(1)用对抗性的源实例攻击翻译模型;
(2)使用对抗性目标输入来保护翻译模型,提高其对对抗性源输入的鲁棒性。
生成对抗输入:基于梯度 (平均损失) -> AdvGen

我们的工作处理由白盒NMT模型联合生成的扰动样本 -> 知道受攻击模型的参数
ADVGEN包括encoding, decoding:
(1)通过生成对训练损失敏感的对抗性源输入来攻击NMT模型;
(2)用对抗性目标输入对NMT模型进行了防御,目的是降低相应对抗性源输入的预测误差。
贡献:
1. 研究了一种用于生成反例的白盒方法。我们的方法是一种基于梯度的方法,以平移损失为指导。
2. 我们提出了一种新的方法来提高具有双重对抗输入的NMT的鲁棒性。编码器中的对抗性输入旨在攻击NMT模型,而解码器中的对抗性输入能够防御预测中的错误。
3.我们的方法在两个常见的转换基准上实现了对以前最先进的Transformer模型的显著改进。
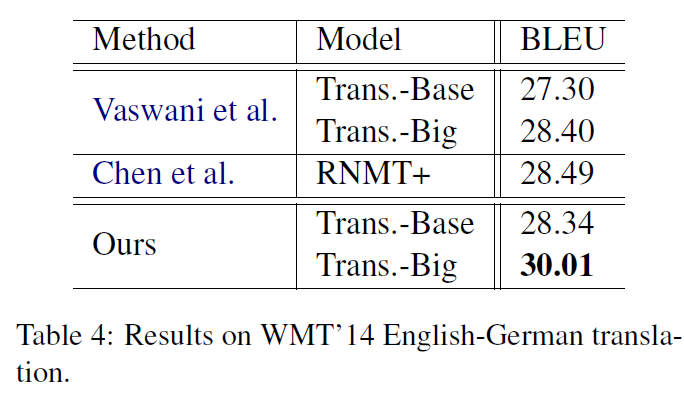
包括Transformer在内的最先进的模型相比,提高了2.8和1.6的BLEU点。这个结果证实了我们的模型在干净的基准数据集上提高了泛化性能。进一步的噪声文本实验验证了该方法提高鲁棒性的能力。我们还进行消融研究,以进一步了解我们的方法的哪些部分最重要。
背景
解码器生成的y:

对抗样本:
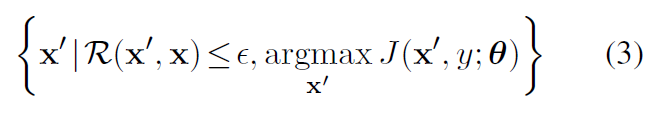
方法
ATTACK
我们的目标是学习健壮的NMT模型,可以克服输入句中的小扰动。即使是一个单词的变化也可以被感知。NMT是一个序列生成模型,其中每个输出字都有对之前所有预测的限制。因此,一个问题是如何为NMT设计有意义的操作。
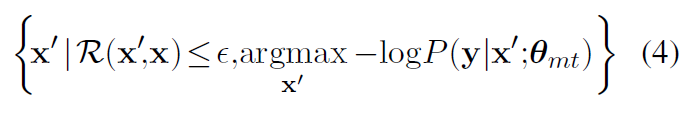
↓
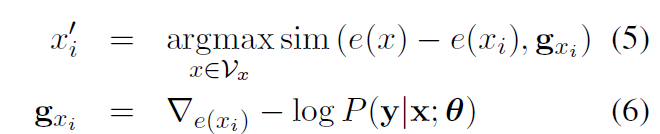
sim 相似度计算函数(向量的余弦距离);gxi 梯度;Vx源语言词典
![]()
Plm 双向语言模型;Q xi x 句子x中i-th词的似然函数;Vxi top_n < Vx

Dpos是位置{1,...,|x|}上的一个分布(抽取的对抗词)。
对于源函数,我们使用简单的均匀分布U。根据约束R,我们希望输出句与输入句之间不要有太大的偏离,从而只根据超参数改变其组成词的一小部分:![]()
DEFENSE
![]()
z是decoder的input
Qtrg是选择目标词候选集Vz的可能性。为了计算它,我们将NMT模型预测与语言模型相结合:
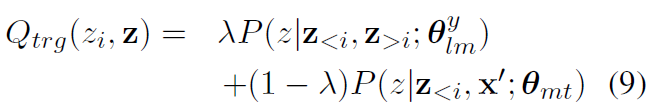
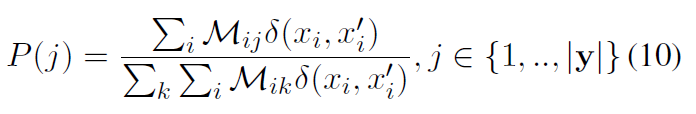
Mij 是attention的分数 目的是找最相似的词 后面那个是指示函数 不相等的时候=1
训练

对x’ 和 z' 调用ADVGEN两次。在更新参数时,我们没有将梯度反向传播到AdvGen上,只是起到了数据生成器的作用。在我们的实现中,与标准的Transformer模型相比,该函数最多产生20%的时间开销。
计算了S上的鲁棒性损失:
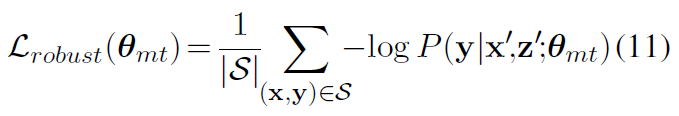
最后的训练目标中的L:
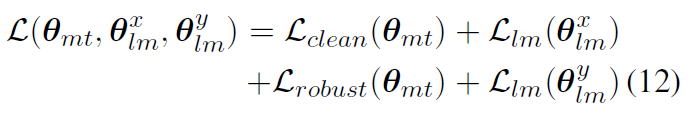
![]() :源和目标双向语言模型的参数
:源和目标双向语言模型的参数
![]() &
& ![]() 分别share word embeddings
分别share word embeddings
实验
我们对汉英和英德翻译任务进行了实验。汉英训练集来自最不发达国家语料库,包含120万对句子。我们使用NIST 2006数据集作为模型选择和超参数调优的验证集,并使用NIST 2002、2003、2004、2005、2008作为测试集。在英德翻译任务中,我们使用了由450万对句子组成的WMT 14语料库。验证集是newstest2013,测试集是newstest2014。
在这两个翻译任务中,我们合并了源和目标训练集,并使用字节对编码(BPE) (Sennrich et al., 2016c)通过子单词单元编码单词。构建了一个包含32K个子单词的英德共享词汇库,创建了包含60K个操作的汉英共享BPE代码,归纳出包含46K个中文子单词和30000个英文子单词的两个单词。我们报告了英语-德语的区分大小写标记的蓝色分数和汉语-的区分大小写标记的蓝色分数英语(Papineni et al., 2002)。为了进行公平的比较,我们没有对多个检查点进行平均(Vaswani et al., 2017),并且只在单一收敛模型上报告结果。
实验用的是双向Transformer模型 + a linaer layer to combine + a softmax layer to make predictions.
通过grid search来调整在验证集参数

我们将并行语料库的单个部分作为单语数据,在不引入额外数据的情况下训练双向语言模型。我们方法中的模型参数是从零开始训练的,除了语言模型中的参数是由在并行语料库的单个部分上预先训练的模型初始化的。在鲁棒性训练过程中,对语言模型的参数进行了更新。
主要结果

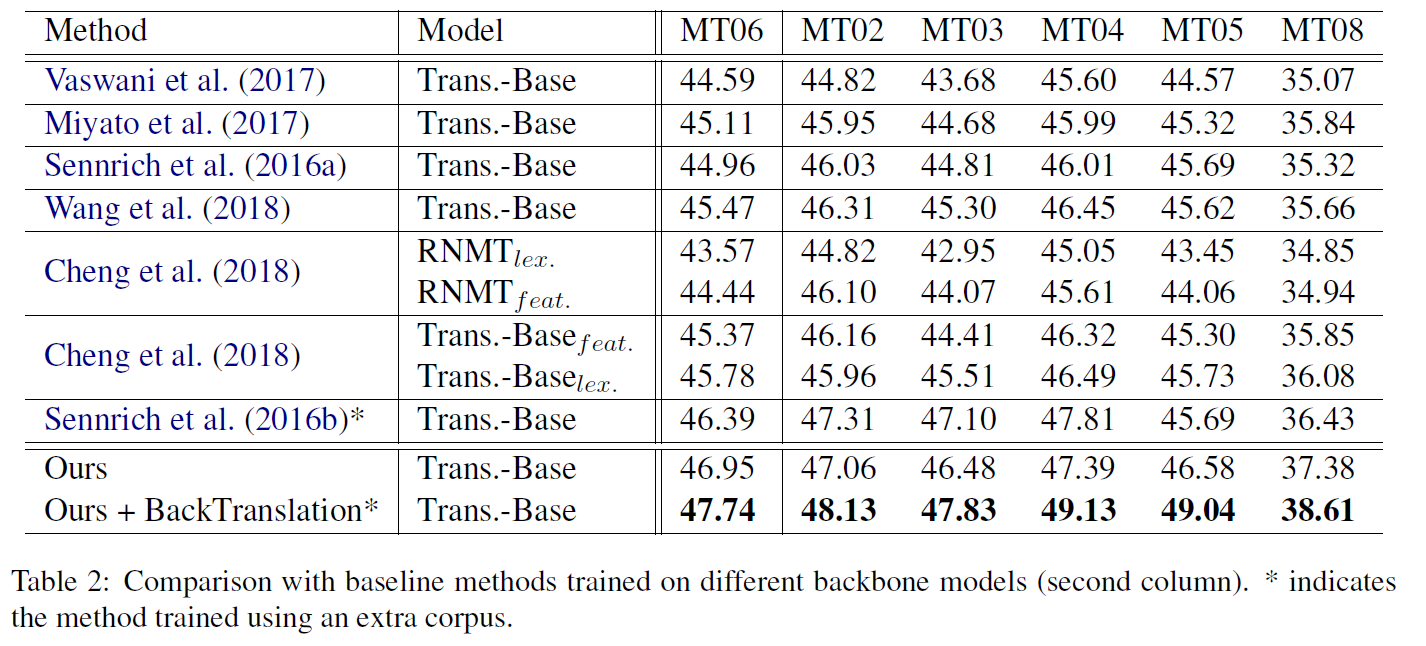
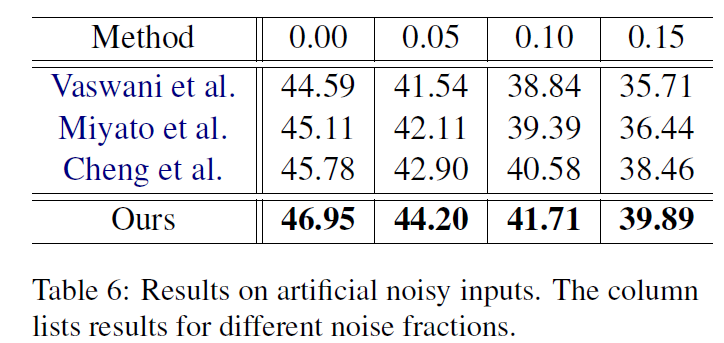
手动添加noisy data:
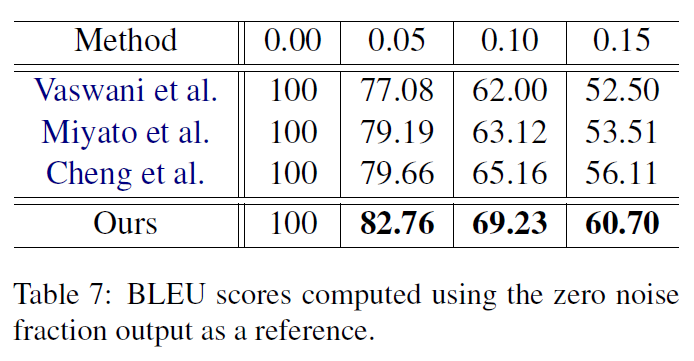
手动选出clean 样本的结果:

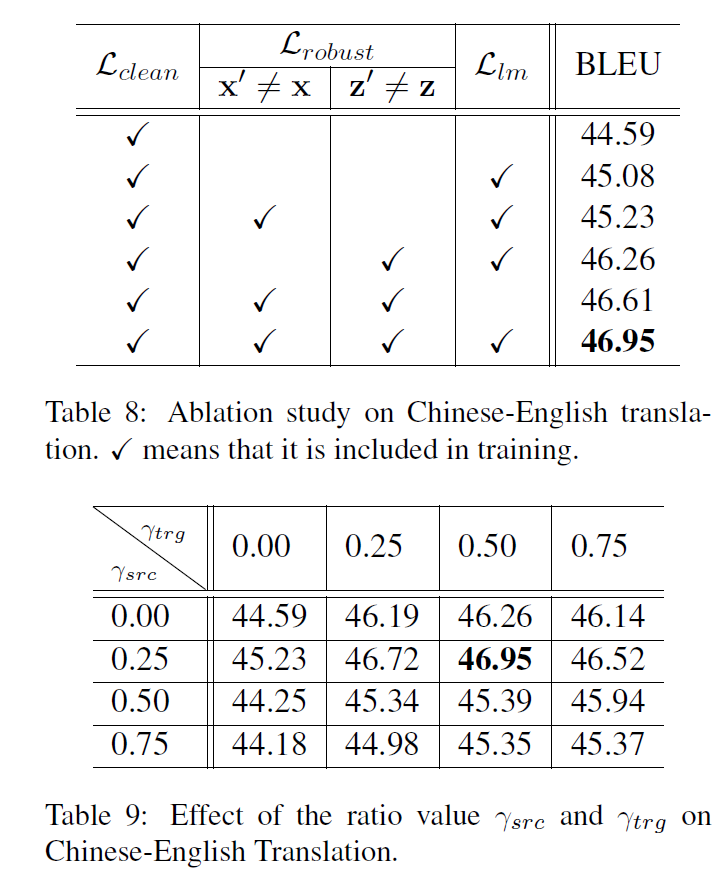
防御方法:curriculum learning?