一般来说数据库是通过一个微服务逻辑统一访问,通常数据库访问两个库的架构图如下所示:
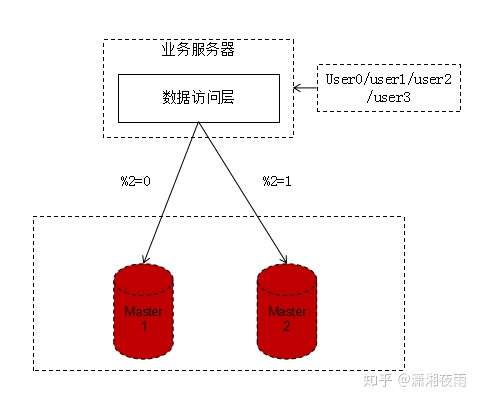
随着数据量的增大,数据库要进行水平切分,分库后将数据分布到不同的数据库实例(甚至物理机器)上,以达到降低数据量,增强性能的扩容目的。
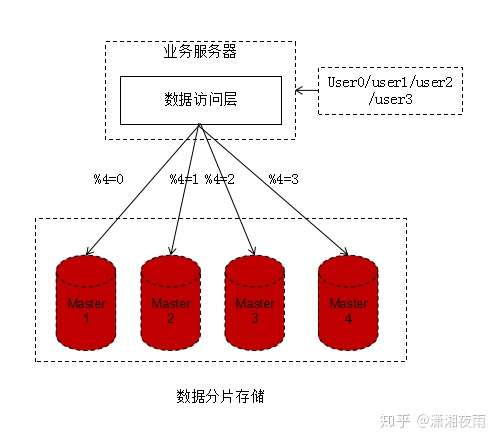
如上图所示,用户库user分布在四个实例上,ip0和ip1,服务层通过用户标识uid取模的方式进行寻库路由,模4余0的访问master上的user库,模4余1的访问master2上的user库,以此类推。
新的问题来了,分成n个库后,随着数据量的增加,要增加到2*n个库,数据库如何扩容,数据能否平滑迁移,能够持续对外提供服务,保证服务的可用性?
停服扩容,是最容易想到的方案?通过对外挂出公告,某个时间段停止服务,在这个过程中进行数据迁移及扩容。
方案优点:简单(what can I say?)
方案缺点:
1、需要停止服务,方案不高可用;
2、技术同学压力大,所有工作要在规定时间内完成,根据经验,压力越大越容易出错;
3、如果有问题第一时间没检查出来,启动了服务,运行一段时间后再发现有问题,则难以回滚,如果回档会丢失一部分数据;
有没有秒级实施、更平滑、更帅气的方案呢?
我们这里提供两种方案,一种在DB网络层实施;一种是在业务逻辑层实施,下面分别介绍。
DB网络层方案
在介绍DB网络层方案之前我们需要先了解一下DB的双主同步+keepalived+虚ip的高可用方案,方案架构图如下:
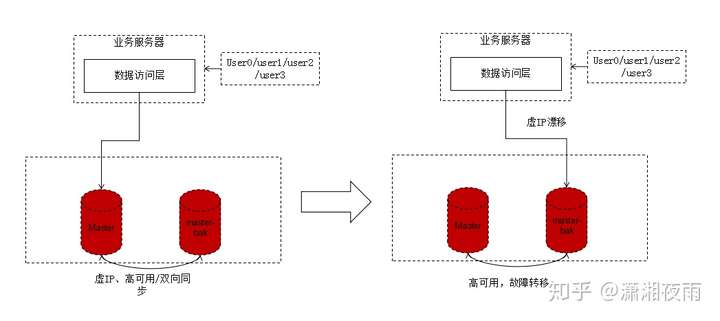
如上图所示,两个相互同步的主库使用相同的虚ip。当主库挂掉的时候,虚ip自动漂移到另一个主库,整个过程对调用方透明,通过这种方式保证数据库的高可用。
我们的DB网络层扩容方案就是以这个方案为基础的,下面还是以2个库扩为4个库为例进行分步骤讲解:
步骤一:修改配置
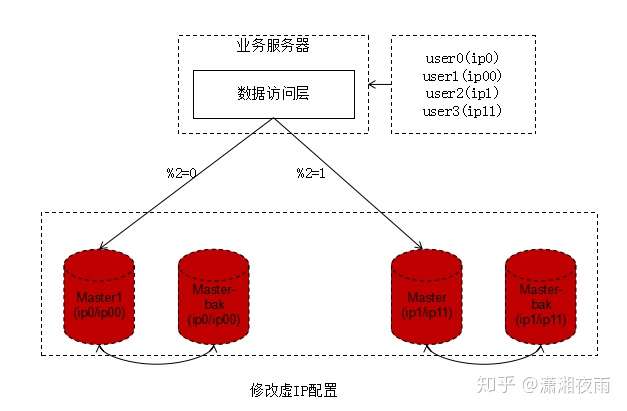
主要修改两处:
数据库实例所在的机器做双虚ip:
1、原%2=0的库是虚ip0,现增加一个虚ip00;
2、原%2=1的库是虚ip1,现增加一个虚ip11;
修改服务的配置,将2个库的数据库配置,改为4个库的数据库配置,修改的时候要注意旧库与新库的映射关系:
1、%2=0的库,会变为%4=0与%4=2;
2、%2=1的部分,会变为%4=1与%4=3;
步骤二:reload配置,实例扩容
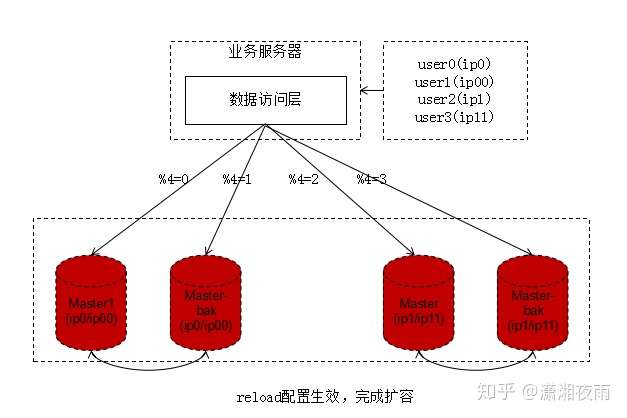
服务层reload配置,reload可能是这么几种方式:
1、比较原始的,重启服务,读新的配置文件;
2、高级一点的,配置中心给服务发信号,重读配置文件,重新初始化数据库连接池;
不管哪种方式,reload之后,数据库的实例扩容就完成了,原来是2个数据库实例提供服务,现在变为4个数据库实例提供服务,这个过程一般可以在秒级完成。
整个过程可以逐步重启,对服务的正确性和可用性完全没有影响:
1、即使%2寻库和%4寻库同时存在,也不影响数据的正确性,因为此时仍然是双主数据同步的;
2、即使%4=0与%4=2的寻库落到同一个数据库实例上,也不影响数据的正确性,因为此时仍然是双主数据同步的;
完成了实例的扩展,会发现每个数据库的数据量依然没有下降,所以第三个步骤还要做一些收尾工作。
步骤三:收尾工作,数据收缩
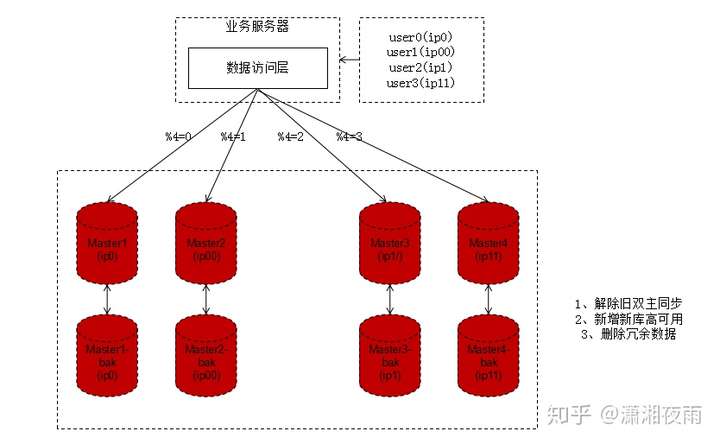
1、把双虚ip修改回单虚ip;
2、解除旧的双主同步,让成对库的数据不再同步增加;
3、增加新的双主同步,保证高可用;
4、删除掉冗余数据,例如:ip0里%4=2的数据全部删除,只为%4=0的数据提供服务。
业务逻辑层方案
该方案无需DB做额外操作,只需要进行数据库新建即可,整体的架构图如下:
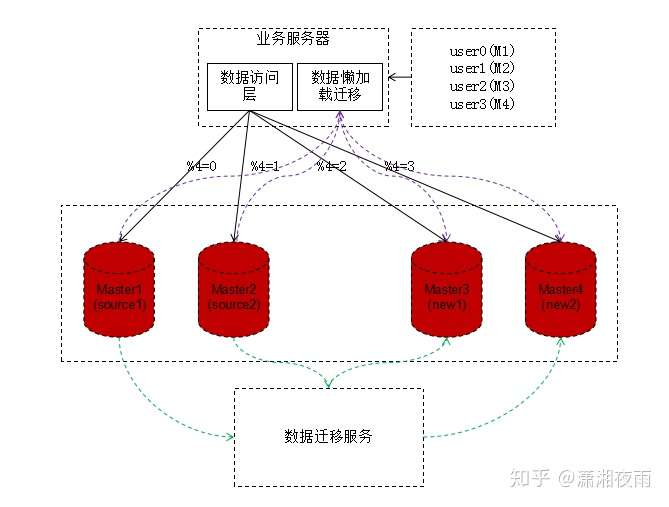
它的主要流程如下:
1、新增两个数据库new1/new2;
2、部署数据迁移服务,从source1以及source2读取数据按照uid的分片映射写入到new1或者new2,相对于下面的懒加载迁移,我们称之为主动加载;
3、部署业务逻辑服务,新增数据懒加载迁移功能,具体逻辑功能流程如下:
3.1、数据访问层先按照扩容后4个服务器进行分发访问,如果获取到数据则正常返回;
3.2、如果没有获取到数据,从扩容前的source数据库获取,获取到数据后则立即返回,同时异步触发数据懒加载迁移模块,将查询到的数据按照最新的分发策略迁移到新的数据库中:
3.3、以上两个步骤就称为懒加载服务,解决了线上主动加载数据不及时的问题:
4、等待主动数据迁移服务将数据迁移完成,则停止懒加载服务,或者配置中心关闭此服务分支逻辑:
5、将源数据库中的冗余数据按照uid分发策略删除。
为什么需要双迁移服务(主动迁移、懒加载迁移)?
如果只有懒加载迁移,那么我们可以想象一下,如果一个用户的数据一直没有访问是不是就无法加载到新数据库?这样就会导致数据迁移无法完成,所以就需要主动加载进行补充。如果只有主动加载服务,当线上业务需要的数据没有落到最新的分片单元时则无法正常获取到。
如果数据扩容出现问题回档怎么处理?
这里没有明确说明,因为以上方案迁移是扩容最终要实现的形态。如果考虑回档方案,可以在扩容后实现双写(按照一份扩容前的分发策略进行异步写入到源数据库);这里就会碰到主动迁移新的数据问题,处理方法很简单,如果迁移过程中发现目标数据库已有uid存在则丢弃即可。
总结
两种方案都实现了数据的平滑快速迁移,DB网络层方案需要对网络同步及配置进行额外处理;而业务逻辑层方案主要是修改业务获取数据的逻辑来对线上数据进行访问兼容实现平滑。以此提供思路。
欢迎关注微信公众号:shoshana