页爬虫对 URL 去重,避免爬取相同的 URL 地址;
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
- Google Chrome 使用布隆过滤器识别恶意 URL;
- Medium 使用布隆过滤器避免推荐给用户已经读过的文章;
- Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆过滤器减少对不存在的行和列的查找。除了上述的应用场景之外,布隆过滤器还有一个应用场景就是解决缓存穿透的问题。所谓的缓存穿透就是服务调用方每次都是查询不在缓存中的数据,这样每次服务调用都会到数据库中进行查询,如果这类请求比较多的话,就会导致数据库压力增大,这样缓存就失去了意义。
- 字处理软件中,需要检查一个英语单词是否拼写正确
- 在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上
- 利用布隆过滤器我们可以预先把数据查询的主键,比如用户 ID 或文章 ID 缓存到过滤器中。当根据 ID 进行数据查询的时候,我们先判断该 ID 是否存在,若存在的话,则进行下一步处理。若不存在的话,直接返回,这样就不会触发后续的数据库查询。需要注意的是缓存穿透不能完全解决,我们只能将其控制在一个可以容忍的范围内
二、原理分析
1、简介
- 是一个很长的二进制向量和一系列随机映射函数
- 空间效率和查询时间都比一般的算法要好的多
- 不会漏判,但是有一定的误判率(哈希表是精确匹配)
2、原理
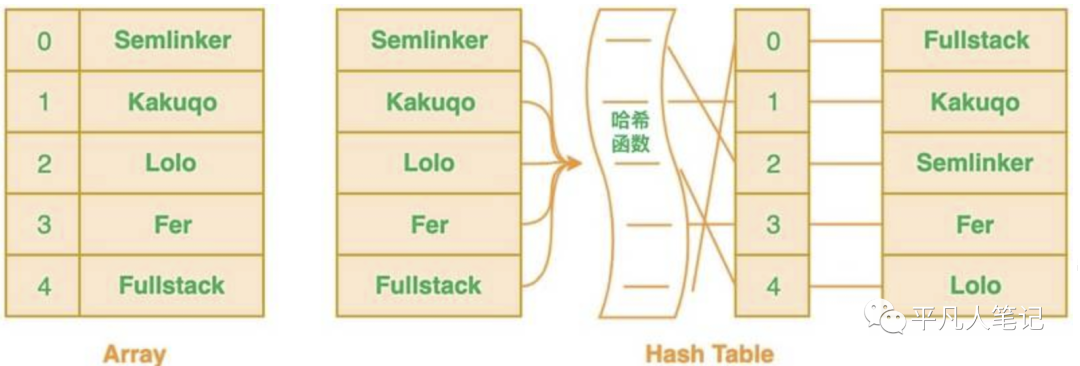
- 若将大数据量放到array中 那么查询某一个值 需要遍历所有的元素
- 若将一个值进行hash计算定位到某一个索引 然后将该值放到该索引里 查询某一个值时可以直接从计算出来的索引位置找 提高索引效率
- hash表是单个函数 只能对应一个索引位置 而布隆过滤器对应多个函数 将对应多个索引位置
简述流程
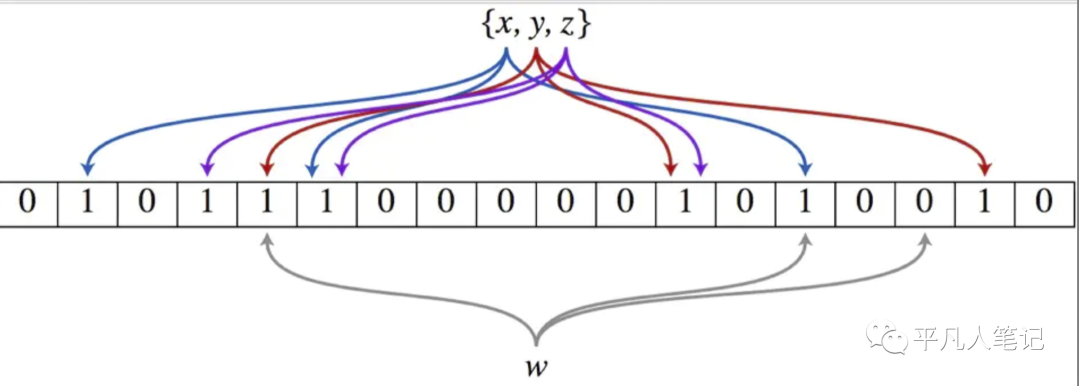
假设集合里面有3个元素{x, y, z},哈希函数的个数为3。
首先将位数组进行初始化,将里面每个位都设置位0。
对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。
查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。
如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。
反之,如果3个点都为1,则该元素可能存在集合中。
注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因
3、误判率
a、为什么存在误判率?
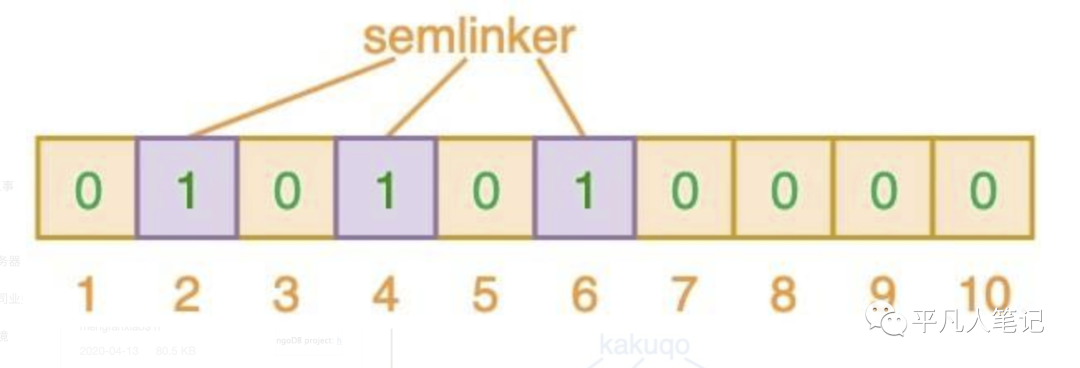
当值为semlinker时 计算的索引为 2、4、6
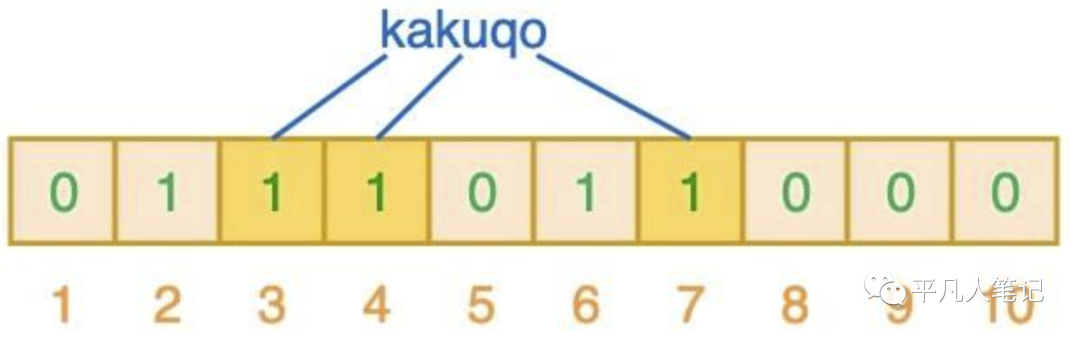
当值为semlinker时 计算的索引为 3、4、7
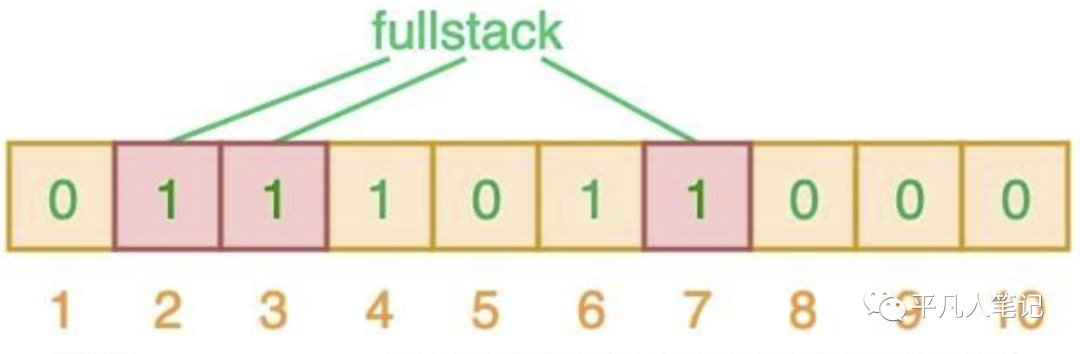
当值为fullstack时 计算的索引为 2、3、7
相应的索引位都被置为 1,这意味着我们可以说 ”fullstack“ 可能已经插入到集合中
b、误判率可以预测?
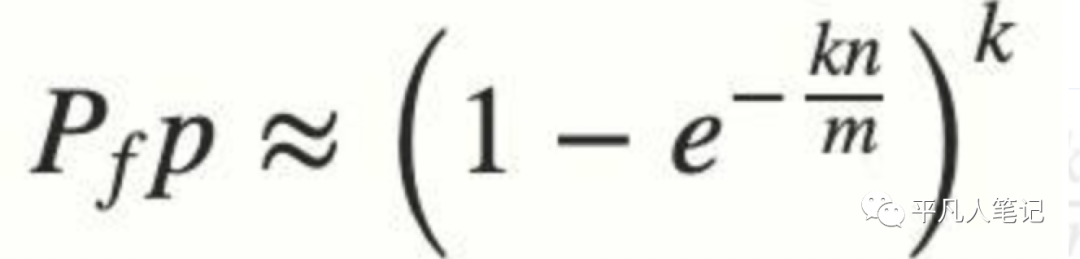
- n 是已经添加元素的数量
- k 哈希的次数
- m 布隆过滤器的长度(如比特数组的大小)
布隆过滤器的长度 m 可以根据给定的误判率(FFP)的和期望添加的元素个数 n 的通过如下公式计算
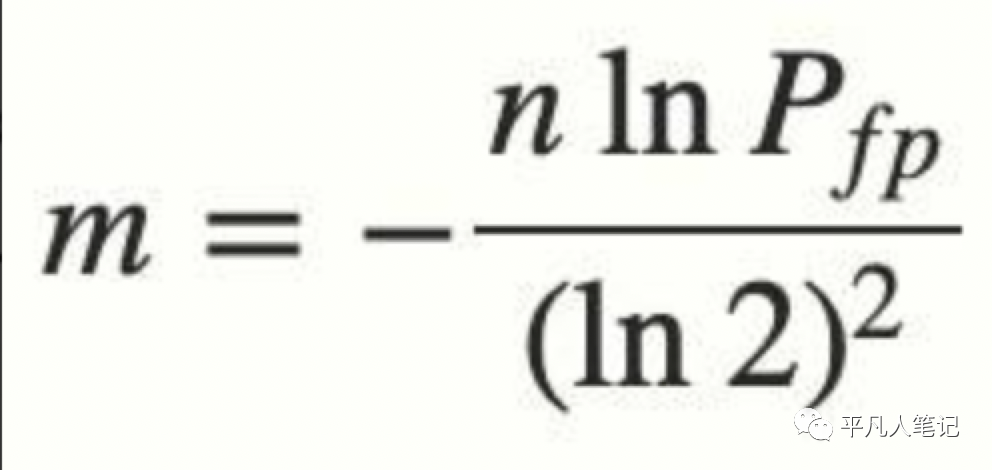
结论:
当我们搜索一个值的时候,若该值经过 K 个哈希函数运算后的任何一个索引位为 ”0“,那么该值肯定不在集合中。但如果所有哈希索引值均为 ”1“,则只能说该搜索的值可能存在集合中
三、实战练习
1、 Guava 库就提供了布隆过滤器
布隆过滤器有很多实现和优化,由 Google 开发著名的 Guava 库就提供了布隆过滤器(Bloom Filter)的实现。在基于 Maven 的 Java 项目中要使用 Guava 提供的布隆过滤器,只需要引入以下坐标:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
在导入 Guava 库后,我们新建一个 BloomFilterDemo 类,在 main 方法中我们通过 BloomFilter.create 方法来创建一个布隆过滤器,接着我们初始化 1 百万条数据到过滤器中,然后在原有的基础上增加 10000 条数据并判断这些数据是否存在布隆过滤器中
package com.jeesite.test.bloom;import com.google.common.base.Charsets;import com.google.common.hash.BloomFilter;import com.google.common.hash.Funnels;/** * Created by ferrari.meng on 14/04/2020. * @公众号 平凡人笔记 * @author mengfanxiao * @date 2020/04/14 */public class BloomFilterDemo {
public static void main(String[] args) {
int total = 1000000; // 总数量
BloomFilter<CharSequence> bf =
BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), total);
// 初始化 1000000 条数据到过滤器中
for (int i = 0; i < total; i++) {
bf.put("" + i);
}
// 判断值是否存在过滤器中
int count = 0;
for (int i = 0; i < total + 10000; i++) {
if (bf.mightContain("" + i)) {
count++;
}
}
System.out.println("已匹配数量 " + count); }
}
以上代码运行后,控制台会输出以下结果:
已匹配数量 1000309
很明显以上的输出结果已经出现了误报,因为相比预期的结果多了 309 个元素,误判率为:
309/(1000000 + 10000) * 100 ≈ 0.030594059405940593
如果要提高匹配精度的话,我们可以在创建布隆过滤器的时候设置误判率 fpp:
BloomFilter<CharSequence> bf = BloomFilter.create(
Funnels.stringFunnel(Charsets.UTF_8), total, 0.0002
);
在 BloomFilter 内部,误判率 fpp 的默认值是 0.03:
// com/google/common/hash/BloomFilter.class
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {
return create(funnel, expectedInsertions, 0.03D);
}
在重新设置误判率为 0.0002 之后,我们重新运行程序,这时控制台会输出以下结果:
已匹配数量 1000003
通过观察以上的结果,可知误判率 fpp 的值越小,匹配的精度越高。当减少误判率 fpp 的值,需要的存储空间也越大,所以在实际使用过程中需要在误判率和存储空间之间做个权衡。
2、简易版布隆过滤器
package com.jeesite.test.bloom;import java.util.BitSet;/** * Created by ferrari.meng on 14/04/2020. @author mengfanxiao * @date 2020/04/14 */public class SimpleBloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static final int[] seeds = new int[] {7, 11, 13, 31, 37, 61,};
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public static void main(String[] args) {
String value = "test@qq.com";
SimpleBloomFilter filter = new SimpleBloomFilter();
System.out.println(filter.contains(value));
filter.add(value);
System.out.println(filter.contains(value));
}
public SimpleBloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]); }
}
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true); }
}
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}}