参考:
微软在ICML 2019提出全新的通用预训练方法MASS,在序列到序列的自然语言生成任务中全面超越BERT和GPT。在微软参加的WMT19机器翻译比赛中,MASS帮助中-英、英-立陶宛两个语言对取得了第一名的成绩。
MASS: Masked Sequence to Sequence Pre-training
MASS对句子随机屏蔽一个长度为k的连续片段,然后通过编码器-注意力-解码器模型预测生成该片段。
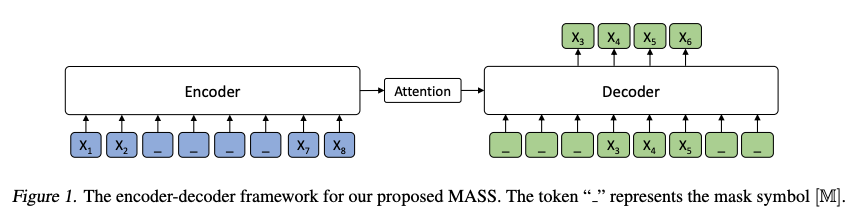
如上图所示,编码器端的第3-6个词被屏蔽掉,然后解码器端只预测这几个连续的词,而屏蔽掉其它词,图中“_”代表被屏蔽的词。
MASS预训练有以下几大优势:
- 解码器端其它词(在编码器端未被屏蔽掉的词)都被屏蔽掉,以鼓励解码器从编码器端提取信息来帮助连续片段的预测,这样能促进编码器-注意力-解码器结构的联合训练;
- 为了给解码器提供更有用的信息,编码器被强制去抽取未被屏蔽掉词的语义,以提升编码器理解源序列文本的能力;
- 让解码器预测连续的序列片段,以提升解码器的语言建模能力。
MASS有一个重要的超参数k(屏蔽的连续片段长度),通过调整k的大小,MASS能包含BERT中的屏蔽语言模型训练方法以及GPT中标准的语言模型预训练方法,使MASS成为一个通用的预训练框架。
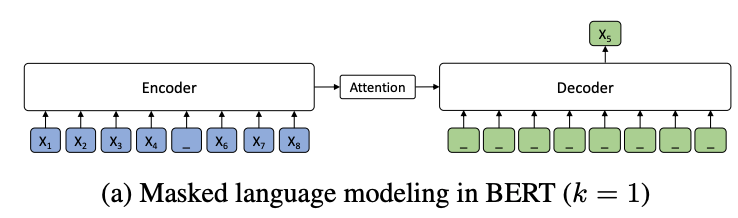
当k=1时,根据MASS的设定,编码器端屏蔽一个单词,解码器端预测一个单词。解码器端没有任何输入信息,这时MASS和BERT中的屏蔽语言模型的预训练方法等价。
当k=m(m为序列长度)时,根据MASS的设定,编码器屏蔽所有的单词,解码器预测所有单词,由于编码器端所有词都被屏蔽掉,解码器的注意力机制相当于没有获取到信息,在这种情况下MASS等价于GPT中的标准语言模型。

MASS在不同K下的概率形式如下表所示,其中m为序列长度,u和v为屏蔽序列的开始和结束位置,x^u:v表示从位置u到v的序列片段,x^u:v表示该序列从位置u到v被屏蔽掉。可以看到,当K=1或者m时,MASS的概率形式分别和BERT中的屏蔽语言模型以及GPT中的标准语言模型一致。

当k取大约句子长度一半时(50% m),下游任务能达到最优性能。屏蔽句子中一半的词可以很好地平衡编码器和解码器的预训练,过度偏向编码器(k=1,即BERT)或者过度偏向解码器(k=m,即LM/GPT)都不能在该任务中取得最优的效果,由此可以看出MASS在序列到序列的自然语言生成任务中的优势。